Python爬虫学习之requests的使用教程
requests库简介
requests库安装
1、pip命令安装
2、下载代码进行安装
requests库的使用
发送请求
get请求
抓取二进制数据
post请求
POST请求的文件上传
利用requests返回响应状态码
requests库简介requests 库是一个常用的用于 http 请求的模块,它使用 python 语言编写,可以方便的对网页进行爬取,是学习 python 爬虫的较好的http请求模块。 它基于 urllib 库,但比 urllib 方便很多,能完全满足我们 HTTP 请求以及处理 URL 资源的功能。
requests库安装如果已经安装了 anaconda ,就已经自带了 requets 库(建议新手安装 Python 的话直接安装 anaconda 就好了,可以省去很多繁琐的安装过程的)。如果确实没有安装,可以通过以下两种方式来进行安装
在有pip的情况下直接客户端输入命令下载
pip install requests
2、下载代码进行安装
由于 pip 命令可能安装失败所以有时我们要通过下载第三方库文件来进行安装。
在 github 上的地址为:https://github.com/requests/requests
下载文件到本地之后,解压到 python 安装目录。
之后打开解压文件,在此处运行命令行并输入:
python setup.py install
即可。
之后我们测试 requests 模块是否安装正确,在交互式环境中输入
import requests
如果没有任何报错,说明requests模块我们已经安装成功了
在时用requests库要导入requests模块
import requests
接下来我们就可以尝试获取某个页面
import requests
r = requests.get('http://www.baidu.com')
print(r.text)
现在,我们有一个名为 r 的 Response 对象。我们可以从这个对象中获取所有我们想要的信息
除了get请求我们还有PUT,DELETE,HEAD 以及 OPTIONS 这些http请求方式
接下来我们先看看get请求
get请求上面的例子就是我们用get方法获取到了百度的首页,并且输出打印结果为
<!DOCTYPE html>
<!--STATUS OK--><html> <head>......</body> </html>
Requests 允许你使用 params 关键字参数,以一个字符串字典来提供这些参数。举例来说,如果你想传递 key1=value1 和 key2=value2 到 httpbin.org/get ,那么你可以使用如下代码:
payload = {'key1': 'value1', 'key2': 'value2'}
r = requests.get("http://httpbin.org/get", params=payload)
通过print(r.url),可以打印输出URL
http://httpbin.org/get?key2=value2&key1=value1
注意字典里值为 None 的键都不会被添加到 URL 的查询字符串里。
你还可以将一个列表作为值传入:
payload = {‘key1’: ‘value1’, ‘key2’: [‘value2’, ‘value3’]}
范例
import requests
url = 'http://httpbin.org/get'
params = {
'name': 'jack',
'age': 25
}
r = requests.get(url, params = params)
print(r.text)
输出结果

在这里,我们将请求的参数封装为一个 json 格式的数据,然后在 get 方法中传给 params 参数,这样就完成了带参数的 GET 请求 URL 的拼接,省去了自己拼接 http://httpbin.org/get?age=22&name=jack 的过程,非常的方便。
此外,在上面我们看到返回的r.tetx虽然是个字符串,但是它其实是个JSON格式的字符串,我们可以通过 r.json() 方法来将其直接转换为JSON格式数据,从而可以直接解析,省去了引入 json 模块的麻烦。示例如下
import requests
url = 'http://httpbin.org/get'
params = {
'name': 'jack',
'age': 25
}
r = requests.get(url, params = params)
print(type(r.json()))
print(r.json())
print(r.json().get('args').get('age'))
输出结果
抓取二进制数据<class 'dict'>
{'args': {'age': '25', 'name': 'jack'}, 'headers': {'Accept': '*/*', 'Accept-Encoding': 'gzip, deflate', 'Host': 'httpbin.org', 'User-Agent': 'python-requests/2.28.1', 'X-Amzn-Trace-Id': 'Root=1-6300e24d-71111778036e3f8339b55886'}, 'origin': '223.90.115.87', 'url': 'http://httpbin.org/get?name=germey&age=25'}
25
从上面的例子中我们发现我们可以轻松获取网页的html文档,但是如果我们在浏览网址时想要获取的是图片、视频、音频这些内容的话又该怎么办呢?
我们知道视频音频这些不过就是二进制码,所以我们获取二进制码就能够获取到这些形形色色的图片视频了,接下来我们看看如何获取这些二进制码
接下来以baidu的站点图标为例:
import requests
r = requests.get('https://baidu.com/favicon.ico')
print(r.text)
print(r.content)
......
b'\x00\......x00'
使用content我们可以输出获取的文档的二进制码,但是我们又该如何处理这些二进制码呢?
其实很简单直接将其保留到本地就可以了
import requests
r = requests.get('https://baidu.com/favicon.ico')
with open('favicon.ico', 'wb') as f:
f.write(r.content)
运行之后就发现我们成功爬取了图片,其实其他之类的视频也是这样操作的

接下来就是另外一种请求方式post请求
先看看是如何进行请求的
import requests
data = {'name': 'jack', 'age': '25'}
r = requests.post("http://httpbin.org/post", data=data)
print(r.text)
输出结果
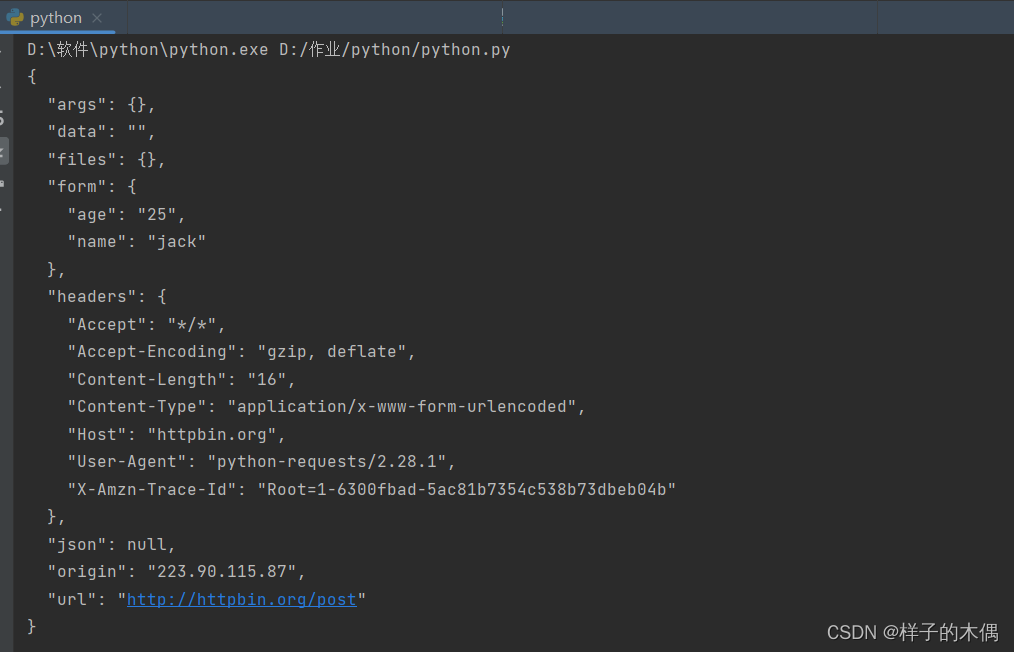
在这里我们将需要的表单数据通过data进行提交,完成一次post请求
同时,你还可以为 data 参数传入一个元组列表。在表单中多个元素使用同一 key 的时候,这种方式尤其有效:
data = (('key1', 'value1'), ('key1', 'value2'))
POST请求的文件上传
范例
import requests
files = {'file': open('favicon.ico', 'rb')}
r = requests.post('http://httpbin.org/post', files=files)
print(r.text)

我们通过传入files参数来实现文件上传,不过前提是open方法中的文件需要存在(这里我上传的文件就是在get请求里面获取的百度图标),在这里不写路径表示该文件在当前目录下, 否则需要写上完整的路径。这个网站会返回响应,里面包含 files 这个字段,而 form 字段是空的,这证明文件上传部分会单独有一个 files 字段来标识。
利用requests返回响应状态码r.status_code:获得返回的响应状态码
r.status_code == requests.codes.ok:内置状态码查询
Response.raise_for_status():抛出异常的响应状态
利用前两个方法我们可以获得响应的状态
r = requests.get('http://httpbin.org/get')
r.status_code
200
查询状态
r.status_code == requests.codes.ok
True
如果我们发送一个错误请求获取,我们就可以使用Response.raise_for_status()来抛出异常
r = requests.get('http://httpbin.org/status/404')
r.status_code
404
bad_r.raise_for_status()
Traceback (most recent call last):
File "requests/models.py", line 832, in raise_for_status
raise http_error
requests.exceptions.HTTPError: 404 Client Error
如果响应正常就不会抛出异常,返回以None
到此这篇关于Python爬虫学习之requests的使用教程的文章就介绍到这了,更多相关Python requests内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!