Selenium WebDriver学习小结——python爬虫爬取学习通课程资源
疫情期间在家用学习通上网课,苦于没办法下载课程的视频资源和讲义,就想自己搞个爬虫玩一玩。 首先通过知乎搜索到可以查询资源的objectid,然后在浏览器中输入http://d0.ananas.chaoxing.com/download/“objectid” 即可下载(需要提前在浏览器登陆一次,记住你的账号密码): https://www.zhihu.com/question/320181398/answer/1025646045
代码主要参考了 @cici_vivi的 https://blog.csdn.net/zc666ying/article/details/104716273
准备工作anaconda + selenium库+webdriver, 如何安装selenium库和webdriver请自行搜索,我用的anaconda, python3.7, pip selenium SSL时一直报错,重新安装了open SSL 就好了。
代码 1 打开学习通并登录 1.1 进入学校选择页面作者需要通过学校账户才能登陆学习通,所以在打开网页之后首先要选择单位。通过开发者页面可以找到选择单位元素的id:

通过find_element_by_xpath, 可点击选择单位,进入学校选择界面。
代码如下:
#声明浏览器,初始化浏览器
driver = webdriver.Chrome()
#打开学习通网页
driver.get('http://passport2.chaoxing.com/login?fid=&refer=http://i.mooc.chaoxing.com')
time.sleep(1)
#进入学校选择界面(需要使用学校账户登陆)
links = driver.find_element_by_xpath('//a[@id="selectSchoolA"]')
links.click()
1.2 输入学校名称并搜索
此处应该有更简单方便的方法,笔者对网页开发了解有限,就选择了傻瓜式操作,手动输入学校名称并搜索。单位搜索元素如下图。


代码:
school='your school'
input_school=driver.find_element_by_id('searchSchool1')
input_school.send_keys(school)
search=driver.find_element_by_class_name('zw_t_btn')
search.click()
time.sleep(3)
links_school=driver.find_element_by_link_text(school)
links_school.click()
1.3 登陆
此处代码是用的@cici_vivi的 https://blog.csdn.net/zc666ying/article/details/104716273
不在这赘述啦,自己看去~
#name = input('请输入账号:')
#password = input('请输入密码:')
yanzhengma = input('请输入验证码:')#验证码需手动输入,其实可以通过验证码识别的库自动的识别,嫌麻烦没搞,自己打吧哈哈
name='你的ID'
password='你的密码'
#找到登陆输入框
input_name = driver.find_element_by_id('unameId')
input_password = driver.find_element_by_id('passwordId')
input_yanzheng = driver.find_element_by_id('numcode')
#向登陆输入框中输入值
input_name.send_keys(name)
input_password.send_keys(password)
input_yanzheng.send_keys(yanzhengma)
time.sleep(1)
#找到登陆按钮
button = driver.find_element_by_class_name('zl_btn_right')
#模拟点击
button.click()
2 选择课程
找到选择课程的元素,点击课程:
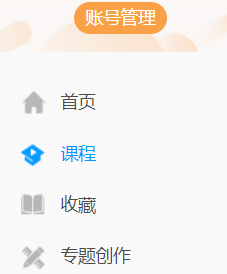
右侧刷新成课程页面:

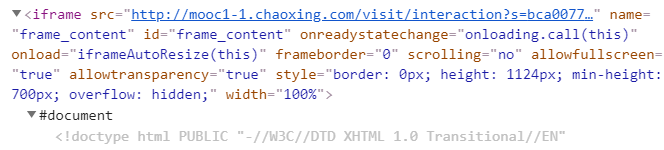
注:此时发现右侧的页面是写在iframe里的,如果直接用driver.find_element_by 找不到元素,所以要先通过iframe 的 id switch_to.frame()进入iframe里.
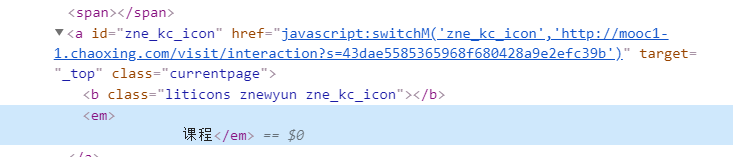
通过课程名称找到元素:
代码:
link=driver.find_element_by_id('zne_kc_icon')
link.click() #点击左侧的课程
time.sleep(2)
driver.switch_to.frame('frame_content')#网页里应用的iframe,要先switch到iframe里,否则搜索不到课程标题
time.sleep(2)
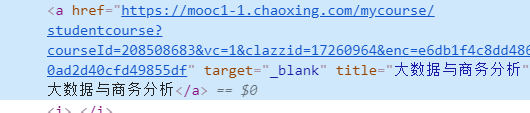
herf=driver.find_element_by_link_text('大数据与商务分析')#通过课程名称找到元素
herf.click()#点击课程名称进入课程
time.sleep(1)
driver.switch_to.window(driver.window_handles[1])#切换到课程界面
3 遍历课程章节,保存资源objectid
课程界面初始化如下,需要点击左侧标题才能进入章节,查询到objectid

发现进入章节的链接中都带有chapterId

笔者选择了通过 driver.find_elements_by_xpath("//*[@href]")找到页面中所有的href。
然后通过if 'chapterId' in link.get_attribute('href'):来判断是否需要点击进入页面来实现遍历。
如过herf中包含chapterId, 将该章节的名称和链接存入一个dataframe中,点击进入该章节,此时想获取视频或者slides的 objectid需要再次switch to iframe(id=iframe)

接下来要寻找的资源objectid又嵌套在另一个iframe里,给笔者带来了很大困难。由于objectid被包含在此iframe的头里,如果再次通过class name switch到iframe中就查找不到包含在头里的objectid了, 折腾了半天也没搞定,于是简单粗暴地把当前iframe里的html打印了出来并按空格split,用正则模糊匹配来查找‘objectid=’.,截取objectid字段,存入dataframe中

代码:
urls=pd.DataFrame(columns=['course_url','title'])#dataframe to record chapter URLs
downloads=pd.DataFrame(columns=['title','url'])#dataframe to record resourse download URLs
fix='d0.ananas.chaoxing.com/download/'#fix download link
all_href=len(driver.find_elements_by_xpath("//*[@href]"))
for num in range(all_href): #traverse all links
link=driver.find_elements_by_xpath("//*[@href]")[num]
if 'chapterId' in link.get_attribute('href'):#find links of chapters
title=link.text
new=pd.DataFrame({'course_url':link.get_attribute('href'),
'title':title
},index=[0])#record into dataframe
urls=urls.append(new,ignore_index=True)
link.click()#click the chapter
time.sleep(1)
driver.switch_to.frame('iframe')#switch into iframe by tag
time.sleep(1)
html=driver.page_source.split()#record html page split by space
for word in html:#find objectid
if re.findall('^objectid=',word):
objectid=word.split('"')[1]
new_downloads=pd.DataFrame({'title':title,
'url':fix+objectid,
},index=[0])#record in dataframe
downloads=downloads.append(new_downloads,ignore_index=True)
driver.back()#go back to chaper selecting page
downloads.to_excel('dowloads.xlsx',index=True)
urls.to_excel('course_url.xlsx',index=True)
接下来就可以打开爬下来的下载资源的链接了。当然也可以再加点代码自动下载,但我怕资源太多小破电脑受不了。
4 完整代码:# -*- coding: utf-8 -*-
"""
Created on Thu Apr 23 00:32:49 2020
@author: sirius
"""
from selenium import webdriver
import time
import pandas as pd
import re
#声明浏览器,初始化浏览器
driver = webdriver.Chrome()
#打开相应的网页
driver.get('http://passport2.chaoxing.com/login?fid=&refer=http://i.mooc.chaoxing.com')
time.sleep(1)
#进入学校选择界面(需要使用学校账户登陆)
links = driver.find_element_by_xpath('//a[@id="selectSchoolA"]')
links.click()
#school=input('请输入学校名称:')
school='your school'
input_school=driver.find_element_by_id('searchSchool1')
input_school.send_keys(school)
search=driver.find_element_by_class_name('zw_t_btn')
search.click()
time.sleep(3)
links_school=driver.find_element_by_link_text(school)
links_school.click()
#name = input('请输入账号:')
#password = input('请输入密码:')
yanzhengma = input('请输入验证码:')
name='your ID'
password='your password'
#找到登陆输入框
input_name = driver.find_element_by_id('unameId')
input_password = driver.find_element_by_id('passwordId')
input_yanzheng = driver.find_element_by_id('numcode')
#向登陆输入框中输入值
input_name.send_keys(name)
input_password.send_keys(password)
input_yanzheng.send_keys(yanzhengma)
time.sleep(1)
#找到登陆按钮
button = driver.find_element_by_class_name('zl_btn_right')
#模拟点击
button.click()
time.sleep(1)
link=driver.find_element_by_id('zne_kc_icon')
link.click()
time.sleep(2)
driver.switch_to.frame('frame_content')
time.sleep(2)
herf=driver.find_element_by_link_text('大数据与商务分析')
herf.click()
time.sleep(1)
driver.switch_to.window(driver.window_handles[1])
urls=pd.DataFrame(columns=['course_url','title'])#new dataframe to record URLs
downloads=pd.DataFrame(columns=['title','url'])
fix='d0.ananas.chaoxing.com/download/'
all_href=len(driver.find_elements_by_xpath("//*[@href]"))
for num in range(all_href): #keep in same page
link=driver.find_elements_by_xpath("//*[@href]")[num]
if 'chapterId' in link.get_attribute('href'):
title=link.text
new=pd.DataFrame({'course_url':link.get_attribute('href'),
'title':title
},index=[0])
urls=urls.append(new,ignore_index=True)
link.click()
time.sleep(1)
driver.switch_to.frame('iframe')
time.sleep(1)
html=driver.page_source.split()
for word in html:
if re.findall('^objectid=',word):
objectid=word.split('"')[1]
new_downloads=pd.DataFrame({'title':title,
'url':fix+objectid,
},index=[0])
downloads=downloads.append(new_downloads,ignore_index=True)
driver.back()
downloads.to_excel('dowloads.xlsx',index=True)
urls.to_excel('course_url.xlsx',index=True)
总结
selenium webdriver真的好好用,操作简单粗暴适合新手。笔者第一次写爬虫,主要是为了练习, 玩一玩,可能走了些弯路,仅供参考。
作者:帅秋秋