python爬虫-豆瓣top250
python爬取豆瓣电影排名及相关信息
这个程序是我自己先开始做,在爬取的过程中遇到了很多问题,毕竟是初学者,然后在百度找了一些别人的程序参考,改正了错误,同时也学到了很多,起码同样的错误不会再犯第二次。
下面讲讲我做这个小爬虫过程
首先找到豆瓣TOP250的url
豆瓣TOP250.(https://movie.douban.com/top250) 安装lxml库
打开终端命令窗口
pip install lxml
安装完成后,检测是否安装成功
打开python IDLE输入
import lxml
或
from lxml import etree
如果没有报错,说明安装成功
导入lxml库from lxml import etree
导入requests库
import requests
输入url
url = 'https://movie.douban.com/top250'
获得响应
>>> import requests
>>> url = 'https://movie.douban.com/top250'
>>> r=requests.get(url)
>>> r.status_code
418
>>>
可以看到豆瓣网返回值为418,说明不能成功访问,只有返回值为200才能成功访问。
这时候我们需要修改头部信息
>>> import requests
>>> url = 'https://movie.douban.com/top250'
>>> r=requests.get(url)
>>> r.status_code
418
>>> kv={'user-agent':'Mozilla/5.0'}
>>> r=requests.get(url,headers=kv)
>>> r.status_code
200
>>>
这样返回值为200,说明可以访问
获得网页代码data = requests.get(url,headers=kv).text
s = etree.HTML(data)
爬取电影名称
movies = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
for i in range(25):
print("{}".format(movies[i]))
输出结果如下

你可能会疑惑movies = s.xpath()里的内容是怎么得来的
在谷歌浏览器中打开豆瓣TOP250的网址,进入网页后,按F12键启动浏览器开发工具
如下图所示
我感觉让它在网页底部显示比较方便操作
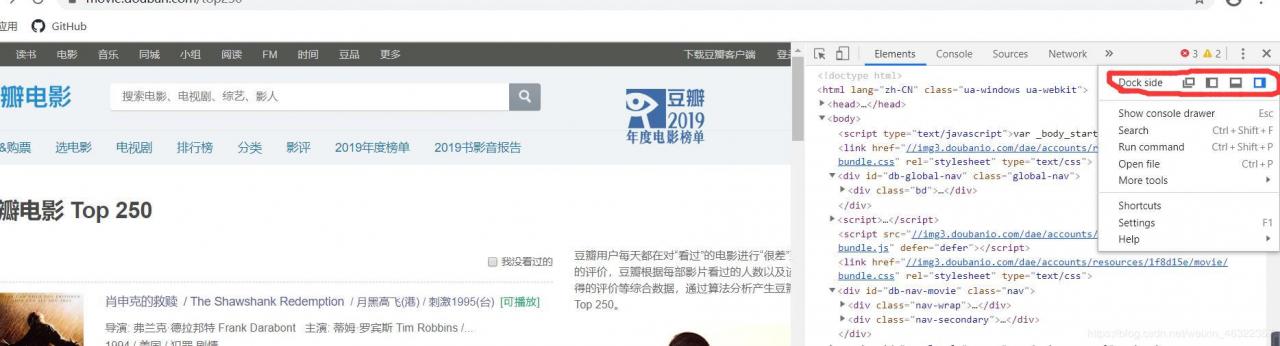
点击X右边的那三个垂直排列的小点,会显示红圈中的内容,第三个就是设置底部显示。
如果你懂一点HTML语言知识会很有帮助,找到电影名称的标签,鼠标右击选择复制(Copy),在复制类型中选择 Copy XPath类型然后粘贴到movies = s.xpath()的括号中,注意用引号括起来
复制内容应该是这个(//*[@id=“content”]/div/div[1]/ol/li[1]/div/div[2]/div[1]/a/span[1]),把li[1]的‘[1]'去掉,这样才能显示整个列表。

用同样的方法爬取豆瓣评分、演员名字、时间、地点、类型等信息
score = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
actor = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]')
time = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[2]')
完整代码和输出结果
from lxml import etree
import requests
url = 'https://movie.douban.com/top250'
kv={'user-agent':'Mozilla/5.0'}
data = requests.get(url,headers=kv).text
s = etree.HTML(data)
movies = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[1]/a/span[1]/text()')
score = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/div/span[2]/text()')
actor = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[1]')
time = s.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[2]/div[2]/p[1]/text()[2]')
for i in range(25):
print("{} {} {} {}".format(movies[i],score[i],actor[i],time[i]))
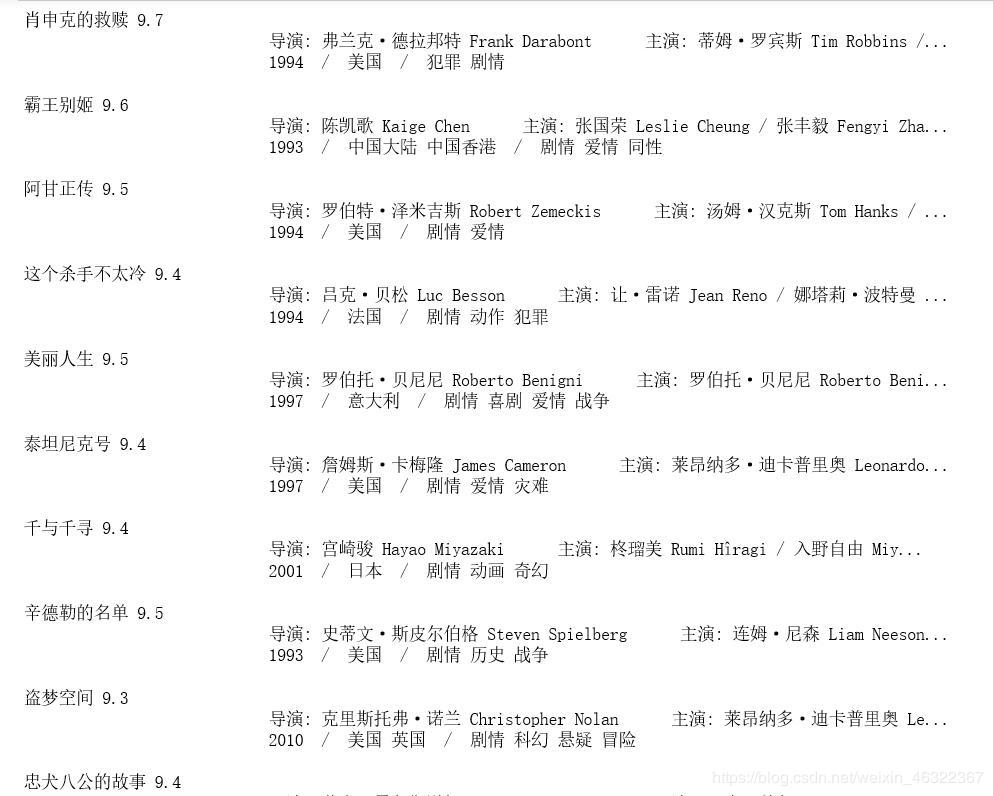


好了,这个小爬虫就结束啦,记得点赞哦
作者:不予时光度流年#