Python数据挖掘基础(四):Pandas高级处理
目录1. 缺失值处理2. 数据离散化2.1 为什么要离散化?2.2 什么是数据的离散化?2.3 股票涨跌幅分组数据变成one-hot编码3. 合并4. 交叉表与透视表5. 分组与聚合
1. 缺失值处理
 原创文章 39获赞 701访问量 3万+
关注
私信
展开阅读全文
原创文章 39获赞 701访问量 3万+
关注
私信
展开阅读全文
作者:Amo Xiang
本文所使用到的所有数据在此处下载:
链接:https://pan.baidu.com/s/16ayvfRw95K0xma9o3YPN3Q 密码:qgt3
判断缺失值是否存在,示例代码如下:
import numpy as np
import pandas as pd
type(np.NAN) # float
# 读取电影数据
movie_data = pd.read_csv("./data/IMDB-Movie-Data.csv")
# 1.判断是否存在缺失值
np.any(pd.isnull(movie_data)) # 里面如果有一个缺失值,就返回True
# 2.判断缺失值是否存在
np.all(pd.notnull(movie_data)) # 里面如果有一个缺失值,就返回False
处理缺失值,示例代码如下:
# 处理缺失值
# 1.删除缺失值 pandas删除缺失值,使用dropna的前提是,缺失值的类型必须是np.nan
movie_data.dropna() # 不修改原数据
np.any(pd.isnull(movie_data)) # True
data = movie_data.dropna() # 可以使用一个新的变量接收它
np.any(pd.isnull(data)) # False
# 2.替换缺失值
# 不修改原有的数据 用平均值来进行代替
data2 = movie_data["Revenue (Millions)"].fillna(value=movie_data["Revenue (Millions)"].mean())
# 直接将原有的数据进行修改
# movie_data["Revenue (Millions)"].fillna(value=movie_data["Revenue (Millions)"].mean(), inplace=True)
data2
# 3.替换所有缺失值
for i in movie_data.columns:
# print(i)
if np.all(pd.notnull(movie_data[i])) == False:
# print(i)
# 替换
movie_data[i].fillna(value=movie_data[i].mean(), inplace=True)
np.any(pd.isnull(data))
不是缺失值 nan 的,而是有 ? 等默认标记的处理,示例代码如下:
# 有默认标记的处理
# 数据准备
wis = pd.read_csv("https://archive.ics.uci.edu/ml/machine-learning-databases/breast-cancer-wisconsin/breast-cancer-wisconsin.data")
# 1.先替换"?"为np.nan to_replace: 替换前的值 value: 替换后的值
wis = wis.replace(to_replace="?", value=np.nan)
# 2.在进行缺失值的处理
wis.dropna()
2. 数据离散化
2.1 为什么要离散化?
连续属性离散化的目的是为了简化数据结构,数据离散化技术可以用来减少给定连续属性值的个数。离散化方法经常作为数据挖掘的工具。
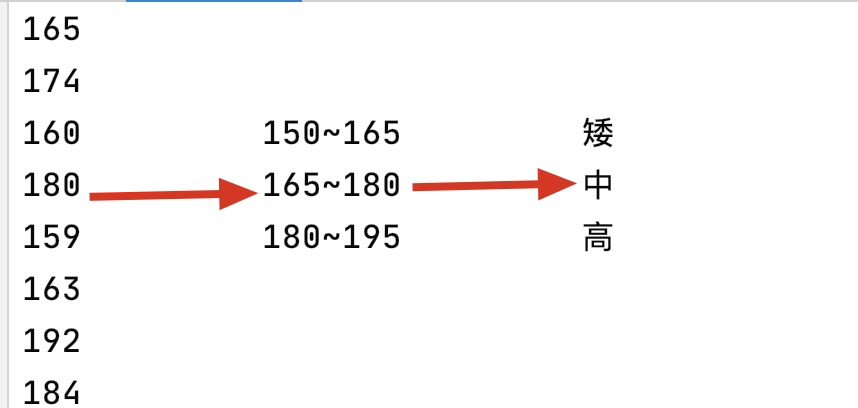
2.2 什么是数据的离散化?连续属性的离散化就是在连续属性的值域上,将值域划分为若干个离散的区间,最后用不同的符号或整数 值代表落在每个子区间中的属性值。离散化有很多种方法,这里使用一种最简单的方式去操作,如下:
原始人的身高数据:165,174,160,180,159,163,192,184 假设按照身高分几个区间段:150~165, 165~180,180~195
原创文章 39获赞 701访问量 3万+
关注
私信
展开阅读全文
作者:Amo Xiang