python爬虫一键爬下整页美女图片
最近大四闲在家里特别无聊,毕业设计也想不出做啥,无聊泡论坛的时候发现自己没怎么做过爬虫啊,做几个爬虫练练手
既然做爬虫,就爬点有意思的东西,于是随便找了个网站爬一爬
这个网站结构还算简单网址直接是index_12345.html
直接做个循环就可以爬下所有的网址
捋一下思路
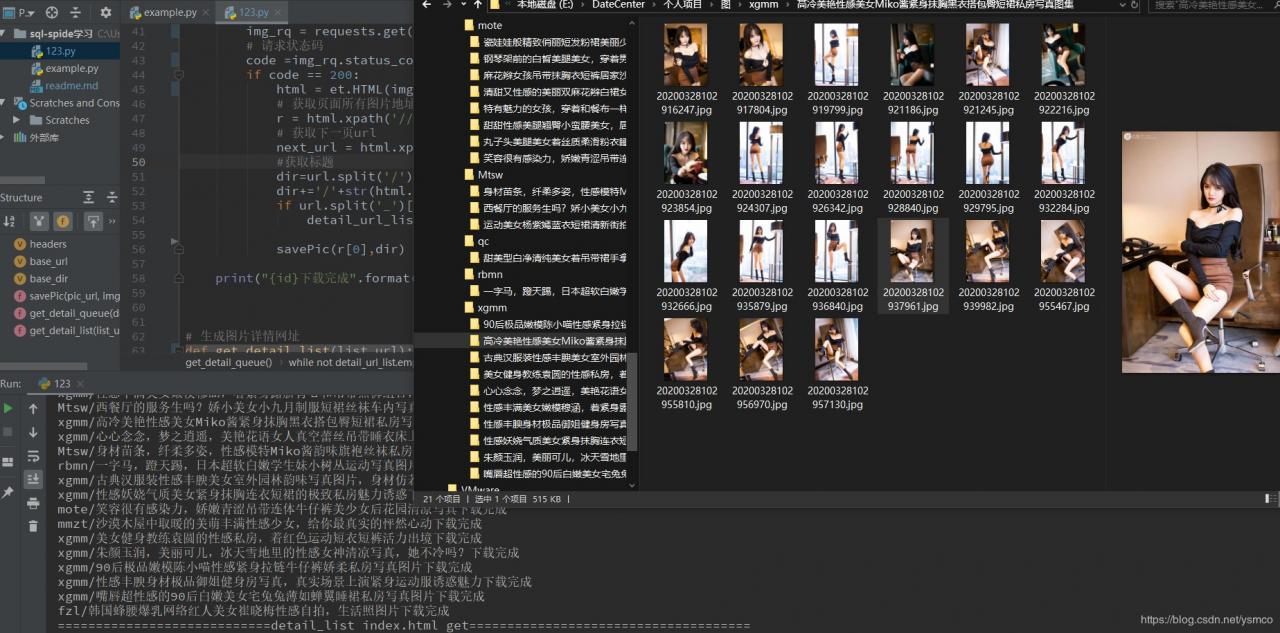
先跑个线程把第一页爬了
import threading # 导入threading模块
from queue import Queue # 导入queue模块
import time # 导入time模块
import requests
import os
from lxml import etree as et
#请求头
headers = {
#用户代理
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
# 待抓取网页基地址
base_url = 'http://www.***.com/mnmm/index.html'
# 保存图片基本路径
base_dir = 'E:/DateCenter/个人项目/图/'
# 保存图片
def savePic(pic_url,img_dir):
file_name = base_dir + img_dir+'/'+pic_url.split('/')[-1]
# 如果目录不存在,则新建,如果文件存在,则跳出
if not os.path.exists(base_dir + img_dir):
os.makedirs(base_dir + img_dir)
elif os.path.exists(file_name):
return
# 获取图片内容
response = requests.get(pic_url, headers=headers)
# 写入图片
with open(file_name, 'wb') as fp:
for data in response.iter_content(1024):
fp.write(data)
# 循环爬取一套图片地址并存储
def get_detail_queue(detail_url):
# Queue队列的put方法用于向Queue队列中放置元素,由于Queue是先进先出队列,所以先被Put的URL也就会被先get出来。
detail_url_list=Queue(maxsize=50)
detail_url_list.put(detail_url)
while not detail_url_list.empty():
url = detail_url_list.get() # Queue队列的get方法用于从队列中提取元素
img_rq = requests.get(url=url, headers=headers)
# 请求状态码
code =img_rq.status_code
if code == 200:
html = et.HTML(img_rq.text)
# 获取页面所有图片地址
r = html.xpath('//*[@id="showimg"]/a/img/@src')
# 获取下一页url
next_url = html.xpath('//*[@id="showimg"]/a[@title="下一张"]/@href')
#获取标题
dir=url.split('/')[-2]
dir+='/'+str(html.xpath('//*[@id="showimages"]/div[2]/h2/text()')[0])
if url.split('_')[0]==next_url[0].split('_')[0]:
detail_url_list.put(next_url[0])
savePic(r[0],dir)
print("{id}下载完成".format(id=dir))
# 生成图片详情网址
def get_detail_list(list_url):
#list_url_queue = queue(maxsize=1000)
# time.sleep(1) # 延时1s,模拟比爬取文章详情要快
#page_url = base_url + format(i)+'.html'#有图片的页面地址
#page_url ='http://www.souutu.com/mnmm/xgmm/13062_1.html'
index_rq = requests.get(url=list_url, headers=headers)
# 请求状态码
code = index_rq.status_code
if code == 200:
html = et.HTML(index_rq.text)
# 获取页面所有套图地址
detail_list = html.xpath('//*[@id="body"]/main/div[4]/div/div[@class="card-box"]/div[1]/a/@href')
# 获取下一页url
next_url = html.xpath('//*[@id="showimg"]/a[@title="下一张"]/@href')
html_thread = []
for url in detail_list:
url=url.replace('.html', '_1.html')
print(url)
thread = threading.Thread(target=get_detail_queue, args=(url,))
thread.start()
html_thread.append(thread) # 线程抓取抓取图片
for i in html_thread:
i.join()
print("============================detail_list {id} get=====================================".format(id=list_url.split('/')[-1])) # 打印出得到了哪些文章的url
# 主函数
if __name__ == "__main__":
get_detail_list(base_url)
有的时候下的图片没下好,有一半糊的,这个时候可以删除掉,再跑一遍,
之后就是好的了
还有一些想做的功能没有实现,做个ip池防止被检测啥的,下载速度也没跑满,不过已经写了很久了,下次再说吧!
The End!
作者:Shao_Yee