python爬虫之scrapy初试与抓取链家成交房产记录
接上一篇文章,本机安装好python之后和scrapy之后,我们开始学习使用scrapy创建爬虫程序。
今天先来点简单的,不那么复杂,先看看抓取链家网里面的房价信息。
首先使用CMD命令行进入F盘创建scrapy的框架
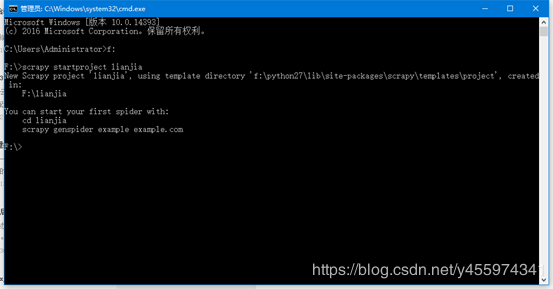
scrapy startproject lianjia
使用编辑器打开lianjia文件结构如下
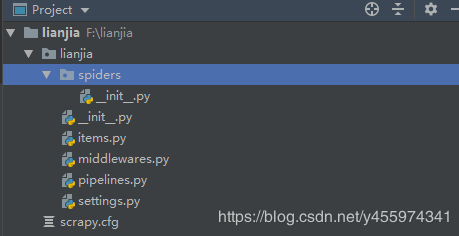
简单说一下scrapy框架的生成结构:
spiders文件夹主要存放爬虫逻辑文件,稍后我们会在这里面创建一个爬虫文件
items.py是为了方便保存抓取的数据,会在文件内预定义数据字段(类似model)
middlewares.py是中间件,可以用于下载图片,自动化处理等
pipelines.py是管道文件,可以用于处理数据的存储
setting.py是配置文件
第一步,在spiders中创建爬虫文件linajiaSql.py
# -*- coding: utf-8 -*-
import scrapy
import re
import time
from lianjia.items import LianjiaItem
class LianjiasqlSpider(scrapy.Spider):
name = "lianjiaSql"
allowed_domains = ["cd.lianjia.com/chengjiao"]
start_urls = ["https://cd.lianjia.com/chengjiao/"]
def parse(self, response):
mingyan = response.xpath("//ul[contains(@class,'listContent')]/li/a/@href").extract()
for v in mingyan: # 循环获取
if v is not None:
# print v
yield scrapy.Request(url=v, callback=self.parse_s, dont_filter=True)
def parse_s(self, response):
item = LianjiaItem()
item['title'] = response.xpath("//div[contains(@class,'house-title')]//h1/text()").extract()[0]
atime = response.xpath("//div[contains(@class,'house-title')]//span/text()").extract()[0]
item['atime'] = re.search(r"(\d{4}.\d{1,2}.\d{1,2})", atime).groups()[0]
item['allprice'] = response.xpath("//span[contains(@class,'dealTotalPrice')]//i/text()").extract()[0]
item['price'] = response.xpath("//div[contains(@class,'price')]//b/text()").extract()[0]
item['addtime'] = int(time.time())
yield item
其中使用到的有re模块正则,time获取当前时间,xpath根据html分析获取,如果对xpath不熟悉的朋友,请自行查看相关代码
第二步,设置items.py
items是存放数据库的字段,爬虫里面会直接调用
import scrapy
class LianjiaItem(scrapy.Item):
title = scrapy.Field()
atime = scrapy.Field()
allprice = scrapy.Field()
price = scrapy.Field()
addtime = scrapy.Field()
第三步,设置存储mysql的管道文件
在items.py同级创建MySQLPipeline.py
这就是著名的管道文件,用来做数据库插入操作的。
import MySQLdb
class MySQLPipeline(object):
def __init__(self):
self.connect = MySQLdb.connect(
host='127.0.0.1',
port=3306,
db='lianjiadb',
user='root',
passwd='root',
charset='utf8',
use_unicode=True)
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
self.cursor.execute(
"""insert into lianjia(title, atime,allprice,price ,addtime) value (%s, %s,%s,%s,%s)""",
(item['title'],
item['atime'],
item['allprice'],
item['price'],
item['addtime'],))
self.connect.commit()
return item
第四步,设置setting.py配置数据存储管道和header请求头文件
setting顾名思义就是用来做设置的文件喽
在setting.py中增加
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Referer': 'http://www.baidu.cn/',
}
ITEM_PIPELINES = {
'lianjia.MySQLPipeline.MySQLPipeline': 300,
}
到此整个爬虫就写好了,别忘记配置你的mysql
创建一个lianjiadb的数据库,并且创建lianjia表,具体如下
CREATE TABLE `lianjia` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(255) DEFAULT NULL COMMENT '房名',
`atime` varchar(20) DEFAULT NULL COMMENT '成交时间',
`allprice` varchar(10) DEFAULT NULL COMMENT '总价(万)',
`price` varchar(12) DEFAULT NULL COMMENT '单价(元/平方)',
`addtime` varchar(15) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
OK,这时候就可以使用CMD命令行,进入到F:/lianjia/,启动爬虫,注意大小写
scrapy crawl lianjiaSql
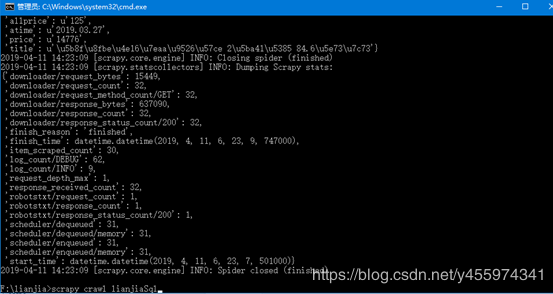
如果在爬虫的过程中报错有什么模块没有安装,请使用PIP安装对应模块
爬虫启动,抓取数据如下图:
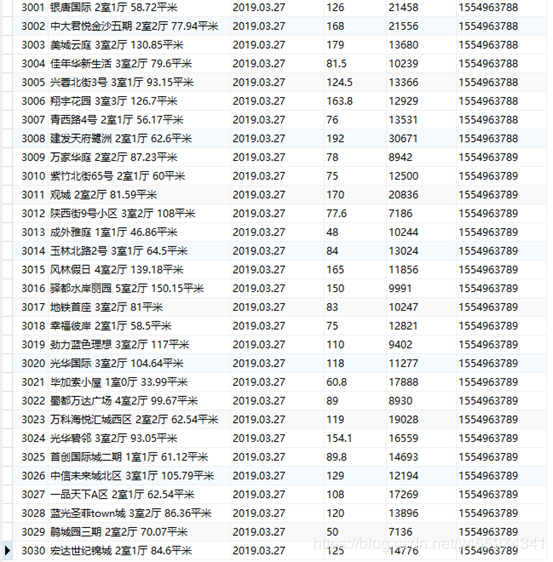
相对应的链家网址显示
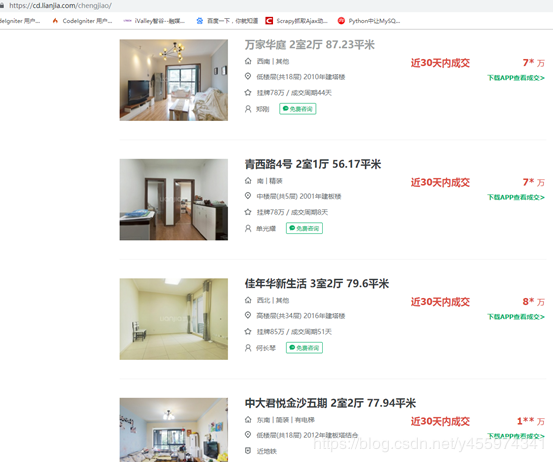
好啦,这节先讲这么多,下节讲一讲如何分页爬取更多的成交房记录
作者:慕容灬天