python爬虫学习笔记(三)—— 实战爬取豆瓣TOP250电影
基于之前两篇的基础知识后
python爬虫学习笔记(一)——初识爬虫
python爬虫学习笔记(二)——解析内容
开始实战爬取豆瓣TOP250电影
首先还是重新复习下爬虫的基本流程:
发起请求 获取响应内容 解析内容 保存数据 1. 发起请求首先观察豆瓣电影Top250首页
 (\s+)?', " ", bd)
bd = re.sub('/', " ", bd)
data.append(bd.strip()) # 添加相关内容
# 影片详情的链接的解析
findlink = re.compile(r'')
link = re.findall(findlink, item)[0]
data.append(link) # 添加链接
# 影片图片链接的解析
findimgsrc = re.compile(r'
(\s+)?', " ", bd)
bd = re.sub('/', " ", bd)
data.append(bd.strip()) # 添加相关内容
# 影片详情的链接的解析
findlink = re.compile(r'')
link = re.findall(findlink, item)[0]
data.append(link) # 添加链接
# 影片图片链接的解析
findimgsrc = re.compile(r'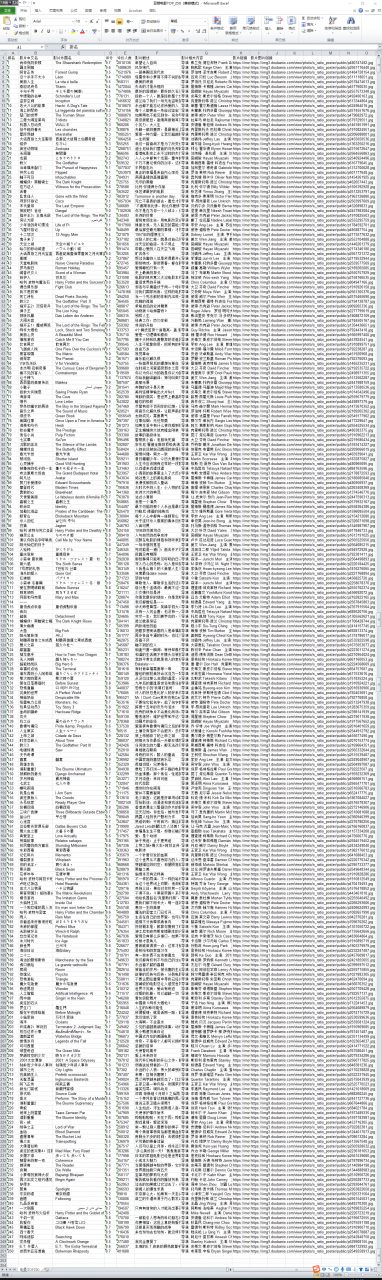 原创文章 5获赞 4访问量 279
关注
私信
展开阅读全文
原创文章 5获赞 4访问量 279
关注
私信
展开阅读全文
作者:浮生若code