Python爬虫之Scrapy(爬取csdn博客)
本博客介绍使用Scrapy爬取博客数据(标题,时间,链接,内容简介)。首先简要介绍Scrapy使用,scrapy安装自行百度安装。
创建爬虫项目安装好scrapy之后,首先新建项目文件:scrapy startproject csdnSpider
创建项目之后会在相应的文件夹位置创建文件:
首先编写爬虫模块,爬虫模块的代码都放置于spiders文件夹中 。 爬虫模块是用于从单个网站或者多个网站爬取数据的类,其应该包含初始 页面的URL, 以及跟进网页链接、分析页 面内容和提取数据函数。 创建一个Spider类,需要继承scrapy.Spider类,并且定义以下三个属性:
1) name: 用于区别Spider。该名宇必须是唯一的,不能为不同的Spider设定相同的名字。
2) start_urls: 它是Spider在启动时进行爬取的入口URL列表。 因此,第一个被获取到 的页面的URL将是其中之 一 ,后续的URL则从初始的URL的响应中主动提取 。
3) parse(): 它是Spider的一个方法。 被调用时,每个初始 URL 响应后返回的Response对象,将会作为唯 的参数传递给该方法。该方法负责解析返回的数据(response data)、 提取数据(生成item)以及生成需要进一步处理的URL的Request对象。
现在创建CsdnSpider类,该类位于spiders下的csdn_spider.py中
#coding:utf-8
import scrapy
from ..items import CsdnspiderItem
class CsdnSpider(scrapy.Spider):
name = "csdnblogs"
allowed_domains = ["csdn.net"]#允许的域名
start_urls = [
"https://blog.csdn.net/qq_16669583/article/list/1",
"https://blog.csdn.net/qq_16669583/article/list/2",
"https://blog.csdn.net/qq_16669583/article/list/3"
]
def parse(self, response):
#实现网页的解析
#首先抽取所有的文章
papers = response.xpath(".//*[@id='mainBox']/main/div[2]/div")
#从每篇文章种提取数据
for paper in papers:
try:
title = paper.xpath("./h4/a/text()").extract()[1]
url = paper.xpath("./h4/a/@href").extract()[0]
time = paper.xpath("./div[1]/p/span[1]/text()").extract()[0]
content = paper.xpath("./p/a/text()").extract()[0]
print(url, title, time, content)
except Exception:
print('数据格式不对')
continue
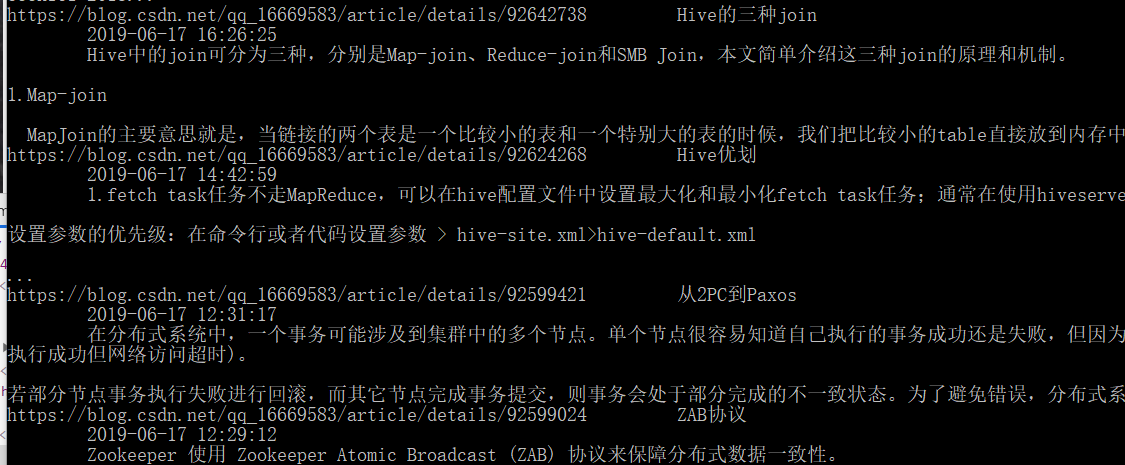
在爬虫的根目录运行:scrapy crawl csdnblogs结果如下:
在上溯的爬虫模块中需要自己根据网页的结构定义相应的xpth,在这里介绍本人最常用的获取xpath方法。
获取目标内容的xpath
scrapy本身提供了shell命令行给我们来调试,具体使用如下:
在一个新的命令行窗口输入:scrapy shell "https://blog.csdn.net/qq_16669583/article/list/2",结果如下:
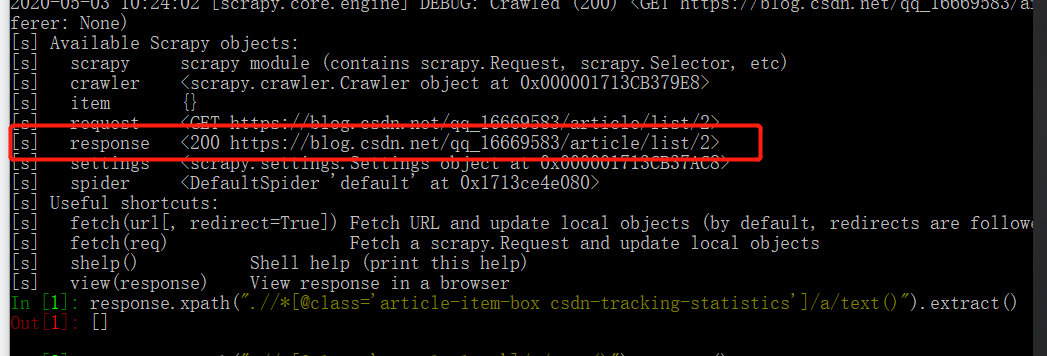
我们可以使用上图中的response对象来对网页进行操作。例如我们获取一个博客的标题:

对于每个目标内容我们可以根据其页面结构来构造xpath,最简单的就是通过谷歌浏览器的调试功能。
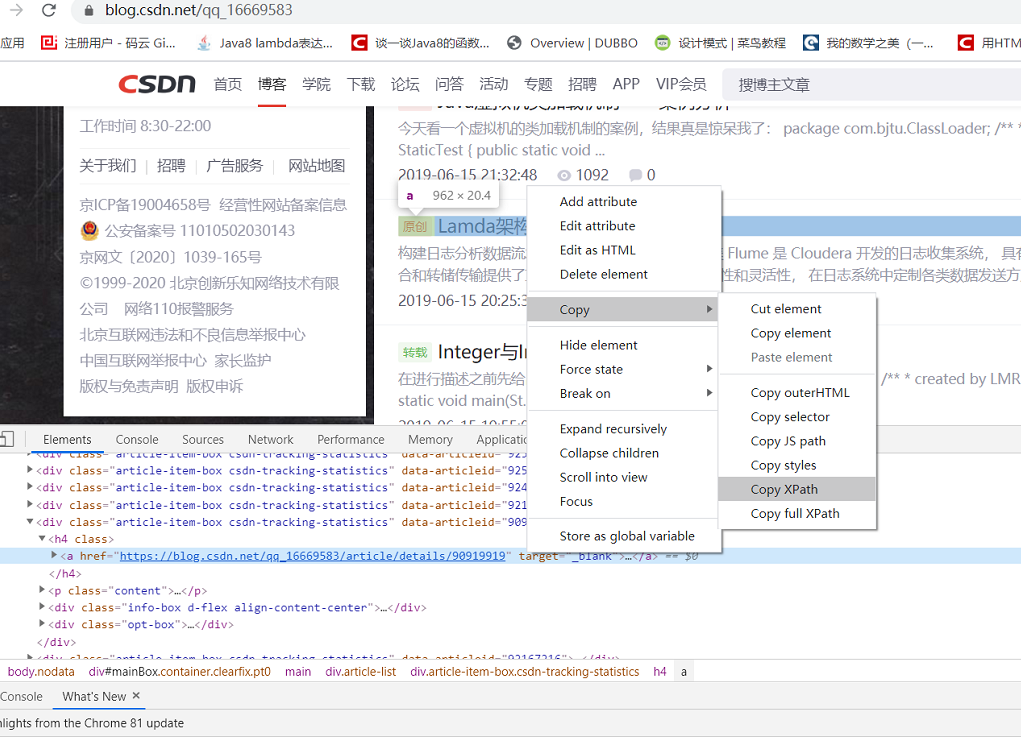
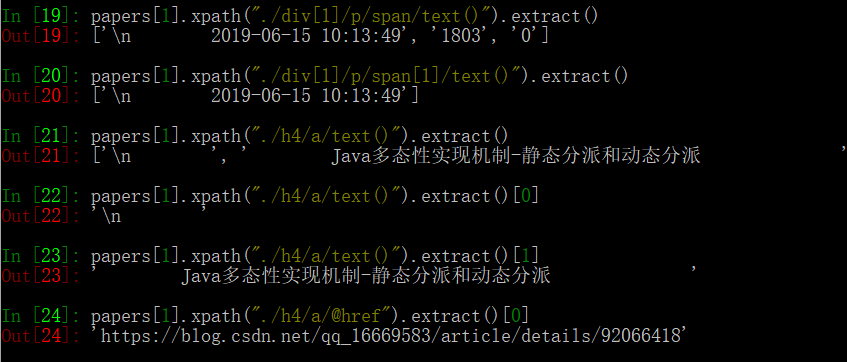
通过这个方式可以获取任意内容的xpath路径,我们只用对改xpath进行简单的修改即可使用。但是由于一些网站是动态加载,在谷歌浏览器上调试获取的内容在程序中不一定能获取的到,所以需要不断的进行调试。下面是获取几个内容的xpath调试结果。
定义Item和构建Item PipeLine
在上面的操作中仅仅是将爬取的内容输出在控制台中,在大部分的实际应用中需要我们对齐进行存储。首先我们需要对获取的数据进行封装,将每条数据封装为一个Item,在程序目录中的items.py文件中如下所示:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
url = scrapy.Field()
time = scrapy.Field()
title = scrapy.Field()
content = scrapy.Field()
pass
对于爬取的数据,我们需要定义其传输管道,即Item PipeItem,在这里只是简单的存储在文件中,在pipelines.py文件中:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import json
from scrapy.exceptions import DropItem
class CsdnspiderPipeline(object):
def __init__(self):
self.file = open('parser.json', 'wb')
def process_item(self, item, spider):
if item['title']:
line = json.dumps(dict(item)) + "\n"
print("输出数据",line)
self.file.write(line.encode())
return item
else:
raise DropItem('Miss title')
定义完Item和Item pipeline之后需要激活该管道,在setting.py配置文件中配置:
ITEM_PIPELINES = {
'csdnSpider.pipelines.CsdnspiderPipeline': 300,
}
运行爬虫
同样在爬虫根目录运行:scrapy crawl csdnblogs:
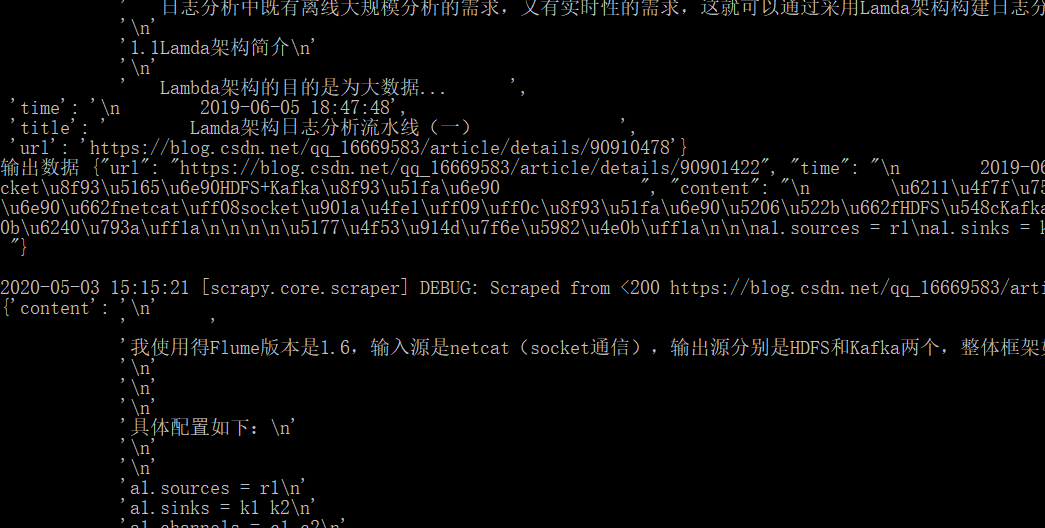
查看json文件:

由于爬取的数据格式比较乱,没有调整,所以显示比较差,这个只能后续慢慢调整
 LMRzero
LMRzero
 原创文章 93获赞 118访问量 35万+
关注
私信
展开阅读全文
原创文章 93获赞 118访问量 35万+
关注
私信
展开阅读全文
作者:LMRzero