Python爬虫实例(一)——爬取某点小说网《庆余年》
在网页上看小说,看不到小说的灵魂,因为它,并不属于我。
——节选自《野草》
大家好我是Henry!想必疫情期间大家在家里的网课效果都很不错吧!应该是不会有时间看小说的吧!

既然如此,今天给大家分享一下,如何用python在小说网站上爬取小说。
首先我们先看一下效果图。

怎么样是不是很酷炫鸭,那赶紧来学习吧~
一、准备工作在正式开始前,我们需要做一些准备工作!
1.下载python和IDE首先我们得下载好我们爬虫的工具——python,安装教程点击这里,然后下一个合适的IDE(集成开发环境),Henry用的是比较好用的PyCharm,安装教程点击这里。
2.了解什么叫爬虫。
网络爬虫(英语:web crawler),也叫网络蜘蛛(spider),是一种用来自动浏览万维网的网络机器人。其目的一般为编纂网络索引。[摘自维基百科]
说得通俗一点,就是将网站上的一些数据下载下来,就像蜘蛛一样,顺着网线白嫖别人的东西。因此,网络爬虫也是有一定规范的,详见《网络爬虫的法律规制》

在正式去爬取小说前,我们得先学习一项技能——审查元素。
在浏览器上任意输入一个地址(URL),在网页的空白处单击右键,点击检查(在chrome和360浏览器上叫检查,在Microsoft Edge上叫检查元素)或者按键盘上方的F12,进入开发者模式。
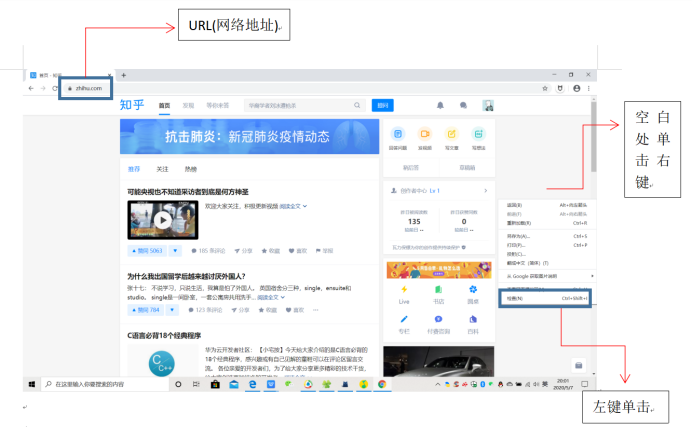
进入开发者模式后,能看到这样的界面
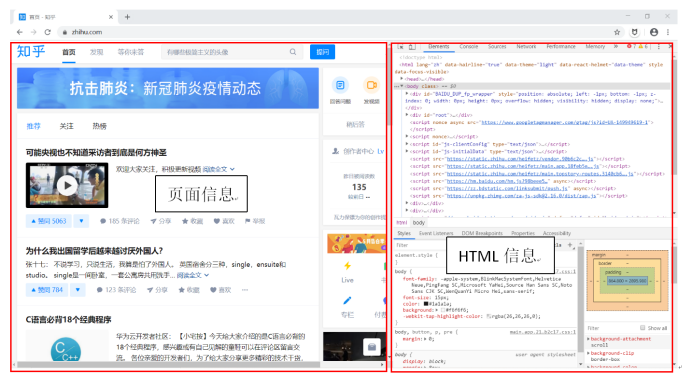
左侧是我们常见的页面信息,而右侧是一些密密麻麻的代码。这些代码叫做HTML(超文本标记语言)。那么HTML是什么呢?有什么用?打个比方,就像生物的基因决定了人的性状,HTML就决定了网页的样子。HTML中的代码就可以说是网页的密码子。
往往在网页上不能实现的操作,我们可以进入开发者模式,对HTML进行操作,比如在某点小说网界面,我们并不能进行复制操作,但我们可以去复制他的HTML内容。

所以,爬虫就是通过URL进入对应网站的HTML页面,将我们需要的版块提取出来。那我们正式开始吧!
三、爬取某点网站上《庆余年》小说
1.首先我们需要一个抓取HTML网页的“武器”——get函数,直接就可以翻译成抓取、获得,这个函数在python第三方库requests里,需要我们自行下载。
进入cmd窗口,输入以下代码
pip install requests
即可下载。
2.我们在PyCharm输入如下代码。
import requests
if __name__ == ‘__main__’:
url = ‘https://read.qidian.com/chapter/kpwCq4fKJk01/LGKHGy9k73Q1’;
req = requests.get(url)
print(req.text)
得到如下的结果
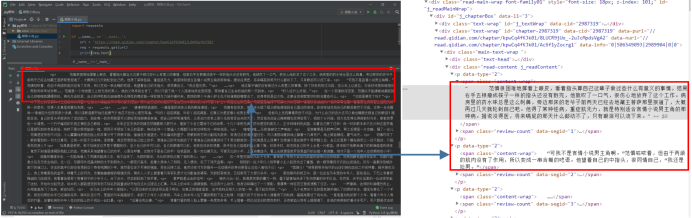
是的!我们得到了刚刚网站上的HTML信息,不由得为自己鼓掌!
但是先别高兴得太早了,这里面得到了所有的HTML代码信息,而我们只需要HTML中小说的内容,其他的我们都不需要鸭。
我们继续回到网站开发者模式,找一找文章内容在哪儿。
然后有了一个惊奇的发现,所有的文本内容都放在一个标签下。

所以,要是我们在提取HTML代码时,加一个限定条件,是不是就可以将其他不要的信息过滤掉,只要我们需要的呢?
3.这时候我们需要另外一个帮手——BeautifulSoap。BeautifulSoap现在在bs4库里面,我们还是需要像刚刚那样安装requests库一样,安装bs4.
pip install bs4
安装结束后,我们回到Pycharm代码区,开始我们的“过滤”。
输入如下代码
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
url = 'https://read.qidian.com/chapter/kpwCq4fKJk01/LGKHGy9k73Q1'
req = requests.get(url)
text = req.text
bf = BeautifulSoup(text)
texts = bf.find_all('div',class_="read-content j_readContent")
print(texts)
稍微解释一下,find_all函数的作用就是将HTML文本中的指定部分单独拿出来,这里我们要求它拿出‘div’标签下,class属性为"read-content j_readContent"的部分。
运行后出现了这样的结果:
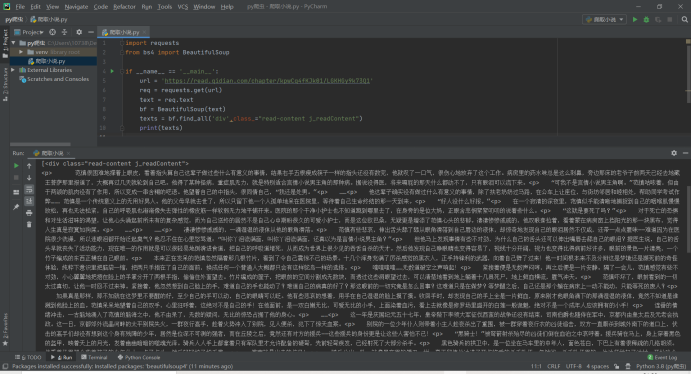
这一次,只输出了小说的文本内容!但还是有一点美中不足的地方,就是有一些
标签,看起来不舒服,那让我们把它也删掉吧.。
将输出改成如下代码
print(texts[0].text)
然后输出以下内容
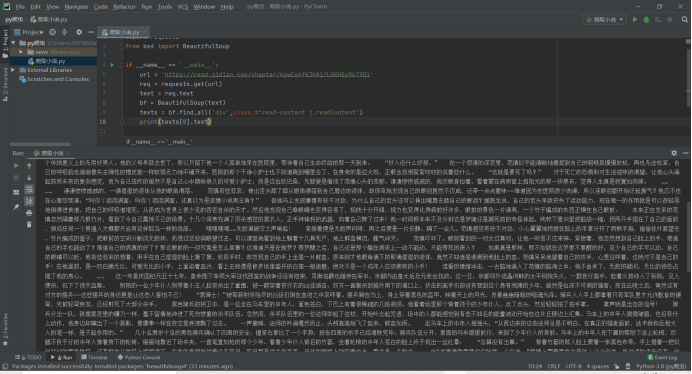
是不是要舒服很多呢!
4.好滴,现在我们已经成功的把第一章内容输出出来了,其他的章节也是如是做,但我们需要批量获得其他章节的URL(网络地址)。所以我们点进了小说目录的网页,进入开发者模式,发现每一个目录下都有一个链接,即每个章节的URL,并且注意到一个细节,所有的URL都保存在一个叫做a herf的标签下
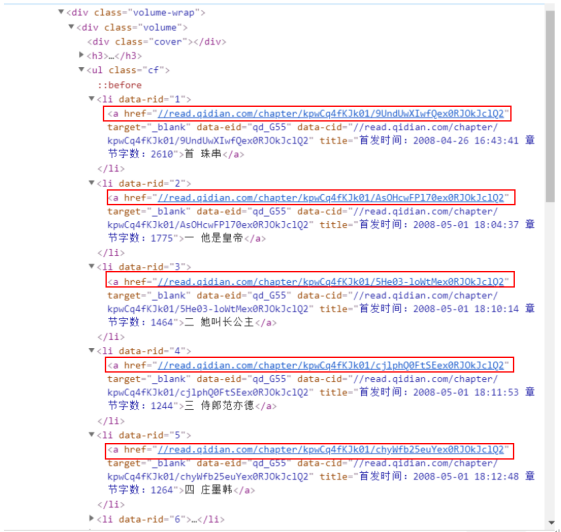
现在我们输入一段代码,来获得每个章节的URL。
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
url = 'https://book.qidian.com/info/114559#Catalog'
req = requests.get(url)
text = req.text
bf = BeautifulSoup(text)
div_bf = bf.find_all('div',class_="volume")
print(div_bf[0])
a_bf = BeautifulSoup(str(div_bf[0]))
a = a_bf.find_all('a')
for each in a:
print(each.get('href'))
这里和上述获得链接的方法一致,先找到所有的a标签,再把每个a中的href提取出来保存到each里面。输出的结果如下
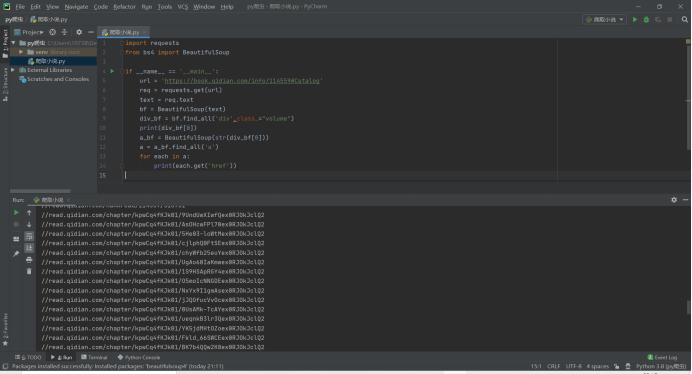
这样就获得了每个章节的URL了,就可以顺着URL爬取每一个章节了!
5.现在我们来整合代码,将“获得URL”,“顺着URL爬取小说内容”,“输出到文件”分别写成函数,然后统一实现,下面就是全代码
from bs4 import BeautifulSoup
import requests, sys
class downloader(object):
def __init__(self):
self.server = 'https:'
self.target = 'https://book.qidian.com/info/114559#Catalog/'
self.urls = []
self.nums = 0
def get_download_url(self):
req = requests.get(self.target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = "volume")
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
self.nums = len(a)
for each in a:
self.urls.append(self.server+each.get('href'))
def get_contents(self, target):
req = requests.get(target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = "read-content j_readContent")
texts = texts[0].text
return texts
def writer(self, path, text):
write_flag = True
with open(path, 'a', encoding='utf-8') as f:
f.writelines(text)
f.write('\n\n')
if __name__ == "__main__":
dl = downloader()
dl.get_download_url()
print('《庆余年》开始下载')
print(dl.nums)
for i in range(dl.nums):
dl.writer('庆余年.txt', dl.get_contents(dl.urls[i]))
sys.stdout.flush()
print('《庆余年》下载完成')
三、总结
是不是很有趣呢?赶快拿起身边的电脑开始吧!
我是Henry,我们下期再见!
欢迎大家关注我的微信公众号:今天我秃了吗

欢迎大家关注我的知乎账号:HenryLau

 HenryLau7
HenryLau7
 原创文章 2获赞 5访问量 344
关注
私信
展开阅读全文
原创文章 2获赞 5访问量 344
关注
私信
展开阅读全文
作者:HenryLau7