Python爬虫从入门到放弃 09 | Python爬虫实战–下载网易云音乐
此博客仅为我业余记录文章所用,发布到此,仅供网友阅读参考,如有侵权,请通知我,我会删掉。
本文章纯野生,无任何借鉴他人文章及抄袭等。坚持原创!!
你好。这里是Python爬虫从入门到放弃系列文章。我是SunriseCai。
本文章主要介绍利用爬虫程序调用API去 下载 网易云音乐的歌曲 。
1. 文章思路看看网易云音乐网站,如下多图所示:
首页(一级页面)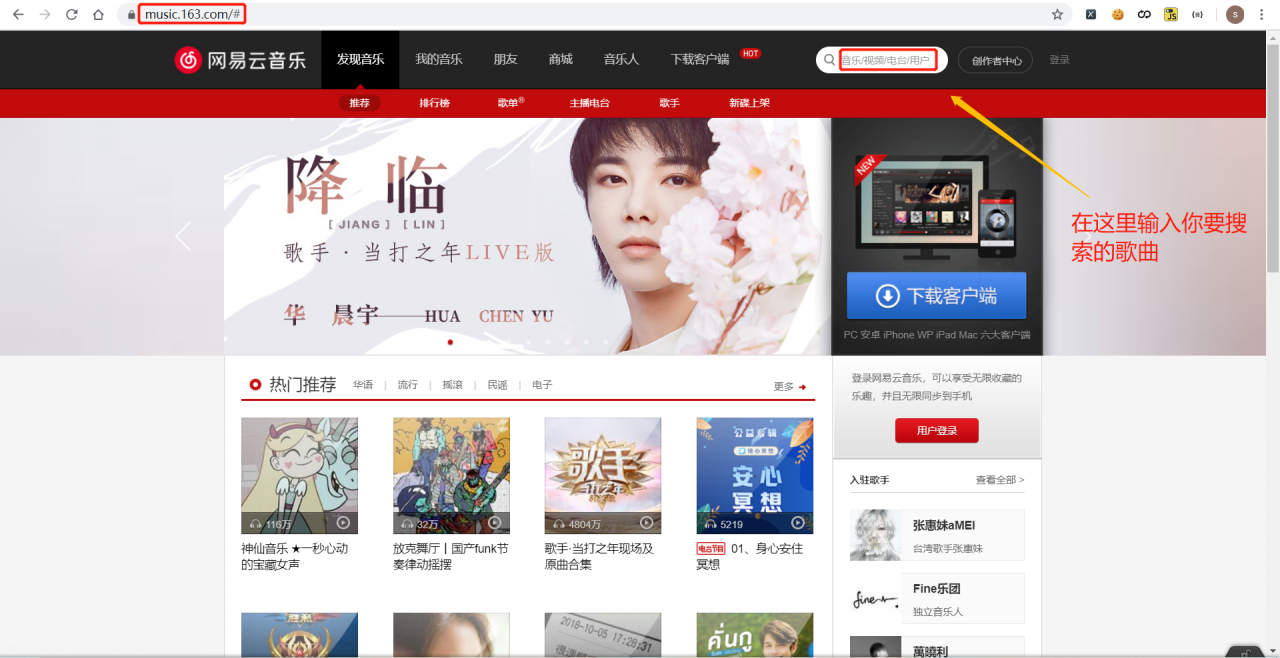 搜索页面(这里搜索 东方之珠)
然后点击第一首歌曲
搜索页面(这里搜索 东方之珠)
然后点击第一首歌曲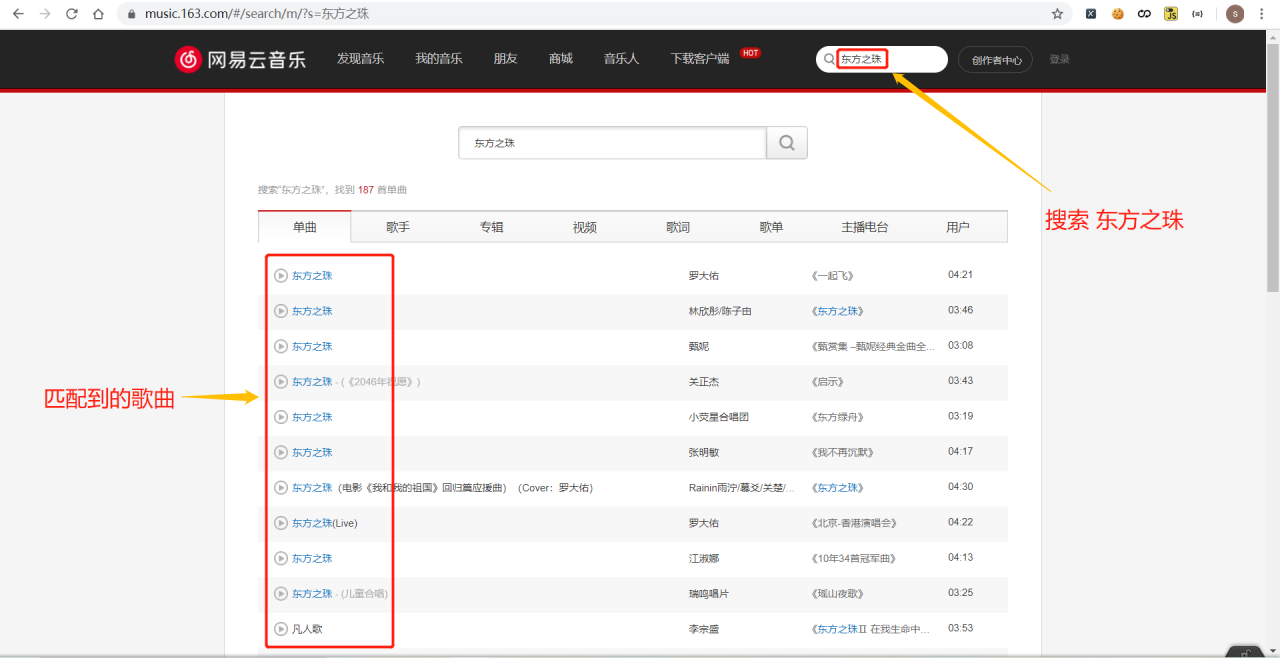 播放页面(注意链接里边有一个id,划重点!!!)
看到播放页面,捕捉到了多个m4a格式的数据包,不清楚m4a是什么没有关系,下面会介绍到它,这里先访问一波它的URL。
播放页面(注意链接里边有一个id,划重点!!!)
看到播放页面,捕捉到了多个m4a格式的数据包,不清楚m4a是什么没有关系,下面会介绍到它,这里先访问一波它的URL。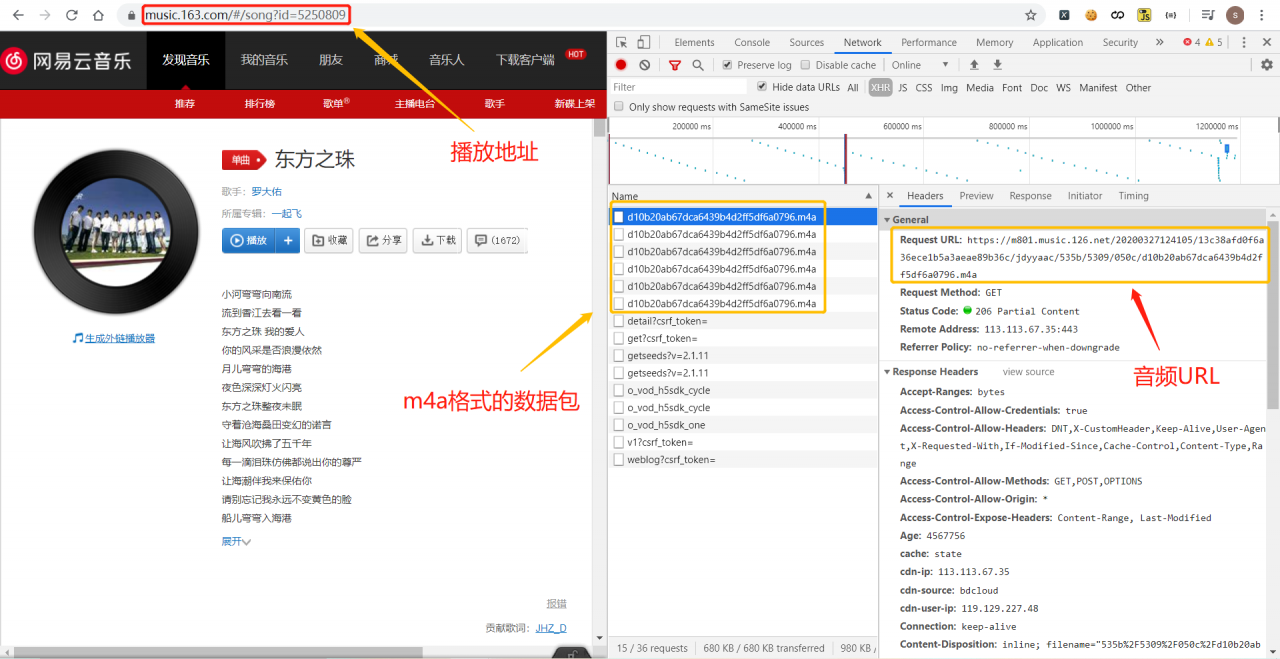 访问m4a的URL,来到下面的页面
该页面 是东方之珠 该歌曲的播放页面,同时也是下载页面。
访问m4a的URL,来到下面的页面
该页面 是东方之珠 该歌曲的播放页面,同时也是下载页面。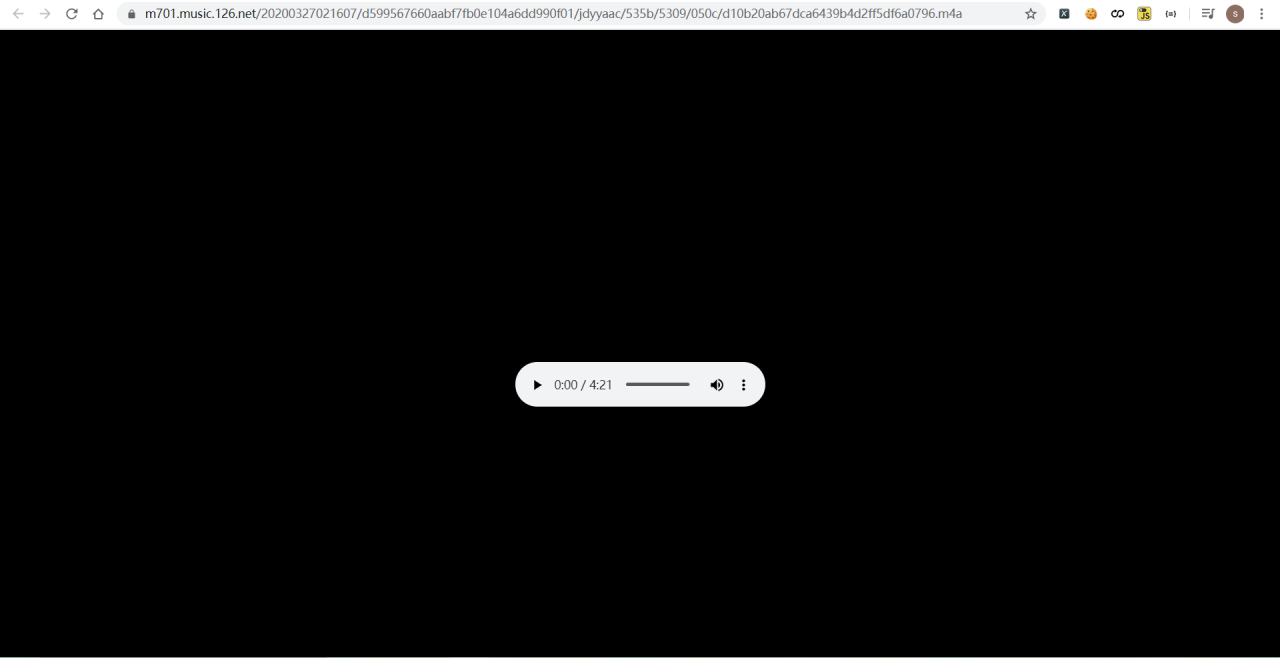
既然知道了是m4a数据包的URL可以下载歌曲,那接下来就是去分析URL了。
但是!!!这里咱们就不去分析URL,因为咱们这里定位的是入门,所以,简单就完事了。有更方便快捷的方法,是什么呢?请往下看。
百度百科释义上面提到的m4a。 2. 调用网易云音乐API
看看其他歌曲的播放页面。
这首Yellow也有对应的id。
2. 调用网易云音乐API
看看其他歌曲的播放页面。
这首Yellow也有对应的id。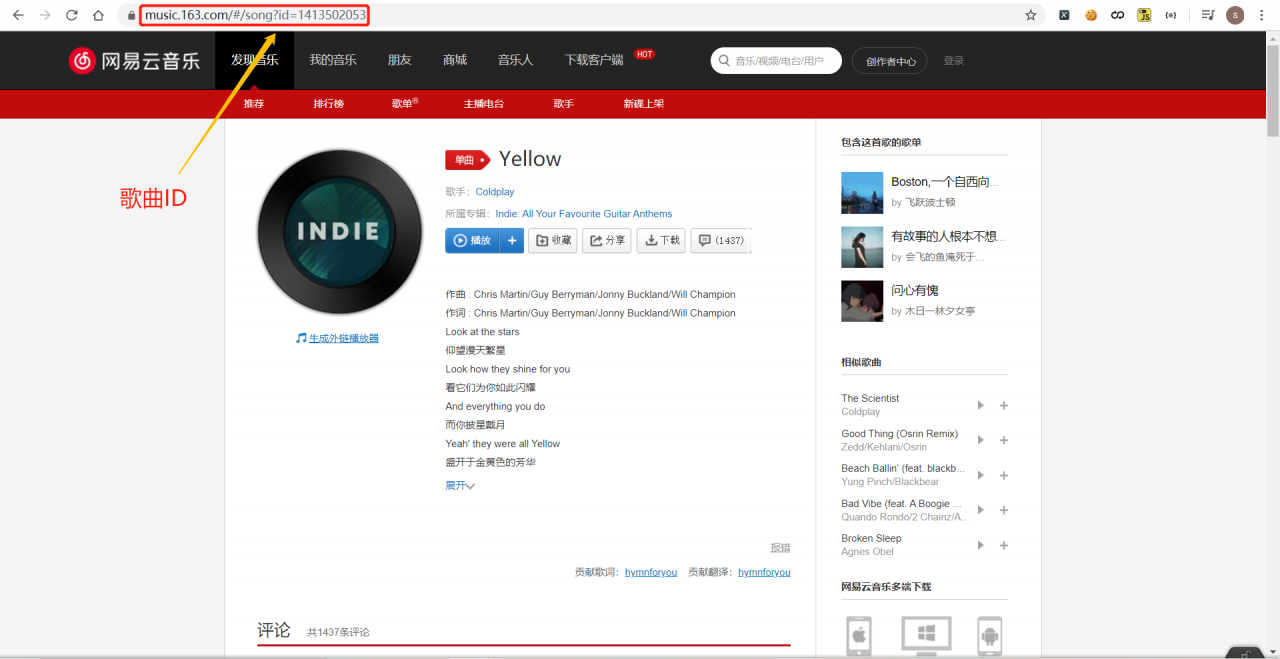
得知网易云音乐的歌曲都有着对应的id,很好,接下来看看如何利用这个id去下载对应的音乐。
这里网易云音乐API隆重登场。
http://music.163.com/song/media/outer/url?id=
API的使用很简单,只需要填入歌曲的id即可使用,先看示例:
下图是在API里边填入歌曲id,然后用浏览器访问的样子。
代码示例:
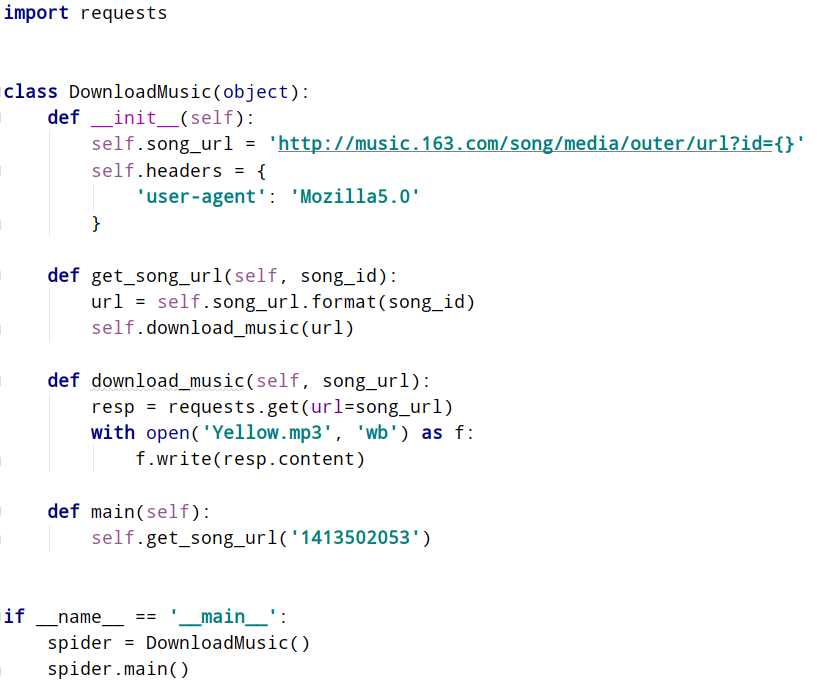
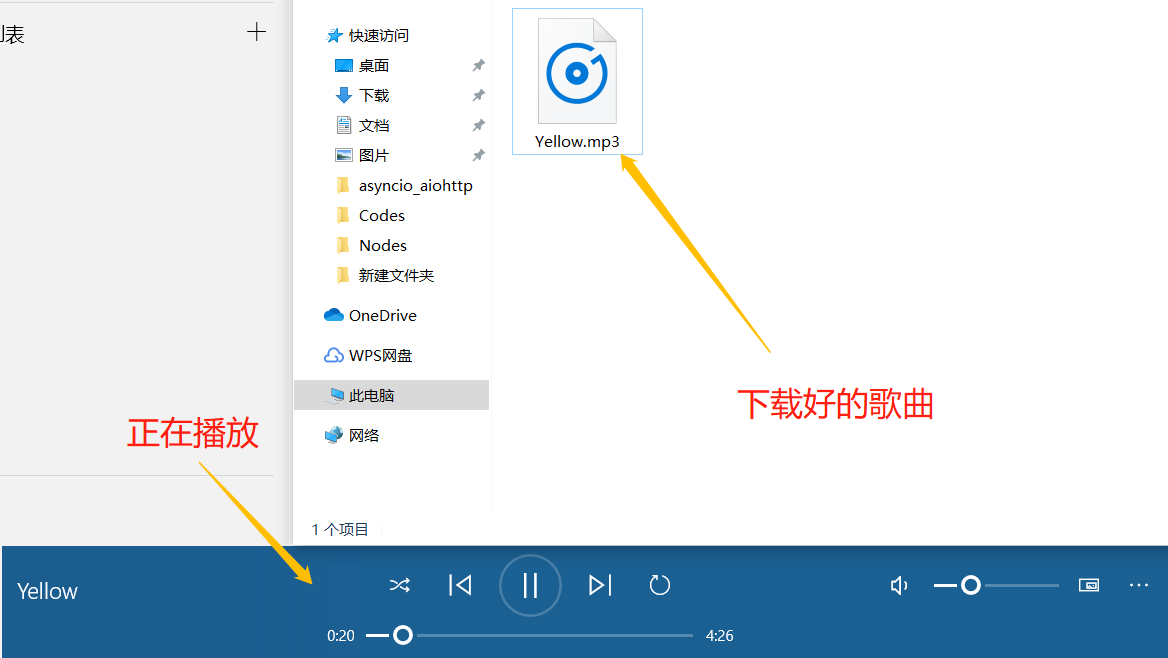
执行代码后的样子:
# -*- coding:utf-8 -*-
# author : SunriseCai
# datetime : 2020/3/27 17:08
# software : PyCharm
"""网易云音乐下载程序"""
import requests
class DownloadMusic(object):
def __init__(self):
self.song_url = 'http://music.163.com/song/media/outer/url?id={}'
self.headers = {
'user-agent': 'Mozilla5.0'
}
def get_song_url(self, song_id):
"""
传入歌曲id,拼凑完整URL,然后调用下载音乐函数
:param song_id: 歌曲id
:return:
"""
url = self.song_url.format(song_id)
self.download_music(url)
def download_music(self, song_url):
"""
接受歌曲URL,执行下载函数
:param song_url: 歌曲URL
:return:
"""
resp = requests.get(url=song_url)
with open('Yellow.mp3', 'wb') as f:
f.write(resp.content)
def main(self):
"""
主函数
:return:
"""
self.get_song_url('1413502053')
if __name__ == '__main__':
spider = DownloadMusic()
spider.main()
Github上大神的创建的音乐API项目 ,感兴趣的可以去了解。
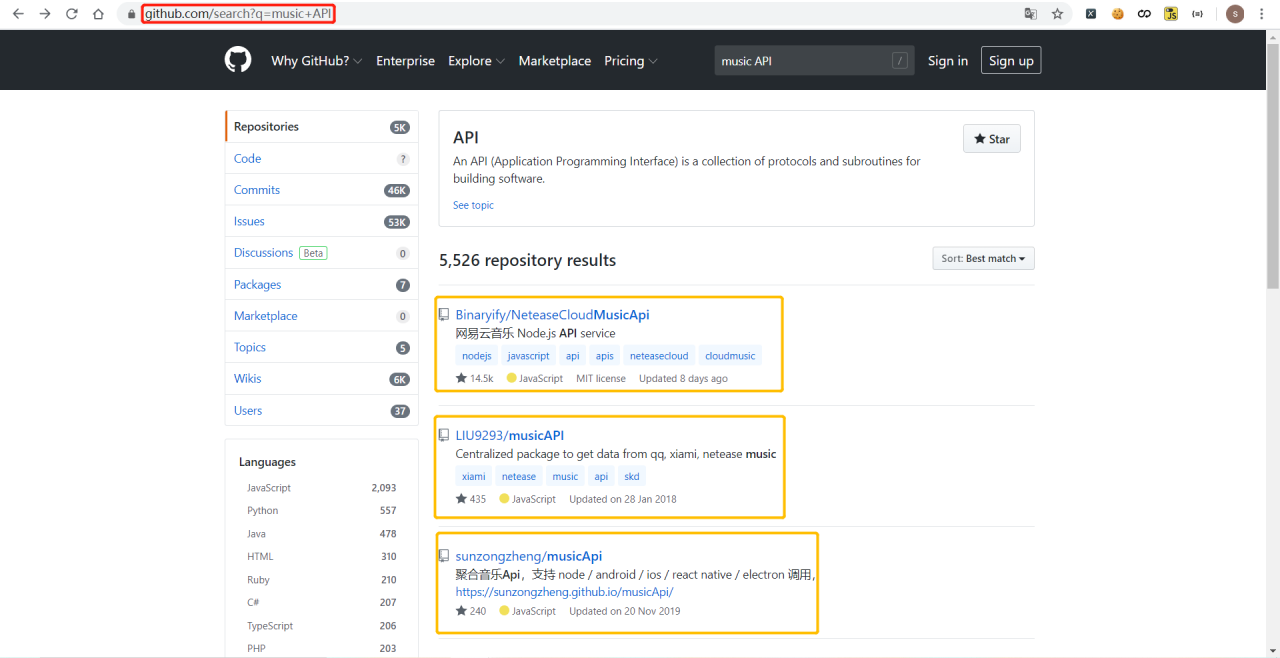
文章问题:
本篇文章很水,因为是入门,所以真的很水。就是水字数水文章数量的。为了凑数量而写。 建议各位通过复制黏贴代码去执行一番,有任何疑问请先自己动手解决,尽信书则不如无书 实在解决不了可以一起交流。待改进:
添加搜索歌曲的功能,自己动手,丰衣足食。 此处可参考https://blog.csdn.net/weixin_45081575/article/details/98184234,没错,也是我水的博文。最后来总结一下本章的内容:
介绍了调用API去下载网易云音乐的爬虫思路 代码展示 无
下一篇文章,名为 《Python爬虫从入门到放弃 10 | Python爬虫实战–下载bilibili在线列表视频》。
作者:SunriseCai