Python爬虫 爬取懒加载页面(以站长素材为例)
我就简单的说一下。当你去访问一个页面的时候,这个页面可能会有很多的信息,比如淘宝,京东之类的。如果你一次性完整的加载出这个页面。显然耗时长一点,并且对于用户和服务器都是不友好的。懒加载就是当 某个图片的位置在你的屏幕范围之内,它才会加载出来。这个是比较好理解的。
(这个懒加载对用户和服务器都是比较友好的,但是对于我们爬虫来说就比较蛮烦了。往往用xpath或者bs4取解析数据的时候,就不准确。)
我们看看下面这张图片有个src2属性,我们知道img标签没有这个属性,只有src属性。所以这个是伪属性它可以是src2也可以是abc之类的,所以浏览器不会去加载。在小众范围的网站中,这种懒加载是常用的方法。
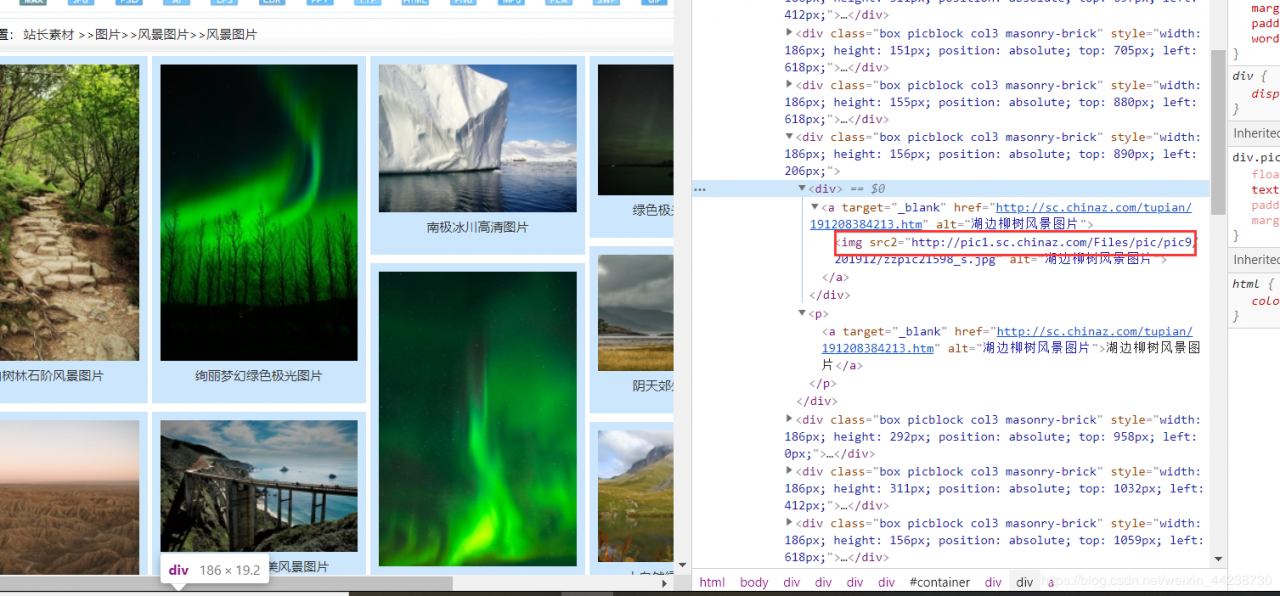
注意到这个src2之后,我洋洋得意。但是在我爬取的过程中,却没有返回到任何的数据。这就很奇怪,于是我打印xpath返回的列表对象长度。(下面展示我省略一部分代码完整代码在文章末尾)
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
page_text = response.text
tree = etree.HTML(page_text)
a_list = tree.xpath('//div[@class="box picblock col3 masonry-brick"]/div/a/img')
print(len(a_list))
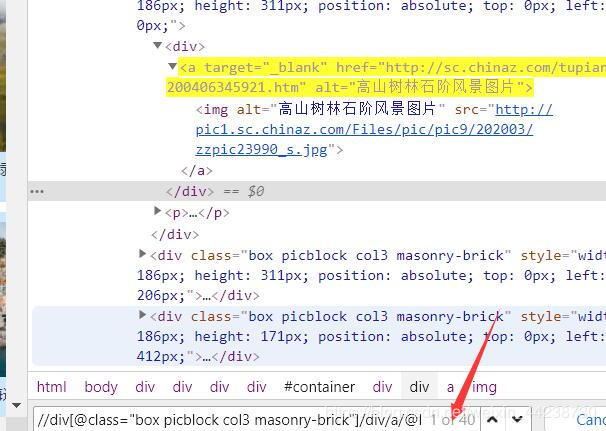
一页有40张图片,照理说打印出40才对,我之前在网页上试了一下xpath路径如下。40个一点没错
但是事与愿违打印出来的是0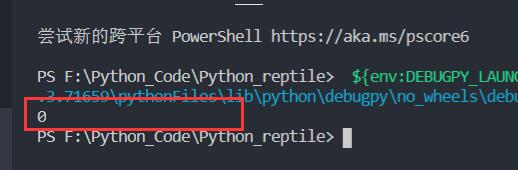
这就让我捉摸不透了,不知道是哪出了问题。我就怀疑可能xpath部分出了问题,那我就先定位到包裹着每个图片的div所以我更改了xpath
前:’//div[@class=“box picblock col3 masonry-brick”]/div/a/@href’
后:’//div[@class=“box picblock col3 masonry-brick”]'
但是打印出来的仍然是0。这就很奇怪。
我怀疑八成这个class也被伪装了,伪装的不是属性,而是属性里面的内容。但是就懒加载来说,不应该class出问题。因为在这之前我看了一些还没加载的图片,这些图片的class名都是 box picblock col3 masonry-brick 。那就是返回的数据可能有问题,于是我就把page_text打印出来,想看看我获取到底是什么数据。然后查看了我获取的class
print(page_text)
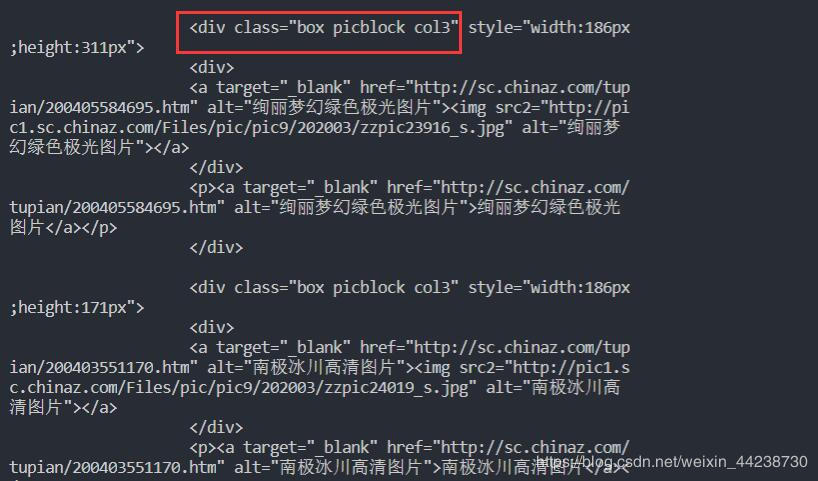
结果这里获取的class也是个伪元素。属性值被伪装了。
但是这我有个疑问既然是懒加载,那么我没加载出来的那些图片的class为什么没有伪装。
仔细思考一下,用requests请求是没有浏览窗口大小这个概念的。所以页面的所有能被伪装的标签元素都是以伪元素的形式存在的。
当人去浏览的时候,只看见了部分的class属性值。这个class名就当是一个集体吧,要加载就全部加载出来了,而对于src属性是针对单个图片的,服务器加载可能有些吃力(我是这样理解的)所以只有浏览到的时候才会加载出来。requests没有窗口的概念,所以当请求时这个class一直是伪装的状态。我们只能用伪装的属性去请求
a_list = tree.xpath('//div[@class="box picblock col3"]/div/a/@href')
print(len(a_list))
唉!一番尝试以后更换了class名以后,打印出来终于是40了

好了,现在我们知道了伪class名和伪src那么我就能爬取图片了。接下来的过程就很简单了。和普通网上爬取图片是一样的。
具体请看下面的完整代码我也做了注释
import requests
from lxml import etree
import os
#我们创建一个站长素材文件夹
if not os.path.exists('素材'):
os.mkdir('素材')
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
url = 'http://sc.chinaz.com/tupian/fengjingtupian.html'
response = requests.get(url=url, headers=headers)
#对返回的数据进行译码,否则会乱码
response.encoding = 'utf-8'
#得到page_text
page_text = response.text
tree = etree.HTML(page_text)
#利用xpath定位到img标签,注意这里的class名,别被迷惑了
img_list= tree.xpath('//div[@class="box picblock col3"]/div/a/img')
#循环遍历返回的列表
for img in img_list:
#列表中的img也是tree类型的,所以我们可以再具体的定位到属性
title=img.xpath('./@alt')[0]
img_url=img.xpath('./@src2')[0]
#图片是byte类型,用content属性写入到文件里面
img_data=requests.get(img_url,headers=headers).content
with open('站长素材/'+title+'.jpg','wb')as fp:
fp.write(img_data)
print(title+'打印成功')
这就是突破懒加载,爬取图片的过程。当然这个爬取的只是页面中的小图,如果你想爬取大图也行,那我们就不用定位到img了,我们定位到a标签,然后获取其href属性,然后利用requests请求,再到详情页去定位到真正的原图。这个我也写好了你可以参考一下:
import requests
from lxml import etree
import os
if not os.path.exists('站长素材'):
os.mkdir('站长素材')
headers = {
'User-Agent':
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
}
url = 'http://sc.chinaz.com/tupian/fengjingtupian.html'
response = requests.get(url=url, headers=headers)
response.encoding = 'utf-8'
page_text = response.text
tree = etree.HTML(page_text)
a_list = tree.xpath('//div[@class="box picblock col3"]/div/a/@href')
for a in a_list:
child_response = requests.get(a, headers=headers)
child_response.encoding = 'utf-8'
child_page = child_response.text
child_node = etree.HTML(child_page)
try:
img_src = child_node.xpath('//div[@class="imga"]//a/@href')[0]
img_title = child_node.xpath('//div[@class="imga"]//a/@title')[0]
img_data = requests.get(url=img_src, headers=headers).content
with open('站长素材/' + img_title + '.jpg', 'wb') as fp:
fp.write(img_data)
print(img_title + '.jpg打印成功')
except Exception as e:
print(e)
和之前的很像对不对,这里我加了一个try,因为有些图片是无效的,所以会报错,程序停止运行。
了解了懒加载,就又掌握了一门反反爬技术。
作者:飞翔的老鹰