学习python爬虫看一篇就足够了之爬取《太平洋汽车》论坛及点评实战爬虫大全
前言: 这也是一篇毕业论文的数据爬虫,我第一次看见《太平洋汽车》的点评信息时,检查它的网页元素,发现并没有像《汽车之家》那样的字体反爬技术,所有就初步判断它没有很强的反爬虫技术,大不了就使用selenium库自动化实现爬虫呗。但是我确因为这样一个网页写了6种爬虫手段,一直在与它的反爬虫技术对抗,虽然最后我完成了任务,但是感觉并不是很完美,和其他网站的爬虫相比起来,它的运行速度有点慢,也不敢快。就这样收手吧,通过它也学到了很多的知识,如果你也想学习爬虫,这篇文章可以帮你解决90%以上的网页,简单的梳理一下吧,希望对你的学习有所帮助!
文章目录1、最快的30行代码1.1、python库的基础介绍1.1.1、requests库1.1.2、time库1.1.3、浏览器代理1.1.4、re库1.1.5、替换 方法1.1.6、CSV库保存数据1.2、爬取网页数据保存思路及代码1.2.1、分析网页1.2.2、实现思路1.2.3、实现代码2、设置请求时间2.1、timeout方法2.2、eventlet库3、requests + IP代理3.1、如何使用IP代理3.2、如何获取 IP3.3、认识随机数3.4、IP 代理实现源码4、requests + cookie值4.1、cookie值得获取与转化4.2、使用cookie值请求服务器5、Selenium自动化爬取5.1、自动登录《太平洋汽车》4.2、传入URL爬取信息6、会话请求6.1、如何使用requests提交账号和密码6.2、源码汇总7、爬取“朗逸”论坛信息7.1、分析论坛首页7.2、爬取论坛首页论题链接7.2.1、如何定位xpath节点7.2.2、代码实现7.3、BeautifulSoup筛选信息7.4、把文本写入txt文件保存7.5、论坛源码汇总结果下载: https://www.lanzous.com/i9ilkfi
1、最快的30行代码 1.1、python库的基础介绍 我这里一共使用了5个python的基础库,简单的来介绍一下它们 1.1.1、requests库这个是一个请求服务器的库,用于向服务器发出请求,返回结果,如果请求的是网页的URL,返回的则是该网页的HTML,我们要爬取的文字就在其中,直接进行提取就行了。使用前需要进行安装,可以直接用cmd命令: pip install requests ,使用方法如下:
import requests
html = requests.get('https://baidu.com').text
print (html)
也可以在其中设置它的其他参数:
| 参数 | 作用 |
|---|---|
| url | 网页的URL |
| headers | 浏览器参数,代理等,用于模拟浏览器发出请求 |
| data | 存放请求时提交的信息 |
| timeout | 链接服务器响应的时间,请求不到就结束 |
| proxies | IP代理 |
| … | … |
重点: 爬虫的目的就是在模拟浏览器向服务器发出请求拿到数据,如果服务器识别你的这个是爬虫程序,就会防止你获取数据,或者给你错误的信息,所以写爬虫是一定要模拟的像服务器一样,防止反爬虫。
1.1.2、time库 这个库主要用于记录时间和设置暂停的时间,之所以要暂停时间是怕访问频率过快被识别这是爬虫程序!import time
startTime = time.time() #记录起始时间
time.sleep(3) # 暂停3秒钟
endTime = time.time()#获取结束时的时间
useTime = endTime-startTime #结束时间减开始时间等于使用时间
print ("该次所获的信息一共使用%s秒"%useTime)
结果:
该次所获的信息一共使用3.0004384517669678秒
1.1.3、浏览器代理
(1)自己浏览器的代理
浏览器代理可以使用自己浏览器的,以谷歌为例:打开网页,鼠标右击——> 检查——> Network——> All ——> headers——> user-agent
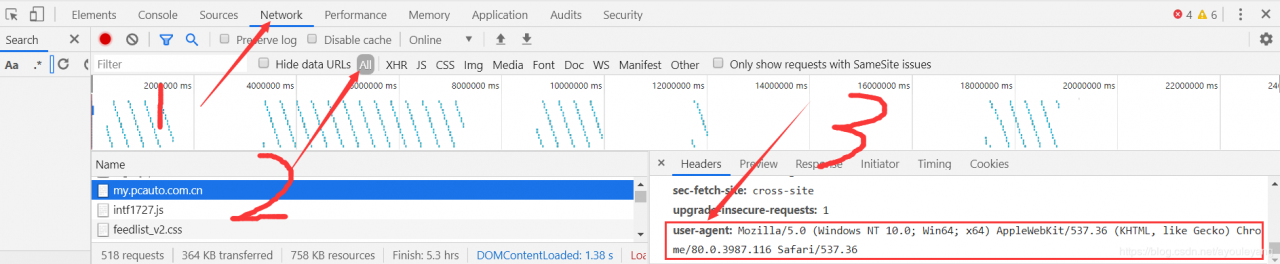
设置方式:
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"
}
(2)fake_useragent库
这个库可以随机生成浏览器代理,可以指定浏览器类型,也可以随机,如随机生成5个谷歌浏览器的 User-Agent :
from fake_useragent import UserAgent
for i in range(5):
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
print (headers)
{'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36'}
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1467.0 Safari/537.36'}
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1467.0 Safari/537.36'}
{'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.1 Safari/537.36'}
{'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2227.0 Safari/537.36'}
1.1.4、re库
re也叫做正则表达式,可以用来匹配需要的内容,对于想快速使用它入门的同学,只需要会 .*? 就可以了,没有括号的 .*? 表示匹配掉,有括号的 (.*?) 表示匹配出来。匹配出网页中的内容,看一个简单的案例:
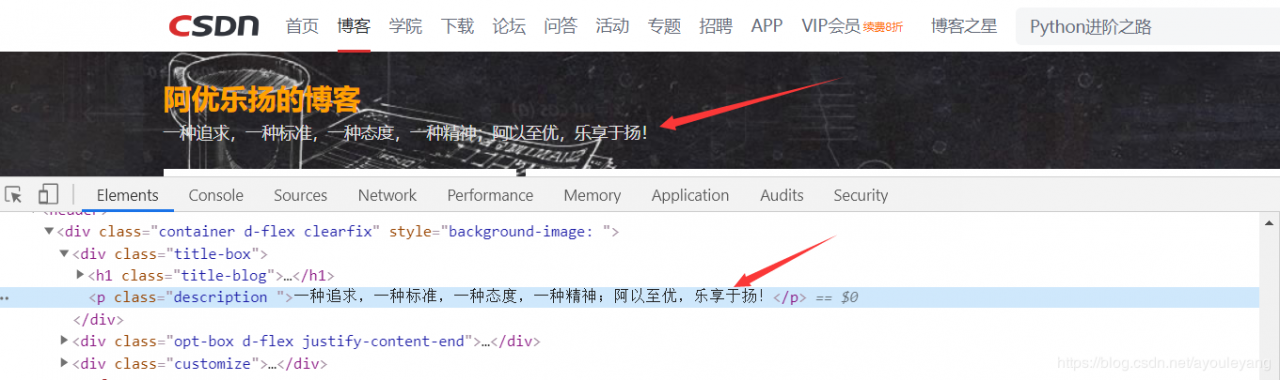
为了更方便查看结果,我复制了两次这个文本的源代码,并且改变了其中一个的class标签样式为 ayouleyang 。
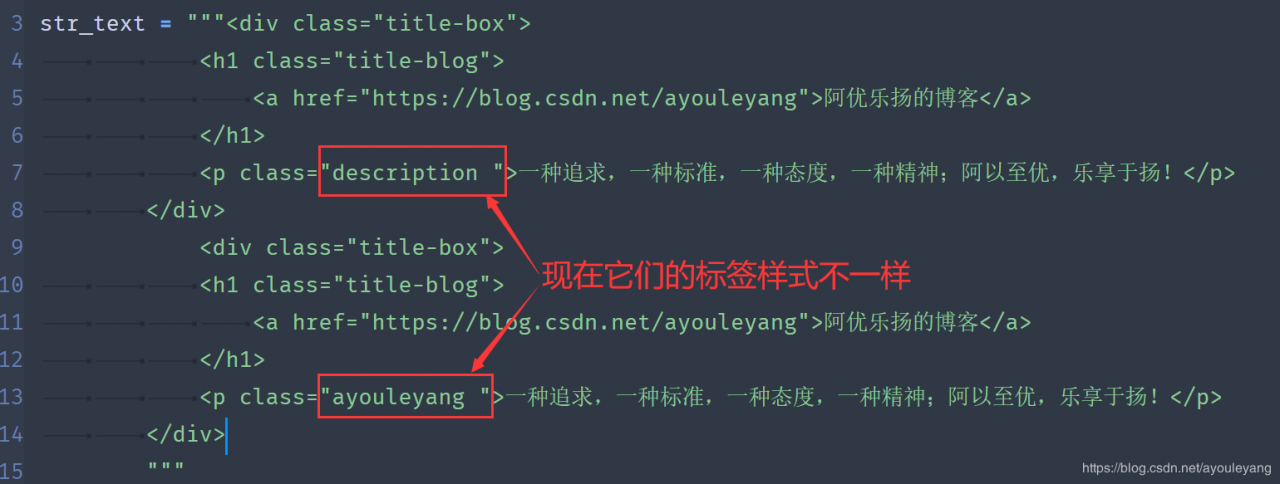
匹配方法如下:
import re
#假设一个字符串
str_text = """
阿优乐扬的博客
一种追求,一种标准,一种态度,一种精神;阿以至优,乐享于扬!
阿优乐扬的博客
一种追求,一种标准,一种态度,一种精神;阿以至优,乐享于扬!
"""
r1 = re.compile('(.*?)
') #只取到第一个,注意class="description "
result1 = re.findall(r1, str_text) #在str_text中找到所有符号r1规则的信息
print ("result1 = ", result1)
r2 = re.compile('(.*?)
') #class中使用了通配符,匹配到两个
result2 = re.findall(r2, str_text)
print ("result2 = ", result2)
结果:
result1 = ['一种追求,一种标准,一种态度,一种精神;阿以至优,乐享于扬!']
result2 = ['一种追求,一种标准,一种态度,一种精神;阿以至优,乐享于扬!', '一种追求,一种标准,一种态度,一种精神;阿以至优,乐享于扬!']
它的结果存放在数组之中,可以直接存放到CSV文件中,上面的方式如果有必要的话,可以先用
1.1.5、替换 方法替换到字符串中可以造成干扰的换行符,制表符和空格,然后再进行匹配信息
str_text = str_text.replace('\r\n', '').replace('\t','').replace(' ','')
1.1.6、CSV库保存数据
这是一个以标点符号分隔数据的文件,默认为 , 分隔,分隔符号也可以自定义,通常不需要设置,使用默认的方法
import csv
#创建CSV文件,并写入表头信息,并设置编码格式为“utf-8-sig”防止中文乱码
fp = open('./test_file.csv','a',newline='',encoding='utf-8-sig') #"./"表示当前文件夹,"a"表示添加
writer = csv.writer(fp) #方式为写入
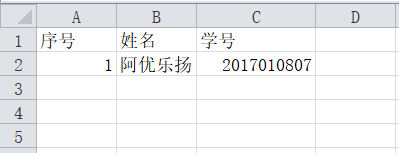
writer.writerow(('序号','姓名','学号')) #表头
info = ['1', '阿优乐扬', '2017010807'] #内容为数组
writer.writerow((info))
fp.close() #关闭文件
https://price.pcauto.com.cn/comment/sg1633/
https://price.pcauto.com.cn/comment/sg1633/p2.html
https://price.pcauto.com.cn/comment/sg1633/p3.html
https://price.pcauto.com.cn/comment/sg1633/p4.html
https://price.pcauto.com.cn/comment/sg1633/p5.html
从它的规律不难看出它的下一个链接,对于第一个链接,我们可以用其他链接的方式,为它加上 p1.html ,在浏览器中查看是否能正常访问,结果是可以的,接下来就可以批量生成链接了。
for page in range(1, 10): #简单生成9个试试,从0开始,不包括10
comment_url = 'https://price.pcauto.com.cn/comment/sg1633/p%s.html'%page
print (comment_url)
结果:
https://price.pcauto.com.cn/comment/sg1633/p1.html
https://price.pcauto.com.cn/comment/sg1633/p2.html
https://price.pcauto.com.cn/comment/sg1633/p3.html
https://price.pcauto.com.cn/comment/sg1633/p4.html
https://price.pcauto.com.cn/comment/sg1633/p5.html
https://price.pcauto.com.cn/comment/sg1633/p6.html
https://price.pcauto.com.cn/comment/sg1633/p7.html
https://price.pcauto.com.cn/comment/sg1633/p8.html
https://price.pcauto.com.cn/comment/sg1633/p9.html
1.2.2、实现思路
导入所需要使用的库
获取开始的时间
设置浏览器代理
创建CSV文件并打开写入表头信息
设置需要爬取的页数循环产生其他链接
请求服务器得到HTML
替换掉HTML中的空格,换行,制表符等信息
正则匹配出内容
写入文件保存
关闭文件记录时间
结束
1.2.3、实现代码
# 1. 导入所需要使用的库
import requests
import time
import re
import csv
from fake_useragent import UserAgent
startTime = time.time() #2.记录起始时间
headers = {
"User-Agent" : UserAgent().chrome #3.chrome浏览器随机代理
}
#4.创建CSV文件,并写入表头信息
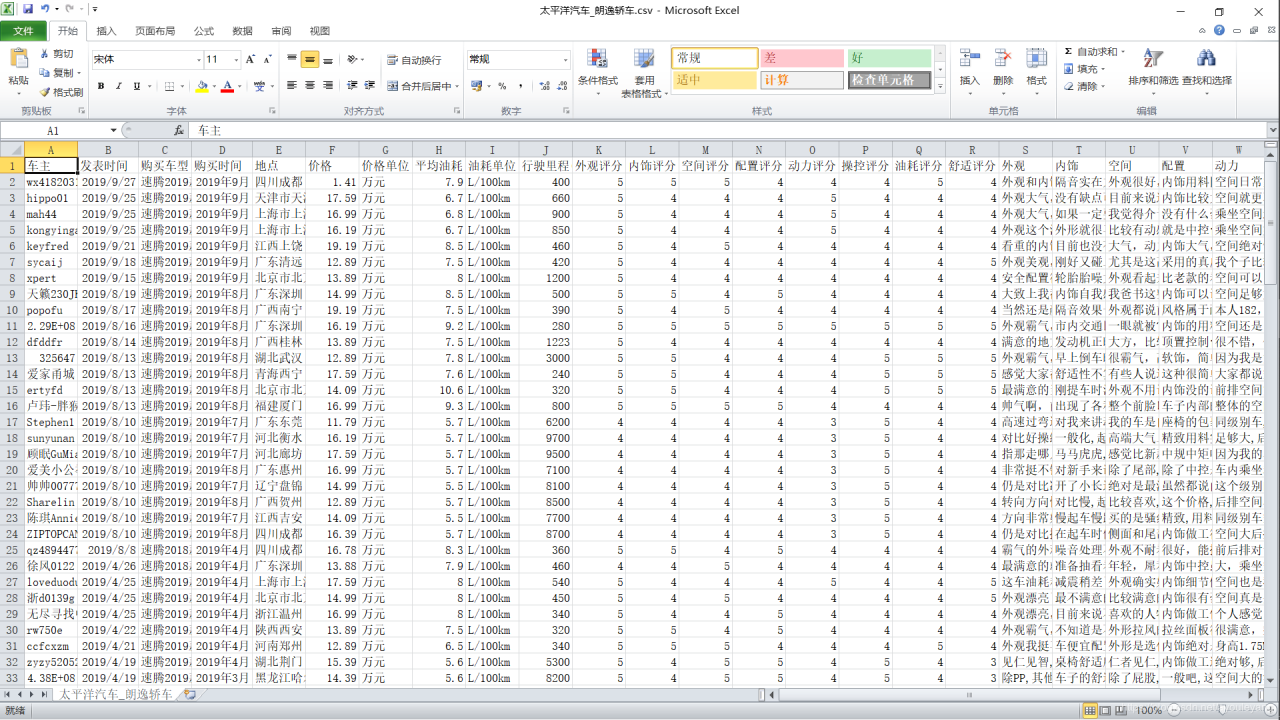
fp = open('./太平洋汽车_速腾轿车.csv','a',newline='',encoding='utf-8-sig')
writer = csv.writer(fp)
writer.writerow(('车主','发表时间','购买车型','购买时间','地点','价格','价格单位','平均油耗', '油耗单位','行驶里程(公里)', '外观评分', '内饰评分', '空间评分', '配置评分', '动力评分', '操控评分', '油耗评分', '舒适评分', '外观', '内饰', '空间', '配置', '动力', '操控', '油耗', '舒适'))
# 5. 设置需要爬取的页数循环产生其他链接
for page in range(1, 789):# 1, 789
comment_url = 'https://price.pcauto.com.cn/comment/sg1633/p%s.html'%page
#6.请求服务器得到HTML
response = requests.get(url=comment_url, headers=headers).text
#7. 替换掉HTML中的空格,换行,制表符等信息
res_replace = response.replace('\r\n', '').replace('\t','').replace(' ','')
# 8. 正则匹配出内容
r = re.compile('(.*?)(.*?)发表.*?target="_blank">(.*?)<.*?购买时间(.*?).*?购买地点(.*?).*?裸车价格(.*?)(.*?).*?平均油耗(.*?)(.*?).*?行驶里程(.*?)公里.*?- 外观.*?(.*?)
- 内饰.*?(.*?)
- 空间.*?(.*?)
- 配置.*?(.*?)
- 动力.*?(.*?)
- 操控.*?(.*?)
- 油耗.*?(.*?)
- 舒适.*?(.*?).*?优点:(.*?).*?缺点:(.*?).*?外观:(.*?).*?内饰:(.*?).*?空间:(.*?).*?配置:(.*?).*?动力:(.*?).*?操控:(.*?).*?油耗:(.*?).*?舒适:(.*?)')
re_html = re.findall(r, res_replace)
# 9.写入数据
for index1 in range(len(re_html)):
txt = re_html[index1]
writer.writerow(txt)
print ("一共发现%s页,正在爬取第%s页"%(788, page))
fp.close() #10.关闭文件
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
编辑器运行时截屏:
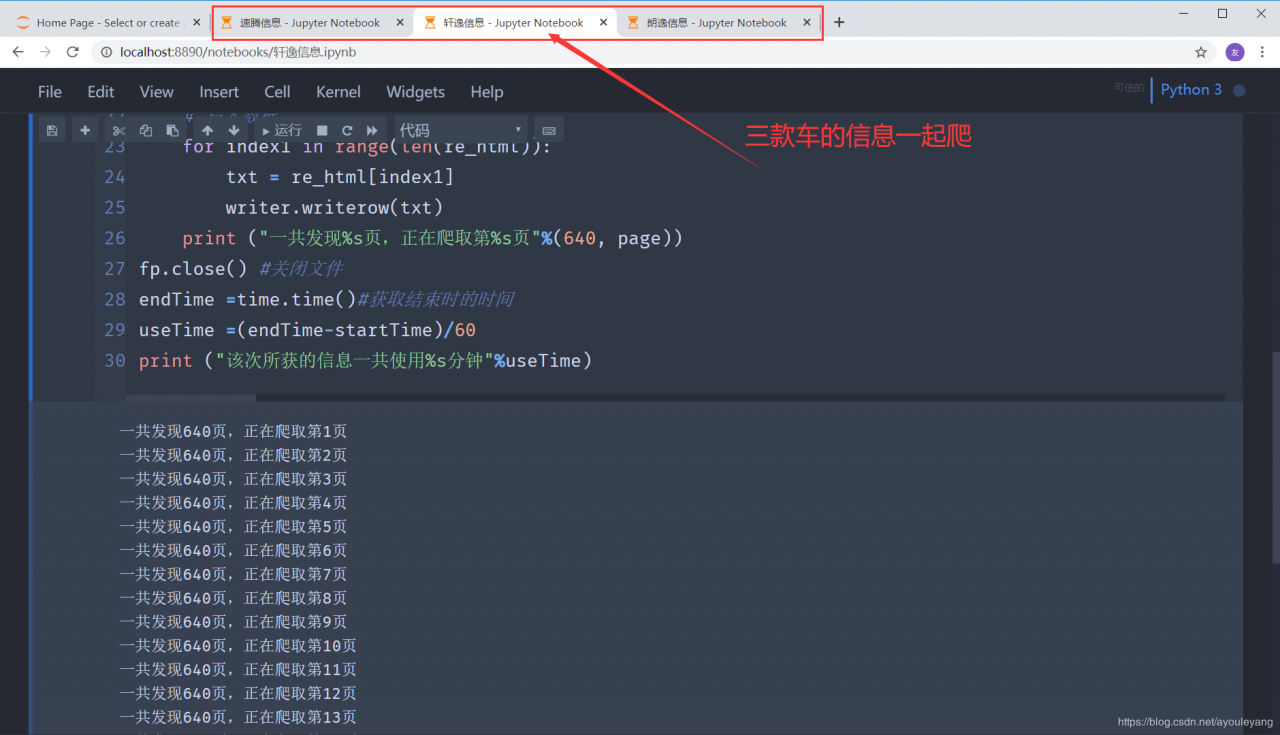
速度还是很快的,大约一秒钟一个页面,还可以三款车的信息一起爬,毫无压力!!!
这是早上爬取的内容,又要要出门做点事,我就先把代码暂停了,没有接着爬取信息,等我下午来继续运行这个代码是,想不到的事情发生了,这个爬虫程序被识别出来了,一直卡死,陷入假死状态,只能重启代码,后来直接不能请求网页了… …
2、设置请求时间
2.1、timeout方法
现在我需要做的事情是如果请求超时,5秒请求失败就放弃,程序就自动结束请求,语法如:
requests.get(url=url, timeout=5)
但是,这个设置在这个程序中并没有用,还是陷入假死状态.
2.2、eventlet库
某步超时就跳过
import time
import eventlet #导入eventlet这个模块
eventlet.monkey_patch() #必须加这条代码
with eventlet.Timeout(2,False): #设置超时时间为2秒
print ('这条语句正常执行')
time.sleep(4)
print ('没有跳过这条输出')
print ('跳过了输出')
结果:
这条语句正常执行
跳过了输出
上面的这个代码测试是没有问题的,但是看看在requests中的用法,例如:
import requests
import eventlet#导入eventlet这个模块
eventlet.monkey_patch()#必须加这条代码
with eventlet.Timeout(2,False):#设置超时时间为2秒
r=requests.get("http://blog.csdn.net/ayouleyang", verify=False)
print('r')
print('通过上面的请求。。。')
经过我的测试,对于这个网站并没哟作用… …
3、requests + IP代理
对于一些网站,它发现某个IP在频繁的访问时,它就可以把它当作爬虫程序看待,直接把这个 IP 禁掉,禁止这个IP访问网站,所以我们可以使用 IP 代理来访问它。
3.1、如何使用IP代理
先来解读一下这个程序:
import requests
proxies={"http":"http://192.10.1.10:8080"} #ip字典型
requests.get("https://baidu.com",proxies=proxies) #设置IP代理访问百度
这样看起来是不是很简单,只需要找到大量的 IP ,并且把它变为字典性数据就可以直接放在requests中使用了。
3.2、如何获取 IP
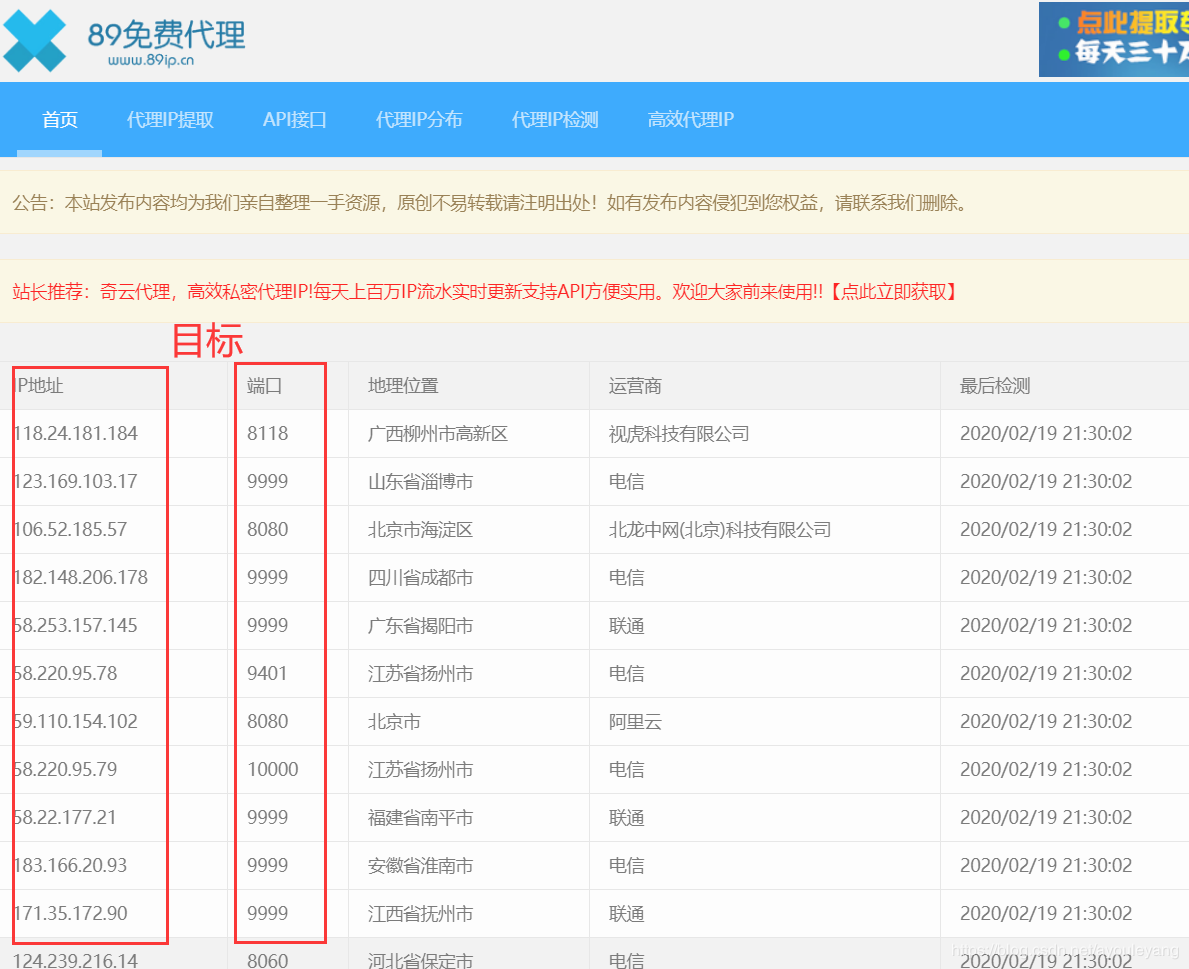
作为一个学习型用户,找一个 网站爬取免费IP来使用就行了,商业用户可以选择购买IP来使用;但是网站上很多免费的 IP 一直被别人爬取使用,很多都是失效了的,所以在使用前必须要验证它的有效性。如果它还有效,就把它保存起来,用来代理爬取目标网站。
这里选择的 IP 网站是: http://www.89ip.cn/
测试网站: https://www.baidu.com/
方法: 使用 requests 携带 IP 请求百度的服务器,如果返回的状态码是 200 ,请求成功,说明该 IP 有效,保存起来
操作目标:
我们只需要爬取IP地址和端口,拼接起来就是我们需要的 IP 了
import requests,re,random
from lxml import etree
from fake_useragent import UserAgent
ips = [] #建立数组,用于存放有效IP
for i in range(1,5):
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
ip_url = 'http://www.89ip.cn/index_%s.html'%i
# 请求IP的网站,得到源码
res = requests.get(url=ip_url, headers=headers).text
res_re= res.replace('\n', '').replace('\t','').replace(' ','')
# 使用正则表达匹配出IP地址及它的端口
re_c = re.compile('(.*?) (.*?) ')
result = re.findall(re_c, res_re)
for i in range(len(result)):
#拼接出完整的IP
ip = 'http://' + result[i][0] + ':' + result[i][1]
# 设置为字典格式
proxies={"http":ip}
#使用上面爬取的IP代理请求百度
html = requests.get('https://www.baidu.com/', proxies=proxies)
if html.status_code == 200: #状态码为200,说明请求成功
ips.append(proxies) #添加进数组中
print (ip)
运行结果:
http://218.27.251.146:9999
http://113.106.14.214:8080
http://110.243.15.82:9999
http://113.194.148.80:9999
http://110.243.0.208:9999
http://117.26.41.143:61234
http://47.98.164.213:8080
http://122.138.141.180:9999
http://113.194.151.254:9999
http://112.84.55.36:9999
http://36.255.87.247:83
http://182.35.87.127:9999
http://120.79.214.236:8000
http://101.75.185.143:9999
http://123.169.36.151:9999
http://144.123.69.196:9999
http://113.120.38.120:9999
......
接下来就可以随机选择 IP 进行代理请求目标网站了,又要我们的有用 IP 都存放进数组中了,直接索引出来使用就行了。
3.3、认识随机数
import random
print( random.randint(1,10) ) # 产生 1 到 10 的一个整数型随机数
print( random.random() ) # 产生 0 到 1 之间的随机浮点数
print( random.uniform(1.1,5.4) ) # 产生 1.1 到 5.4 之间的随机浮点数,区间可以不是整数
print( random.choice('tomorrow') ) # 从序列中随机选取一个元素
print( random.randrange(1,100,2) ) # 生成从1到100的间隔为2的随机整数
a=[1,3,5,6,7] # 将序列a中的元素顺序打乱
random.shuffle(a)
print(a)
运行结果:
7
0.18161055860918174
5.296848594843908
r
75
[5, 7, 1, 3, 6]
随机选择代理 IP :
print (ips[random.randint(0 , len(ips))])
{'http': 'http://163.204.246.54:9999'}
3.4、IP 代理实现源码
import requests,random
import time
import re
import csv
import eventlet
from fake_useragent import UserAgent
startTime = time.time() #记录起始时间
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
#创建CSV文件,并写入表头信息
fp = open('./太平洋汽车_朗逸轿车.csv','a',newline='',encoding='utf-8-sig')
writer = csv.writer(fp)
writer.writerow(('车主','发表时间','购买车型','购买时间','地点','价格','价格单位','平均油耗', '油耗单位','行驶里程(公里)', '外观评分', '内饰评分', '空间评分', '配置评分', '动力评分', '操控评分', '油耗评分', '舒适评分', '外观', '内饰', '空间', '配置', '动力', '操控', '油耗', '舒适'))
ips = []
for i in range(15, 16):
print ("正在爬取IP使用代理,请稍等......")
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
ip_url = 'http://www.89ip.cn/index_%s.html'%i
res = requests.get(url=ip_url, headers=headers).text
res_re= res.replace('\n', '').replace('\t','').replace(' ','')
re_c = re.compile('(.*?) (.*?) ')
result = re.findall(re_c, res_re)
for i in range(len(result)):
ip = 'http://' + result[i][0] + ':' + result[i][1]
proxies={"http":ip}
html = requests.get('https://www.baidu.com/', proxies=proxies)
if html.status_code == 200:
ips.append(proxies)
print ("完成IP代理准备工作!!!")
for page in range(1, 771):# 1, 771
eventlet.monkey_patch() #必须加这条代码
with eventlet.Timeout(2,False): #设置超时时间为2秒
time.sleep(random.randint(2,6))
comment_url = 'https://price.pcauto.com.cn/comment/sg3225/p%s.html'%page
response = requests.get(url=comment_url,verify=False, timeout= 5, headers=headers,proxies=ips[random.randint(0 , len(ips)-1)]).text
res_replace = response.replace('\r\n', '').replace('\t','').replace(' ','').replace('\n', '')
r = re.compile(' (.*?)(.*?)发表.*?target="_blank">(.*?)<.*?购买时间(.*?).*?购买地点(.*?).*?裸车价格(.*?)(.*?).*?平均油耗(.*?)(.*?).*?行驶里程(.*?)公里.*?- 外观.*?(.*?)
- 内饰.*?(.*?)
- 空间.*?(.*?)
- 配置.*?(.*?)
- 动力.*?(.*?)
- 操控.*?(.*?)
- 油耗.*?(.*?)
- 舒适.*?(.*?).*?优点:(.*?).*?缺点:(.*?).*?外观:(.*?).*?内饰:(.*?).*?空间:(.*?).*?配置:(.*?).*?动力:(.*?).*?操控:(.*?).*?油耗:(.*?).*?舒适:(.*?)')
re_html = re.findall(r, res_replace)
# 写入数据
for index1 in range(len(re_html)):
txt = re_html[index1]
writer.writerow(txt)
print ("一共发现%s页,正在爬取第%s页:"%(771, page), comment_url)
fp.close() #关闭文件
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
IP代理第一次爬取100多页后也是卡住了,后来运行它,能爬取的越来越少,越来越少,后来我又加上了 cookie 值爬取网站。
4、requests + cookie值
Cookie,有时也用其复数形式 Cookies。类型为“小型文本文件”,是某些网站为了辨别用户身份,进行Session跟踪而储存在用户本地终端上的数据(通常经过加密),由用户客户端计算机暂时或永久保存的信息 ;这个文件与特定的 Web 文档关联在一起, 保存了该客户机访问这个Web 文档时的信息, 当客户机再次访问这个 Web 文档时这些信息可供该文档使用。由于“Cookie”具有可以保存在客户机上的神奇特性, 因此它可以帮助我们实现记录用户个人信息的功能。
4.1、cookie值得获取与转化
流程: 打开目标网站——> 鼠标右击——> 点击检查 ——> Network ——> All ——> 刷新 ——> 选中第一个文件 ——> headers ——> 找到cookie值
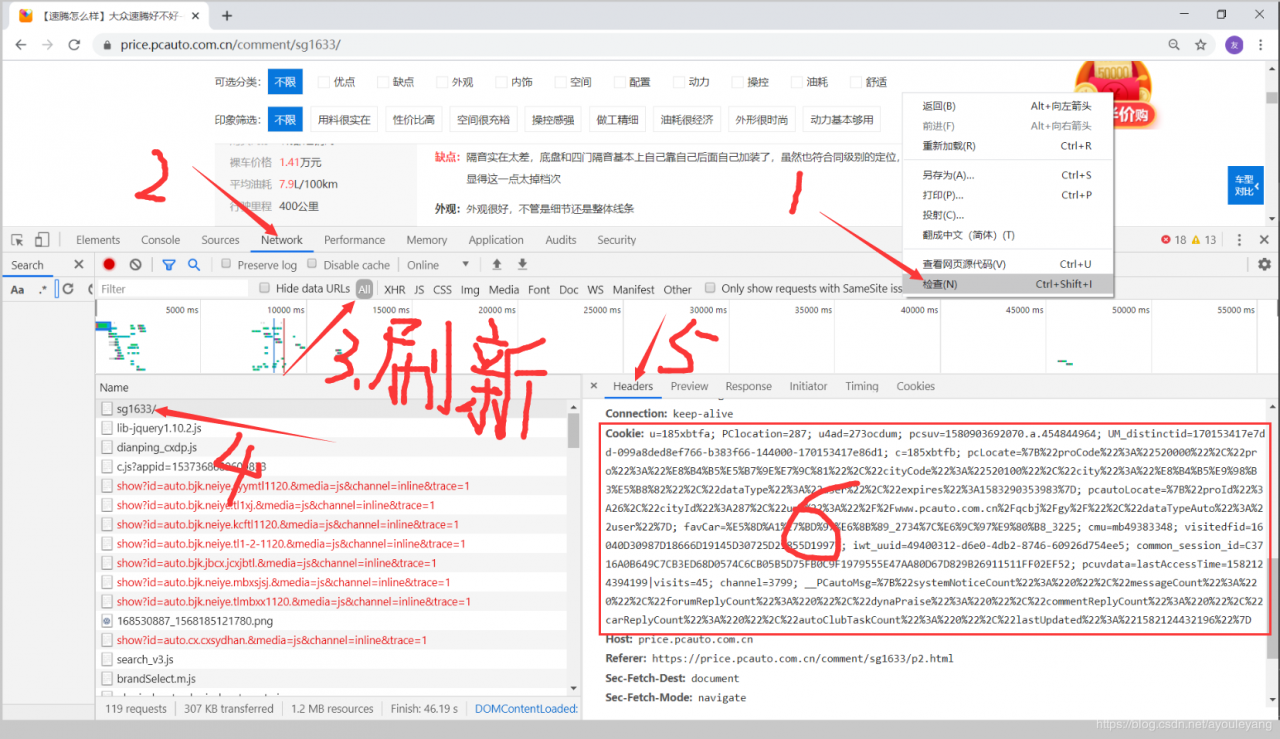
但是代理得cookie值只能使用字典型的数据,所以必须要进行转换一下才能使用
# 这是从浏览器中复制来的原cookie值
cookie = "u=185xbtfa; PClocation=287; u4ad=273ocdum; pcsuv=1580903692070.a.454844964; UM_distinctid=170153417e7dd-099a8ded8ef766-b383f66-144000-170153417e86d1; c=185xbtfb; pcLocate=%7B%22proCode%22%3A%22520000%22%2C%22pro%22%3A%22%E8%B4%B5%E5%B7%9E%E7%9C%81%22%2C%22cityCode%22%3A%22520100%22%2C%22city%22%3A%22%E8%B4%B5%E9%98%B3%E5%B8%82%22%2C%22dataType%22%3A%22user%22%2C%22expires%22%3A1583290353983%7D; pcautoLocate=%7B%22proId%22%3A26%2C%22cityId%22%3A287%2C%22url%22%3A%22%2F%2Fwww.pcauto.com.cn%2Fqcbj%2Fgy%2F%22%2C%22dataTypeAuto%22%3A%22user%22%7D; favCar=%E5%8D%A1%E7%BD%97%E6%8B%89_2734%7C%E6%9C%97%E9%80%B8_3225; pc_browsing_history=%7B%22id%22%3A2734%2C%20%22name%22%3A%22%E5%8D%A1%E7%BD%97%E6%8B%89%22%7D%7C%7B%22id%22%3A3225%2C%20%22name%22%3A%22%E6%9C%97%E9%80%B8%22%7D; locationddPro=%u8D35%u5DDE%u7701; cmu=mb49383348; visitedfid=16040D30987D18666D19145D30725D21855D19975; iwt_uuid=49400312-d6e0-4db2-8746-60926d754ee5; common_session_id=C3716A0B649C7CB3ED68D0574C6CB05B5D75FB0C9F1979555E47AA80D67D829B26911511FF02EF52; pcuvdata=lastAccessTime=1582078030478|visits=43; channel=3799; __PCautoMsg=%7B%22systemNoticeCount%22%3A%220%22%2C%22messageCount%22%3A%220%22%2C%22forumReplyCount%22%3A%220%22%2C%22dynaPraise%22%3A%220%22%2C%22commentReplyCount%22%3A%220%22%2C%22carReplyCount%22%3A%220%22%2C%22autoClubTaskCount%22%3A%220%22%2C%22lastUpdated%22%3A%221582078321041%22%7D"
# 将上面哪个cookie转化成字典类型
cookie_dict= {i.split("=")[0]:i.split("=")[-1] for i in cookie.split("; ")}
print (cookie_dict)
转化结果:
{'u': '185xbtfa', 'PClocation': '287', 'u4ad': '273ocdum', 'pcsuv': '1580903692070.a.454844964', 'UM_distinctid': '170153417e7dd-099a8ded8ef766-b383f66-144000-170153417e86d1', 'c': '185xbtfb', 'pcLocate': '%7B%22proCode%22%3A%22520000%22%2C%22pro%22%3A%22%E8%B4%B5%E5%B7%9E%E7%9C%81%22%2C%22cityCode%22%3A%22520100%22%2C%22city%22%3A%22%E8%B4%B5%E9%98%B3%E5%B8%82%22%2C%22dataType%22%3A%22user%22%2C%22expires%22%3A1583290353983%7D', 'pcautoLocate': '%7B%22proId%22%3A26%2C%22cityId%22%3A287%2C%22url%22%3A%22%2F%2Fwww.pcauto.com.cn%2Fqcbj%2Fgy%2F%22%2C%22dataTypeAuto%22%3A%22user%22%7D', 'favCar': '%E5%8D%A1%E7%BD%97%E6%8B%89_2734%7C%E6%9C%97%E9%80%B8_3225', 'pc_browsing_history': '%7B%22id%22%3A2734%2C%20%22name%22%3A%22%E5%8D%A1%E7%BD%97%E6%8B%89%22%7D%7C%7B%22id%22%3A3225%2C%20%22name%22%3A%22%E6%9C%97%E9%80%B8%22%7D', 'locationddPro': '%u8D35%u5DDE%u7701', 'cmu': 'mb49383348', 'visitedfid': '16040D30987D18666D19145D30725D21855D19975', 'iwt_uuid': '49400312-d6e0-4db2-8746-60926d754ee5', 'common_session_id': 'C3716A0B649C7CB3ED68D0574C6CB05B5D75FB0C9F1979555E47AA80D67D829B26911511FF02EF52', 'pcuvdata': '43', 'channel': '3799', '__PCautoMsg': '%7B%22systemNoticeCount%22%3A%220%22%2C%22messageCount%22%3A%220%22%2C%22forumReplyCount%22%3A%220%22%2C%22dynaPraise%22%3A%220%22%2C%22commentReplyCount%22%3A%220%22%2C%22carReplyCount%22%3A%220%22%2C%22autoClubTaskCount%22%3A%220%22%2C%22lastUpdated%22%3A%221582078321041%22%7D'}
4.2、使用cookie值请求服务器
设置方法:
response = requests.get(url=comment_url, headers=headers, cookies= cookie_dict).text
源码汇总:
import requests
import time
import re
import csv
import random
from fake_useragent import UserAgent
startTime = time.time() #记录起始时间
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.116 Safari/537.36" #chrome浏览器随机代理
}
cookie = "u=185xbtfa; PClocation=287; u4ad=273ocdum; pcsuv=1580903692070.a.454844964; UM_distinctid=170153417e7dd-099a8ded8ef766-b383f66-144000-170153417e86d1; c=185xbtfb; pcLocate=%7B%22proCode%22%3A%22520000%22%2C%22pro%22%3A%22%E8%B4%B5%E5%B7%9E%E7%9C%81%22%2C%22cityCode%22%3A%22520100%22%2C%22city%22%3A%22%E8%B4%B5%E9%98%B3%E5%B8%82%22%2C%22dataType%22%3A%22user%22%2C%22expires%22%3A1583290353983%7D; pcautoLocate=%7B%22proId%22%3A26%2C%22cityId%22%3A287%2C%22url%22%3A%22%2F%2Fwww.pcauto.com.cn%2Fqcbj%2Fgy%2F%22%2C%22dataTypeAuto%22%3A%22user%22%7D; favCar=%E5%8D%A1%E7%BD%97%E6%8B%89_2734%7C%E6%9C%97%E9%80%B8_3225; pc_browsing_history=%7B%22id%22%3A2734%2C%20%22name%22%3A%22%E5%8D%A1%E7%BD%97%E6%8B%89%22%7D%7C%7B%22id%22%3A3225%2C%20%22name%22%3A%22%E6%9C%97%E9%80%B8%22%7D; locationddPro=%u8D35%u5DDE%u7701; cmu=mb49383348; visitedfid=16040D30987D18666D19145D30725D21855D19975; iwt_uuid=49400312-d6e0-4db2-8746-60926d754ee5; common_session_id=C3716A0B649C7CB3ED68D0574C6CB05B5D75FB0C9F1979555E47AA80D67D829B26911511FF02EF52; pcuvdata=lastAccessTime=1582078030478|visits=43; channel=3799; __PCautoMsg=%7B%22systemNoticeCount%22%3A%220%22%2C%22messageCount%22%3A%220%22%2C%22forumReplyCount%22%3A%220%22%2C%22dynaPraise%22%3A%220%22%2C%22commentReplyCount%22%3A%220%22%2C%22carReplyCount%22%3A%220%22%2C%22autoClubTaskCount%22%3A%220%22%2C%22lastUpdated%22%3A%221582078321041%22%7D"
# 将上面哪个cookie转化成字典类型
cookie_dict= {i.split("=")[0]:i.split("=")[-1] for i in cookie.split("; ")}
print (cookie_dict)
#创建CSV文件,并写入表头信息
fp = open('./太平洋汽车_朗逸轿车.csv','a',newline='',encoding='utf-8-sig')
writer = csv.writer(fp)
writer.writerow(('车主','发表时间','购买车型','购买时间','地点','价格','价格单位','平均油耗', '油耗单位','行驶里程(公里)', '外观评分', '内饰评分', '空间评分', '配置评分', '动力评分', '操控评分', '油耗评分', '舒适评分', '外观', '内饰', '空间', '配置', '动力', '操控', '油耗', '舒适'))
for page in range(25, 789):# 1, 789
comment_url = 'https://price.pcauto.com.cn/comment/sg1633/p%s.html'%page
time.sleep(random.uniform(1,3))#随机暂停1~3秒
response = requests.get(url=comment_url, headers=headers, cookies= cookie_dict).text
res_replace = response.replace('\r\n', '').replace('\t','').replace(' ','')
r = re.compile('(.*?)(.*?)发表.*?target="_blank">(.*?)<.*?购买时间(.*?).*?购买地点(.*?).*?裸车价格(.*?)(.*?).*?平均油耗(.*?)(.*?).*?行驶里程(.*?)公里.*?- 外观.*?(.*?)
- 内饰.*?(.*?)
- 空间.*?(.*?)
- 配置.*?(.*?)
- 动力.*?(.*?)
- 操控.*?(.*?)
- 油耗.*?(.*?)
- 舒适.*?(.*?).*?优点:(.*?).*?缺点:(.*?).*?外观:(.*?).*?内饰:(.*?).*?空间:(.*?).*?配置:(.*?).*?动力:(.*?).*?操控:(.*?).*?油耗:(.*?).*?舒适:(.*?)')
re_html = re.findall(r, res_replace)
# 写入数据
for index1 in range(len(re_html)):
txt = re_html[index1]
writer.writerow(txt)
print ("一共发现%s页,正在爬取第%s页"%(771, page))
fp.close() #关闭文件
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
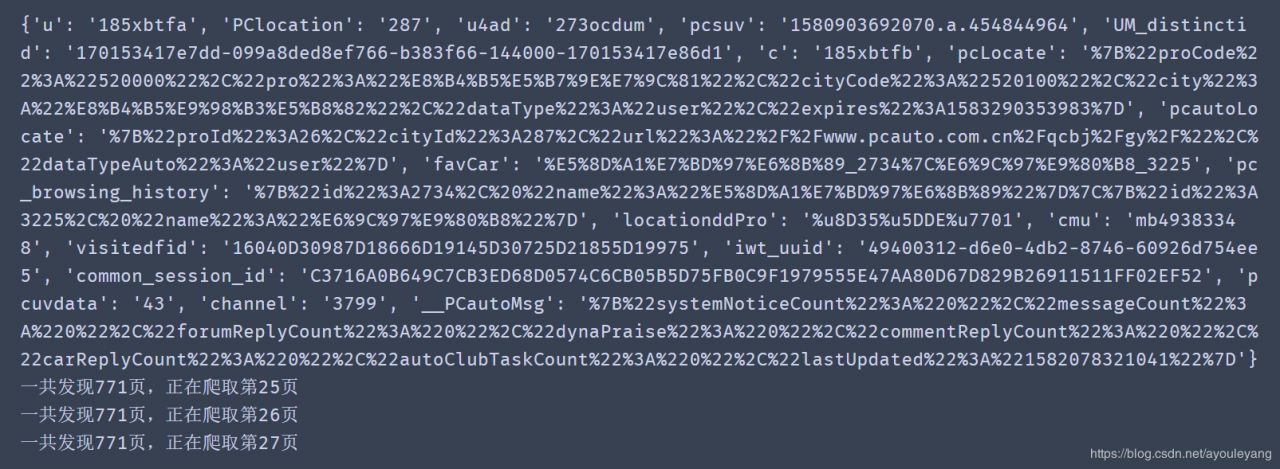
结论: 在短时间内,解决了不响应的假死状态,但是爬取的数量多了以后,它的cookie 也会被识别出来这是爬虫程序,不给予相应,所以,还得换其他的方法试试。
5、Selenium自动化爬取
这个是开发来做自动化测试的库,但是用它来做爬虫几乎是无敌的存在,就不多介绍它了,具体用法请转至 python爬虫爬取微博之战疫情用户评论及详情 观看 1.2.2.1、对selenium库的基本用法认识 和 1.2.2.2、认识xpath
5.1、自动登录《太平洋汽车》
上面写的代码总是会有各种各样的名称挂断,陷入假死状态出不来,于是我就用selenium 超控浏览器获取源码,传入 URL 模拟下拉,点击下一页,获取源码,本来以为可以高枕无忧时,代码又陷入假死状态了,被控制的浏览器也动不了了,后来注册了一个账号,用于登录网站获取 cookie 值, 然后赋予其他的链接进行爬取。
账号登录页面: https://my.pcauto.com.cn/passport/login.jsp?tag=1
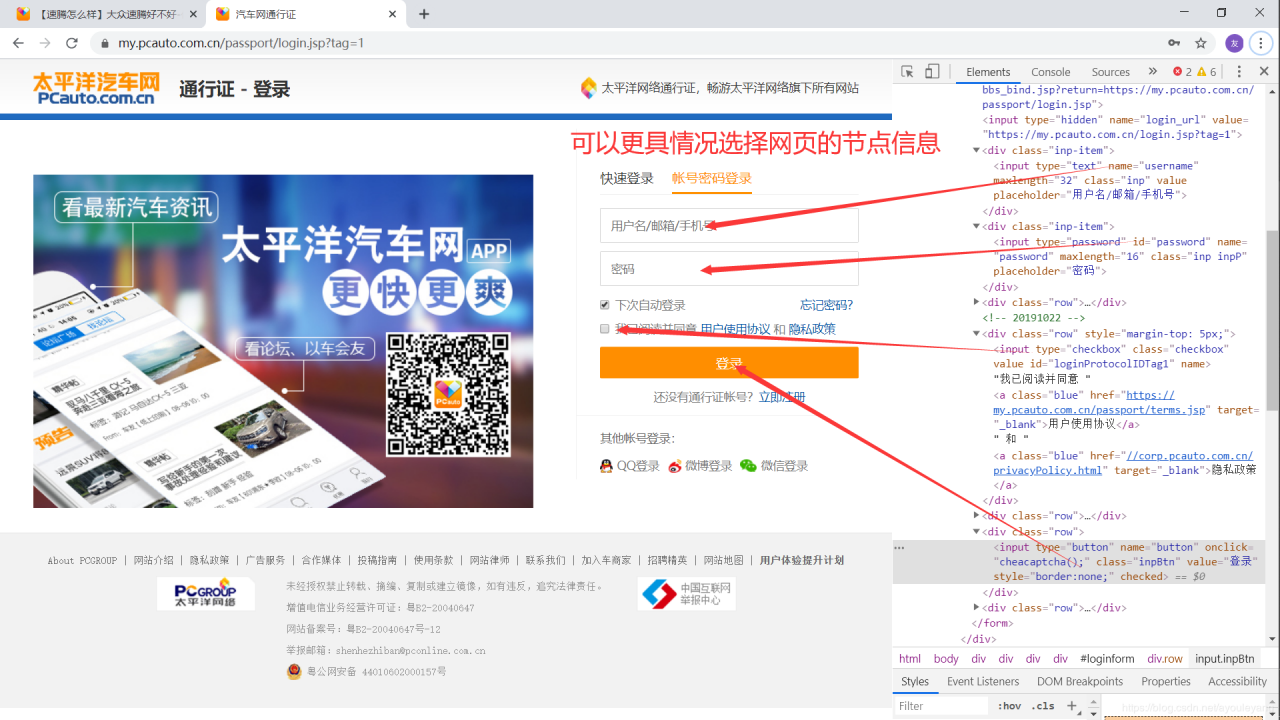
节点的具体选择方法可以参考 python爬虫爬取微博之战疫情用户评论及详情 的 第2节《实现登录微博》,实现登录账号源码如下:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import time
driver = webdriver.Chrome()
def logon_web():
# 打开浏览器链接
driver.get('https://my.pcauto.com.cn/passport/login.jsp?tag=1')
time.sleep(0.5)#暂停0.5秒
driver.find_element_by_id('loginProtocolIDTag1').click()#点击“我已阅读并同意 用户使用协议 和 隐私政策”框
driver.find_element_by_xpath('//*[@id="loginform"]/div[1]/input').send_keys('这里放你的账号') #输入账号
driver.find_element_by_id('password').send_keys('这里放你的密码') #输入密码
time.sleep(1)
driver.find_element_by_class_name('inpBtn').click()#点击登录按钮
time.sleep(1)
driver.find_element_by_xpath('//*[@id="chaMenu"]/span/a[1]').click() #点击左上角“LOGO”跳到官网首页
if __name__ == '__main__':
logon_web()
4.2、传入URL爬取信息
如果想要被控制的浏览器隐藏起来,可以把
driver = webdriver.Chrome()
改为:
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable-gpu')#上面三行代码就是为了将Chrome不弹出界面,实现无界面爬取
driver = webdriver.Chrome(chrome_options=chrome_options)
这样全程浏览器都是隐藏起来进行的,方便自己去做其他的工作。
源码汇总:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.options import Options
import time,eventlet,random
import re
import csv
startTime =time.time()#获取开始时的时间
login = "https://my.pcauto.com.cn/passport/login.jsp?tag=1"
#创建CSV文件,并写入表头信息
fp = open('./太平洋汽车_朗逸轿车.csv','a',newline='',encoding='utf-8-sig')
writer = csv.writer(fp)
writer.writerow(('车主','发表时间','购买车型','购买时间','地点','价格','价格单位','平均油耗', '油耗单位','行驶里程(公里)', '外观评分', '内饰评分', '空间评分', '配置评分', '动力评分', '操控评分', '油耗评分', '舒适评分', '外观', '内饰', '空间', '配置', '动力', '操控', '油耗', '舒适'))
driver = webdriver.Chrome()
def logon_web():
# 打开浏览器链接
driver.get(login)
time.sleep(0.5)#暂停0.5秒
driver.find_element_by_id('loginProtocolIDTag1').click()#点击“我已阅读并同意 用户使用协议 和 隐私政策”框
driver.find_element_by_xpath('//*[@id="loginform"]/div[1]/input').send_keys('这里放你的账号') #输入账号
driver.find_element_by_id('password').send_keys('这里放你的密码') #输入密码
time.sleep(1)
driver.find_element_by_class_name('inpBtn').click()#点击登录按钮
time.sleep(1)
driver.find_element_by_xpath('//*[@id="chaMenu"]/span/a[1]').click() #点击左上角“LOGO”跳到官网首页
#设置爬取的第一个网页,接下来的网页翻页它自己点击
comment_url = 'https://price.pcauto.com.cn/comment/sg1633/'#这是第一页
driver.get(comment_url)#打开网页网页
def spider(page):
#设置请求超时处理
eventlet.monkey_patch() #必须加这条代码
with eventlet.Timeout(10,False): #设置超时时间为5秒
for i in range(400,4500,900):
time.sleep(random.uniform(0, 0.5))#延时,模拟人为加载
js=f"document.documentElement.scrollTop={i}"#下拉加载,每次下拉900像素,数值必须叠加
driver.execute_script(js)#操作js
source = driver.page_source #1.直接获取源码
# source = driver.execute_script("return document.documentElement.outerHTML") #2.调用js获取源码
res_replace = source.replace('\r\n', '').replace('\t','').replace(' ','').replace('\n', '')
r = re.compile('(.*?)(.*?)发表.*?target="_blank">(.*?)<.*?购买时间(.*?).*?购买地点(.*?).*?裸车价格(.*?)(.*?).*?平均油耗(.*?)(.*?).*?行驶里程(.*?)公里.*?- 外观.*?(.*?)
- 内饰.*?(.*?)
- 空间.*?(.*?)
- 配置.*?(.*?)
- 动力.*?(.*?)
- 操控.*?(.*?)
- 油耗.*?(.*?)
- 舒适.*?(.*?).*?优点:(.*?).*?缺点:(.*?).*?外观:(.*?).*?内饰:(.*?).*?空间:(.*?).*?配置:(.*?).*?动力:(.*?).*?操控:(.*?).*?油耗:(.*?).*?舒适:(.*?)')
re_html = re.findall(r, res_replace)
return re_html
def push_url():
for page in range(1, 789):# 1, 789 #网页的点击次数
re_html = spider(page) #传入数字page返回提取的信息
for index1 in range(len(re_html)):#写入CSV
txt = re_html[index1]
writer.writerow(txt)
time.sleep(random.uniform(1.5, 2.5))#设置随机等待
driver.find_element_by_class_name('next').click() #点击下一页
print ("一共发现%s页,正在爬取第%s页:"%(789, page))
if __name__ == '__main__':
logon_web()
push_url()
fp.close() #关闭文件
driver.quit()#推出并关闭浏览器
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
爬取信息过程截图:
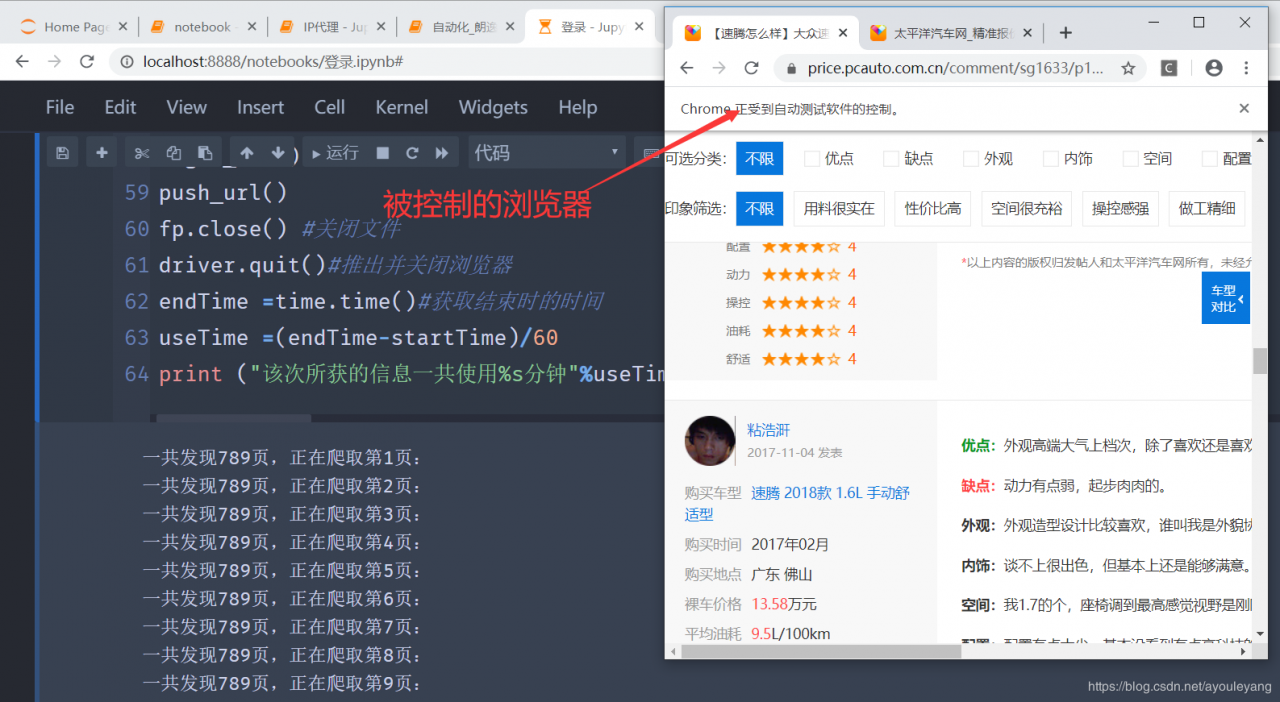
结论: 虽然爬到了自己需要的信息,但是它的寿命也不强,爬一段时间后也是会陷入假死状态,不在自动进行爬取下面的翻页爬取操作了,而且作为一个正真爬虫,是很少使用selenium 当作爬虫来使用的,所以,继续研究其他的方法吧
6、会话请求
经过上面一序列问题,我必须要改变一种方式了,就使用requests seesion建立会话吧,先用requests去提交我的账号和密码,登录网站,然后返回seesion,这里面就带上了本次访问后的所有信息,然后就用它去请求下一个页面,就相当于告诉服务器,现在我请求的链接是从上面一个链接跳转下来的,不信你可以查看我的通关文牒呀,seesion就是它的通关文牒,然后再设置随机暂停请求的时间长一点,这样就可以减少被反爬的概率了,甚至每隔20个停 30 ~ 60 秒钟,每请求下一个网页都停4 ~ 7秒,假装是人在 快速浏览网页。
6.1、如何使用requests提交账号和密码
先来抓包看看网页都提交了什么东西服务器,然后我们也这样提交给服务器,这样就实现账号的登录了,我们登录提交账号密码后服务器也会返回信息给我们,就相当于签发通关文牒了,只要记得每一关都要它发一个通关文牒, 接下来就可以用它畅行无忧啦~
抓包步骤: 打开登录页面——> 鼠标右击选择检查——> 输入密码账号点击登录按钮
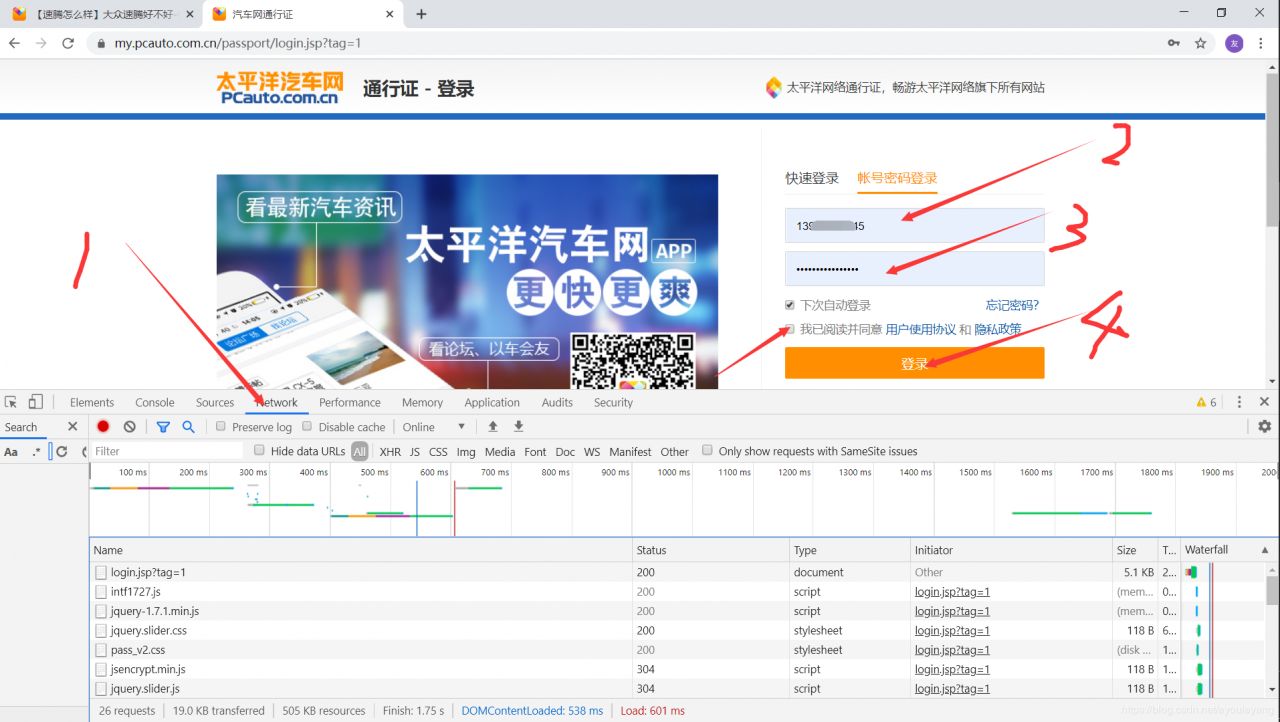
页面跳转到:
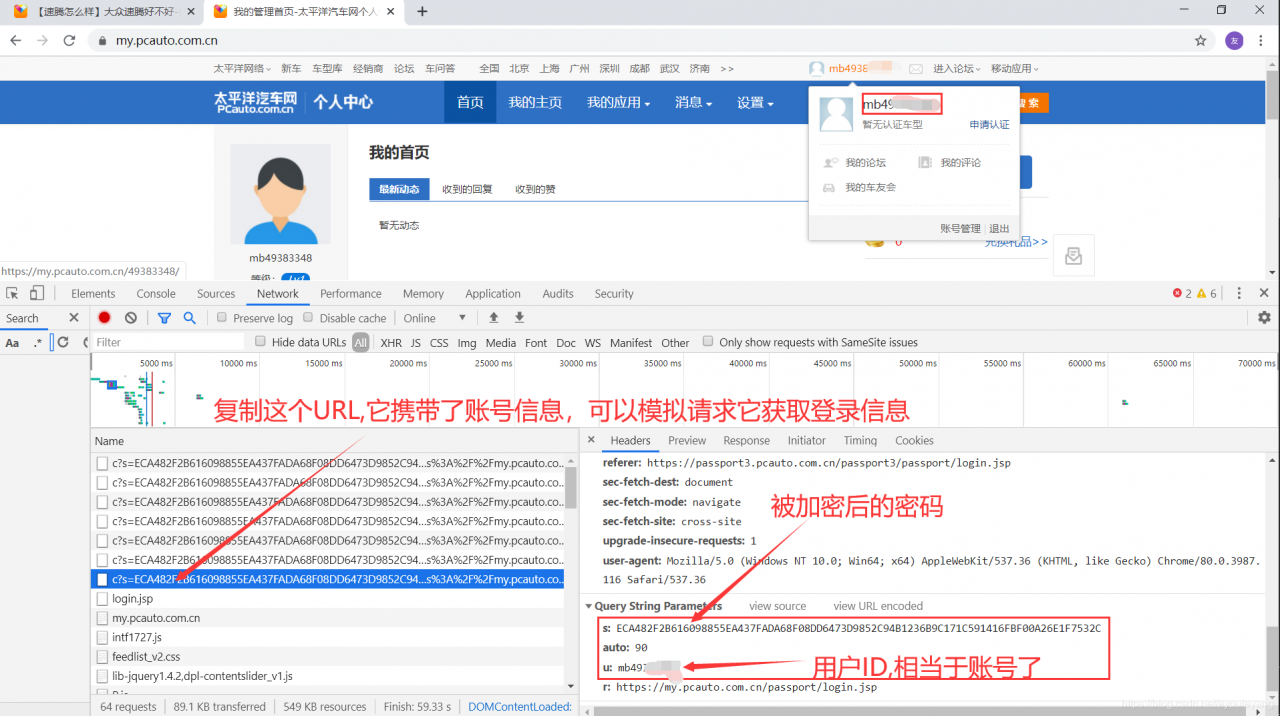
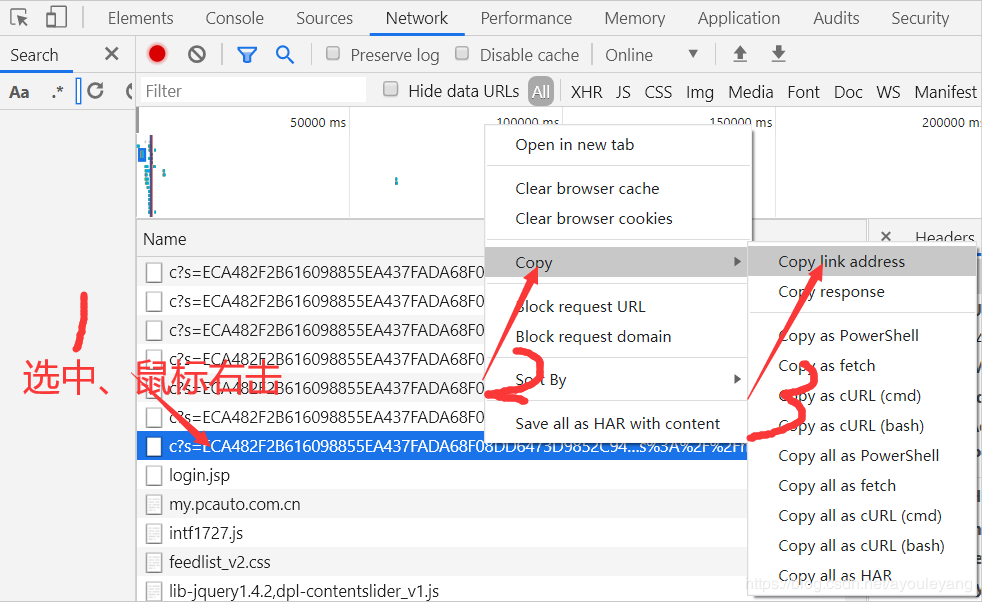
复制上面URL方法: 选中链接 ——> 鼠标右击 ——> copy ——> Copy Link address
实现源码:
import requests
def logon(login):
post_data = {
's': '9CF01B9F75975D555BE5407BACA68C04D76570DD88269DBE236B9C171C591416FBF00A26E1F7532C',#这里面放自己加密后的密码
'u': '这里放自己的ID',
'r': 'https://my.pcauto.com.cn/passport/login.jsp?tag=1'
}
seesion =requests.session()
seesion.get(url=login, headers =headers, data =post_data)
print ("=================完成登录================")
return seesion
login = 'https://passport3.geeknev.com/passport3/c?s=9CF01B9F75975D555BE5407BACA68C04D76570DD88269DBE236B9C171C591416FBF00A26E1F7532C&auto=90&u=mb49383348&r=https%3A%2F%2Fmy.pcauto.com.cn%2Fpassport%2Flogin.jsp'
seesion = logon(login)
print ("seesion = ", seesion)
=================完成登录================
seesion =
现在我们已经把第一个通关文牒办好了,开始过其他的关卡吧,并且在过的时候顺便把把下一关的通行证办理好,就畅通无阻了。为了减少被发现的次数,也可以弄一个假的身份去办理通关手续,这个通关手续就是代理IP啦。
6.2、源码汇总
import requests
import time
import re
import csv
import random
from fake_useragent import UserAgent
startTime = time.time()
#创建CSV文件,并写入表头信息
fp = open('./太平洋汽车_朗逸轿车12.csv','a',newline='',encoding='utf-8-sig')
writer = csv.writer(fp)
writer.writerow(('车主','发表时间 ','购买车型','购买时间','地点','价格','价格单位','平均油耗', '油耗单位','行驶里程(公里)', '外观评分', '内饰评分', '空间评分', '配置评分', '动力评分', '操控评分', '油耗评分', '舒适评分', '外观', '内饰', '空间', '配置', '动力', '操控', '油耗', '舒适'))
headers ={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"
}
ips = []
for i in range(1, 3):
print ("正在爬取IP使用代理,请稍等......")
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
ip_url = 'http://www.89ip.cn/index_%s.html'%i
res = requests.get(url=ip_url, headers=headers).text
res_re= res.replace('\n', '').replace('\t','').replace(' ','')
re_c = re.compile('(.*?) (.*?) ')
result = re.findall(re_c, res_re)
for i in range(len(result)):
ip = 'http://' + result[i][0] + ':' + result[i][1]
proxies={"http":ip}
html = requests.get('https://www.baidu.com/', proxies=proxies)
if html.status_code == 200:
ips.append(proxies)
print ("完成IP代理准备工作!!!")
def logon(login):
#需要提交的账号数据
post_data = {
's': '9CF01B9F75975D555BE5407BACA68C04D76570DD88269DBE236B9C171C591416FBF00A26E1F7532C',#这里放自己加密后的密码
'u': '这里放自己的ID',
'r': 'https://my.pcauto.com.cn/passport/login.jsp?tag=1'
}
#创建会话
seesion =requests.session()
seesion.get(url=login, headers =headers, data =post_data)
print ("=================完成登录================")
return seesion
def requests_url(seesion,comment_url):
"""请求网页,得到源码,提取信息,并重新创建新的会话,返回给下一个网页"""
time.sleep(random.uniform(3,5))#随机停3~5秒
response =seesion.get(url=comment_url, headers =headers, timeout=5, proxies=ips[random.randint(0 , len(ips)-1)]).text
seesion =requests.session()#重新创建会话
seesion.get(url=comment_url, headers =headers)
#替换掉干扰因子
res_replace = response.replace('\r\n', '').replace('\t','').replace(' ','')
#使用正则匹配出信息
r = re.compile(' (.*?)(.*?)发表.*?target="_blank">(.*?)<.*?购买时间(.*?).*?购买地点(.*?).*?裸车价格(.*?)(.*?).*?平均油耗(.*?)(.*?).*?行驶里程(.*?)公里.*?- 外观.*?(.*?)
- 内饰.*?(.*?)
- 空间.*?(.*?)
- 配置.*?(.*?)
- 动力.*?(.*?)
- 操控.*?(.*?)
- 油耗.*?(.*?)
- 舒适.*?(.*?).*?优点:(.*?).*?缺点:(.*?).*?外观:(.*?).*?内饰:(.*?).*?空间:(.*?).*?配置:(.*?).*?动力:(.*?).*?操控:(.*?).*?油耗:(.*?).*?舒适:(.*?)')
re_html = re.findall(r, res_replace)
# 写入数据
for index1 in range(len(re_html)):
txt = re_html[index1]
writer.writerow(txt)
return seesion
def push_url():
login = 'https://passport3.geeknev.com/passport3/c?s=9CF01B9F75975D555BE5407BACA68C04D76570DD88269DBE236B9C171C591416FBF00A26E1F7532C&auto=90&u=mb49383348&r=https%3A%2F%2Fmy.pcauto.com.cn%2Fpassport%2Flogin.jsp'
seesion = logon(login)#传入链接返回seesion
for page in range(342, 771):# 在这里控制页数
if (page%20) == 0:
time.sleep(random.uniform(30,50))
comment_url = 'https://price.pcauto.com.cn/comment/sg1633/p%s.html'%page
seesion = requests_url(seesion,comment_url)#传入上一个的seesion和下一个链接,并返回seesion
seesion = seesion
print ("一共发现%s页,正在爬取第%s页"%(771, page))
if __name__ == '__main__':
push_url()
fp.close() #关闭文件
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
这样的爬虫感觉已经很完美了,经过测试,实际效果也还是不错的,就是我把速度降得很慢了,防止被识别出来,各退一步吧。
7、爬取“朗逸”论坛信息
7.1、分析论坛首页
寻找目标: 可以在网页首页点击论坛,然后以 “朗逸” 为关键词搜索,一共可以找到50页以“朗逸” 关键词的目标。
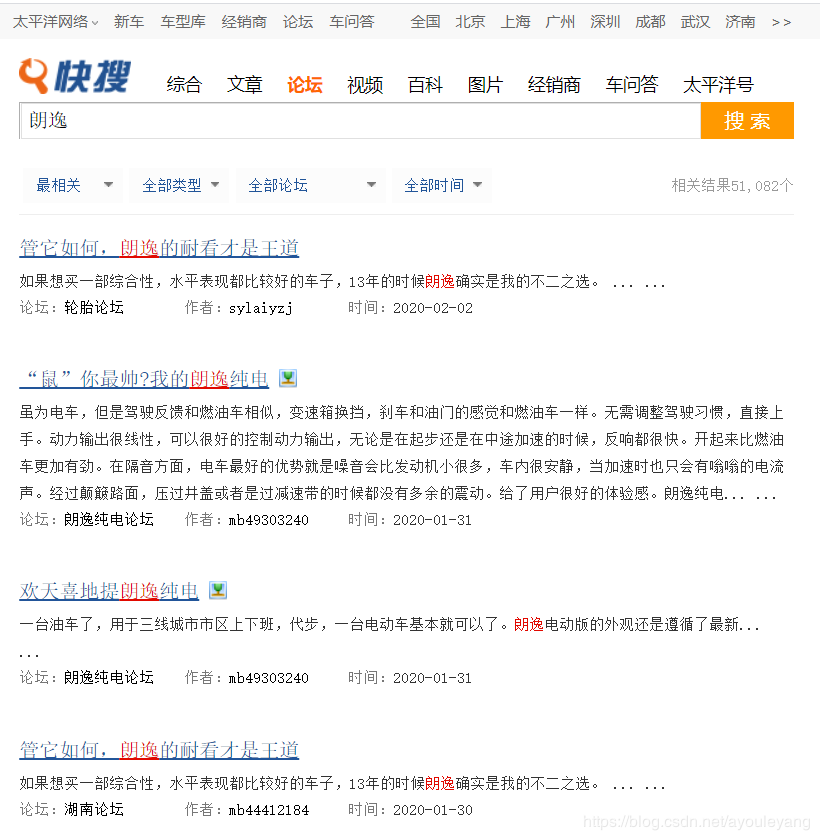
链接:
#第一页
https://ks.pcauto.com.cn/auto_bbs.shtml?q=%C0%CA%D2%DD&key=cms
#第二页
https://ks.pcauto.com.cn/auto_bbs.shtml?q=%C0%CA%D2%DD&key=cms&pageNo=2
#第三页
https://ks.pcauto.com.cn/auto_bbs.shtml?q=%C0%CA%D2%DD&key=cms&pageNo=3
#第四页
https://ks.pcauto.com.cn/auto_bbs.shtml?q=%C0%CA%D2%DD&key=cms&pageNo=4
可以也给第一页加上 &pageNo=1 ,这样也是可以正常访问浏览器的,知道了这50页URL的规律,接下来就可以使用循环自己生成了。
在论坛首页获取到每篇文章的内容,然后再分别访问它,这样就可以实现每篇文章及评论的爬取了。
先请求一点源码来分析看看,是否能拿到自己需要的内容
import requests
response = requests.get('https://ks.pcauto.com.cn/auto_bbs.shtml?q=%C0%CA%D2%DD&key=cms&pageNo=2').text
print (response)
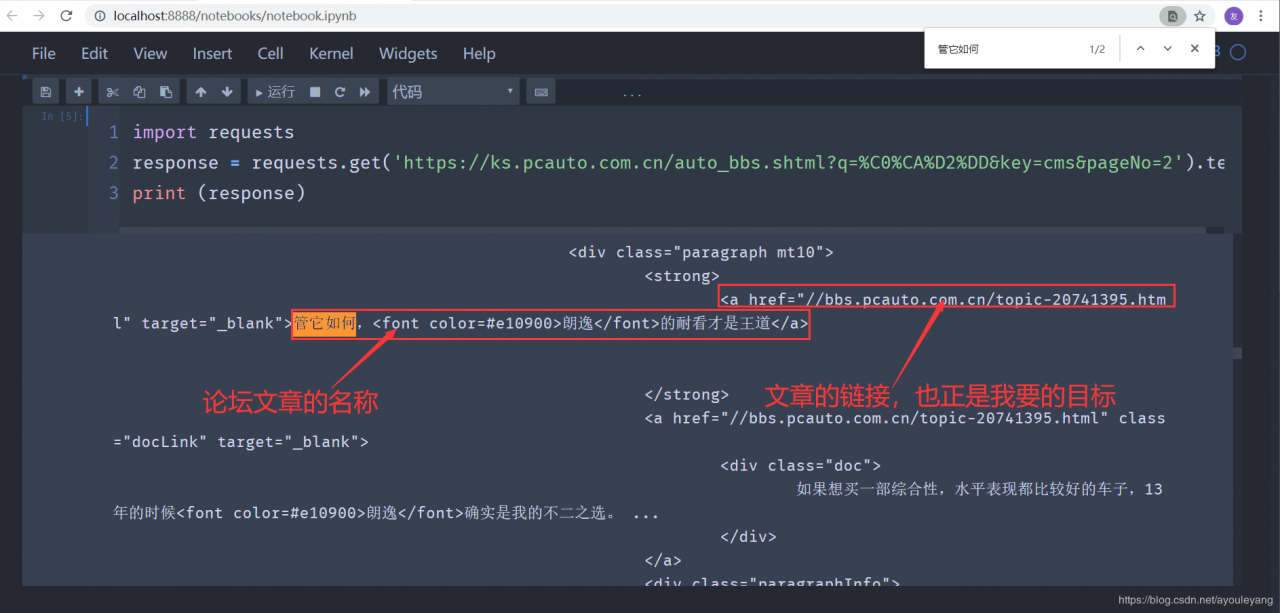
结论: 从上面的结果可以看出,这样页面没有任何发爬虫的措施,很轻松的就拿到了网页源码,接下来就是提取文章的链接了。
7.2、爬取论坛首页论题链接
7.2.1、如何定位xpath节点
步骤: 打开审查元素——> 点击左上角箭头图标——> 再去点击需要定位的位置 ——> HTML中 copy xpath
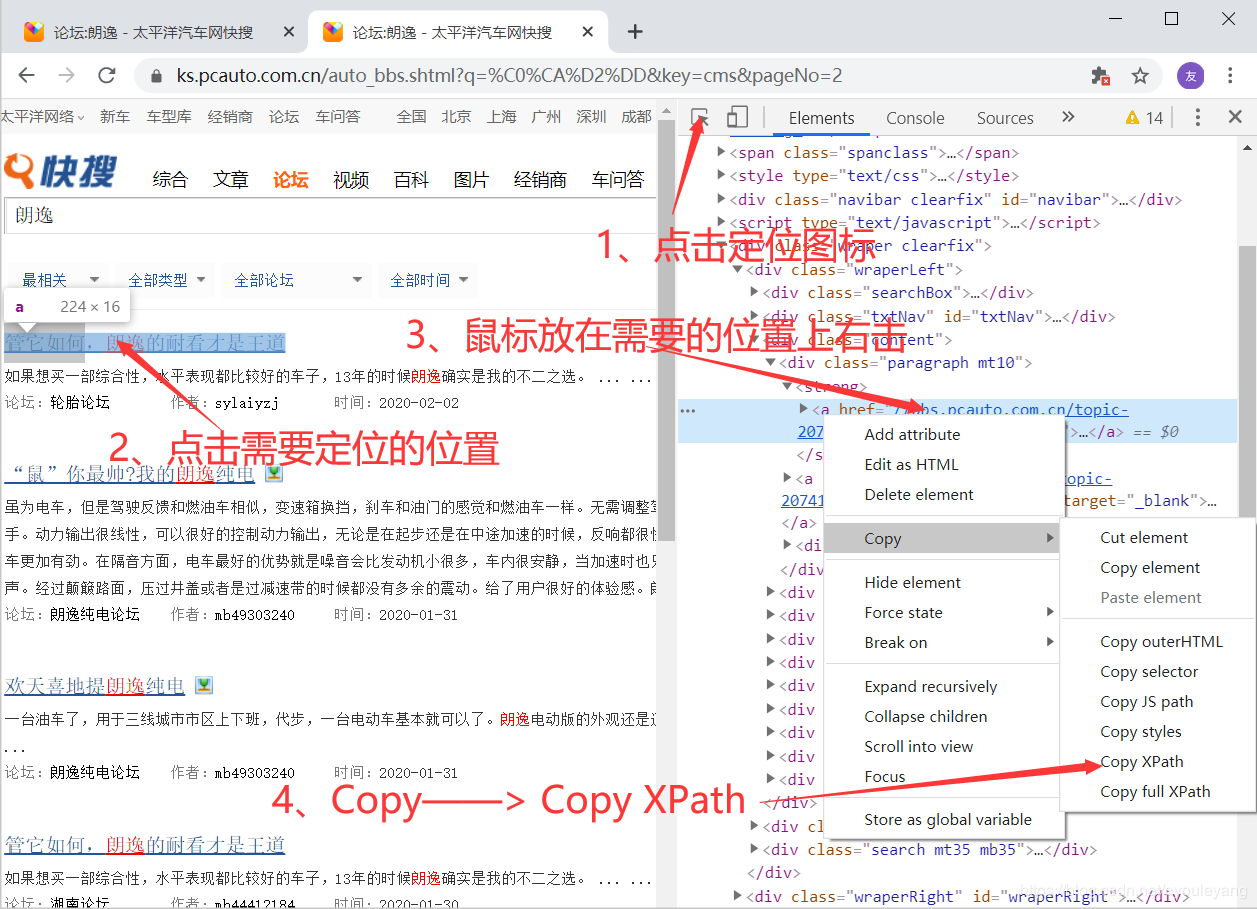
复制第一篇和第二篇文章的XPath进行比较
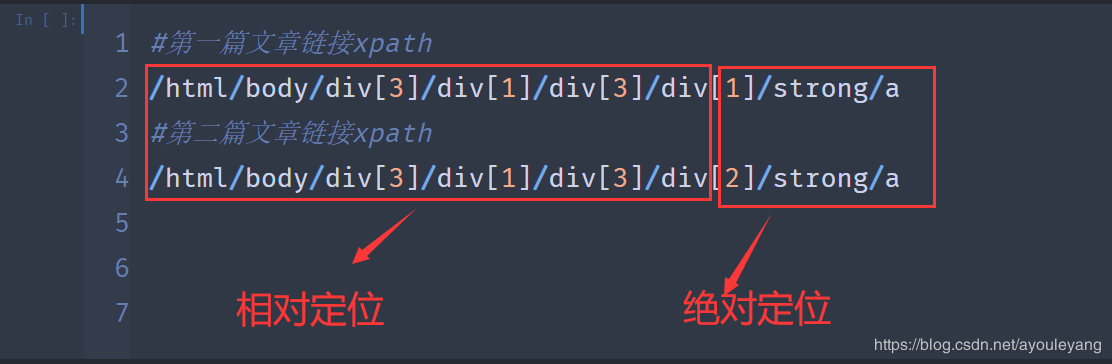
然后把它们分开使用:
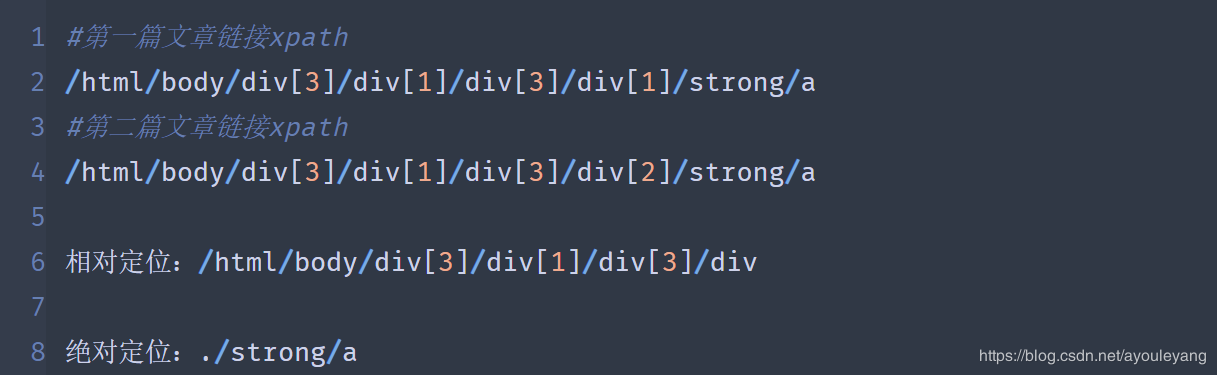
这种方法适合刚入门的同学使用,还可以直接用它的上一个节点来自己写 Xpath 节点,如改写为:
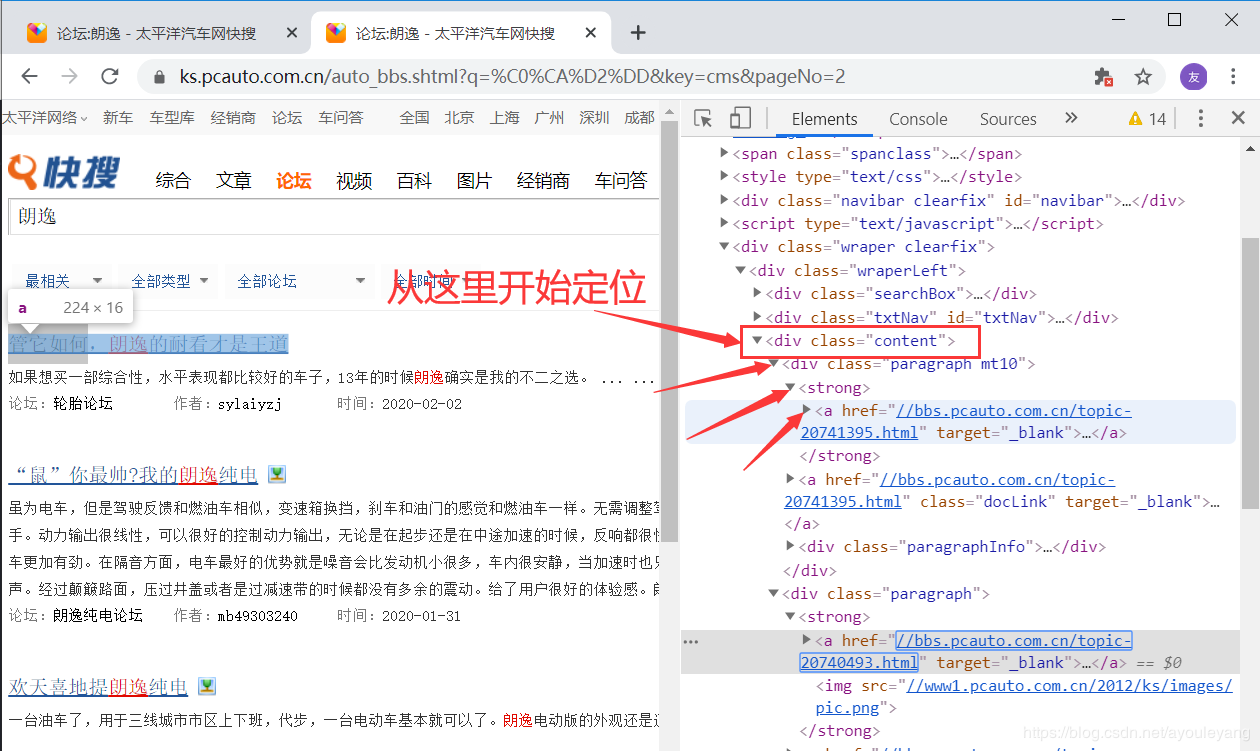
相对定位://div[@class="content"]/div/strong
绝对定位:./a
由于我要获取的是 href标签 内的内容,所以给绝对定位加上 /@href ,表示提取提取其中的内容
7.2.2、代码实现
import requests
from lxml import etree
response = requests.get('https://ks.pcauto.com.cn/auto_bbs.shtml?q=%C0%CA%D2%DD&key=cms&pageNo=2').text
html_etree = etree.HTML(response) #筛选器格式化
items = html_etree.xpath('//div[@class="content"]/div/strong')#相对定位
for item in items:
href = 'https:' + item.xpath('./a/@href')[0] #"https:" 拼接上a标签的内容,构成完整链接,[0]表示提取数组第一位
print (href)
结果:
https://bbs.pcauto.com.cn/topic-20741395.html
https://bbs.pcauto.com.cn/topic-20740493.html
https://bbs.pcauto.com.cn/topic-20740301.html
https://bbs.pcauto.com.cn/topic-20739602.html
https://bbs.pcauto.com.cn/topic-20739444.html
https://bbs.pcauto.com.cn/topic-20738669.html
https://bbs.pcauto.com.cn/topic-20736050.html
https://bbs.pcauto.com.cn/topic-20735451.html
https://bbs.pcauto.com.cn/topic-20734890.html
https://bbs.pcauto.com.cn/topic-20730428.html
提示: 加上翻页就可爬取它所有的链接了
这个网站就温柔很多了,没有发现它有反爬措施,为了安全起见,我也给请求信息加上了 IP 代理,这个步骤很上面的方法是一样的,直接Copy下来就可以用了。
7.3、BeautifulSoup筛选信息
注意这个Class标签,车主写的所有的文字都在 class="post_msg replyBody" 中
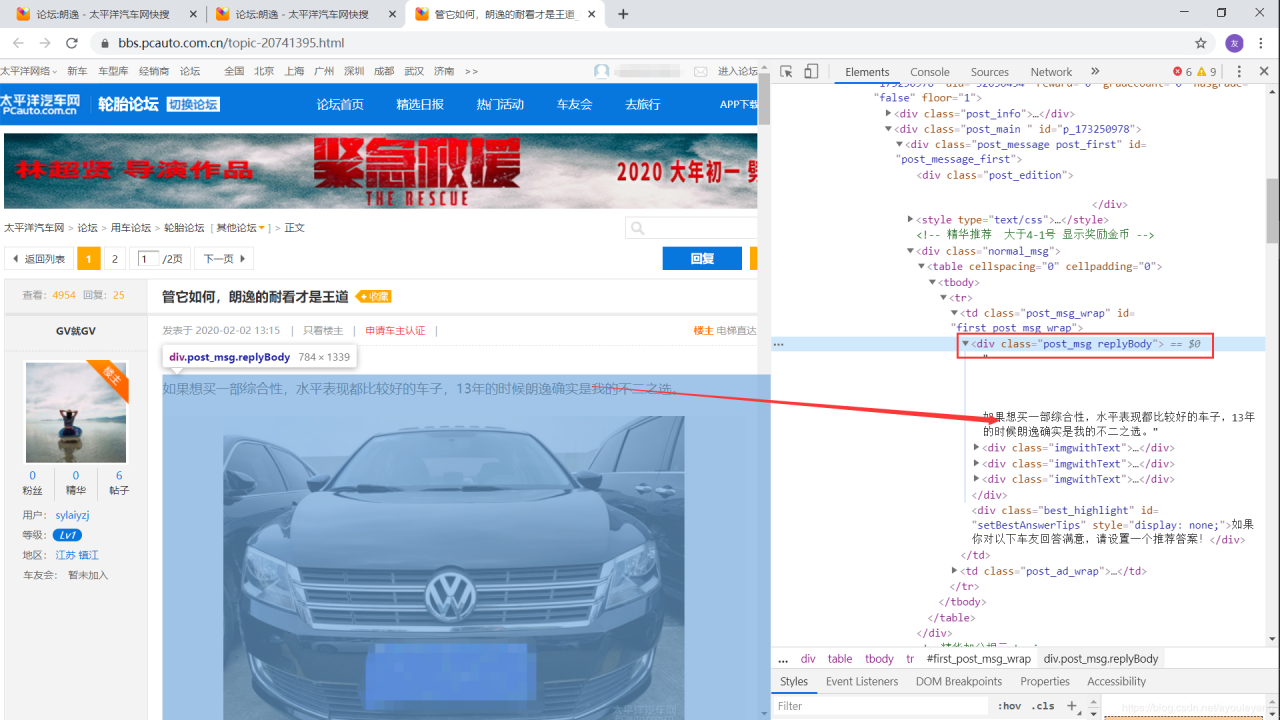
所有的回复都在 class="post_msg replyBody" 中:
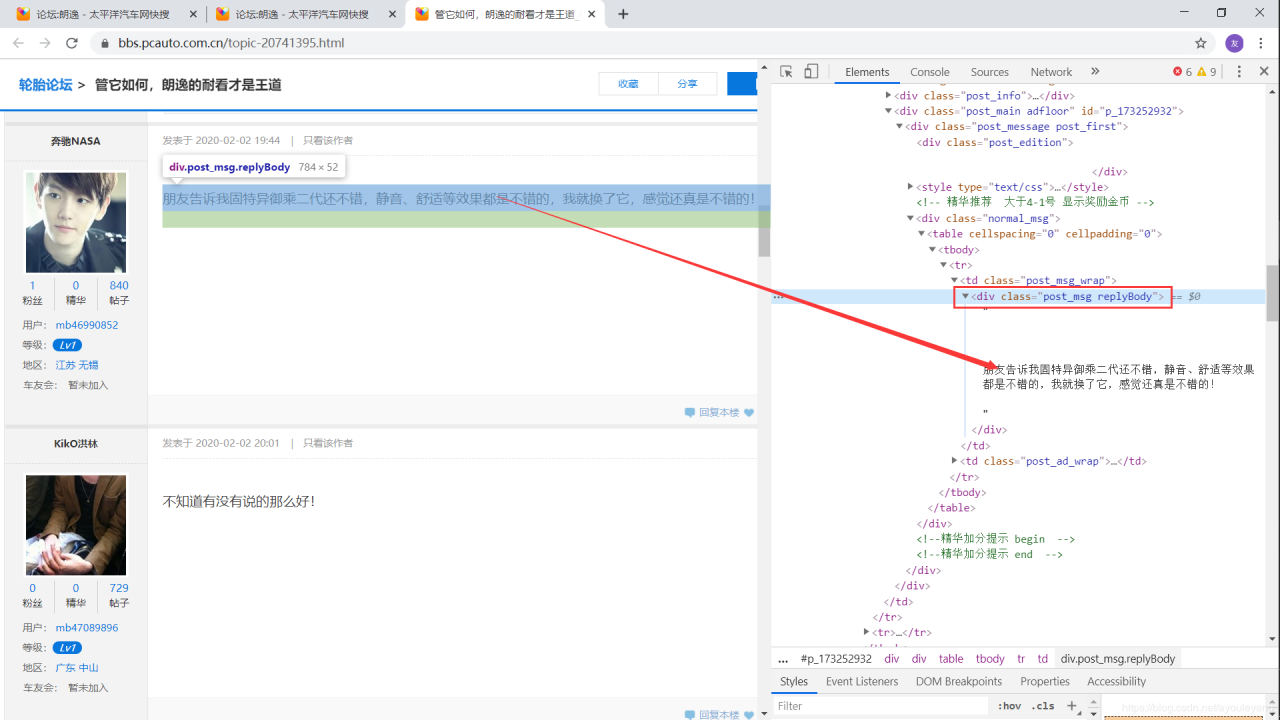
用法也相当的简单,这里就不详细讲了,我在代码中详细注释
7.4、把文本写入txt文件保存
这个可以分为三部曲,和把大象装进冰箱是一样的。
创建并打开文件
把内容写进去
关闭文件
看案例:
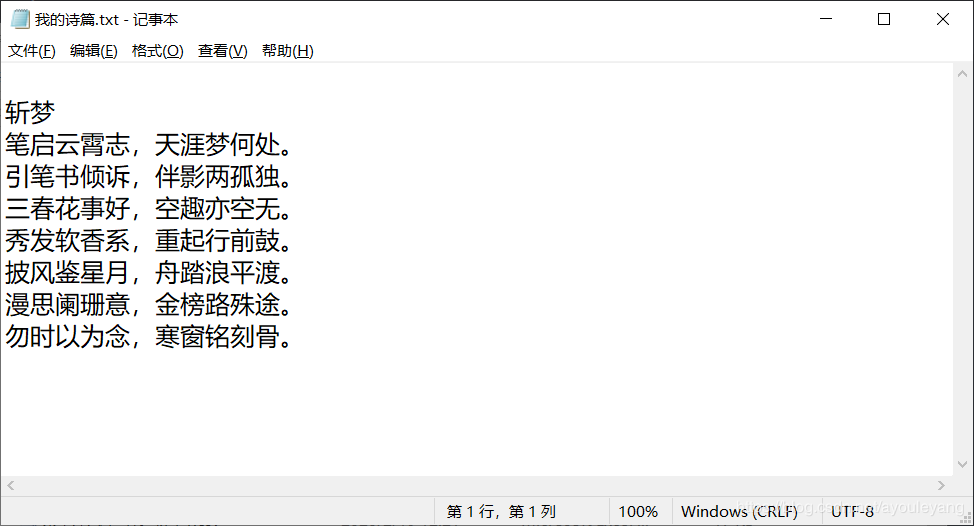
#假设有这样一段文本,其实这是我写的诗,嘿嘿!现在我要把它保存起来
poetry = """
斩梦
笔启云霄志,天涯梦何处。
引笔书倾诉,伴影两孤独。
三春花事好,空趣亦空无。
秀发软香系,重起行前鼓。
披风鉴星月,舟踏浪平渡。
漫思阑珊意,金榜路殊途。
勿时以为念,寒窗铭刻骨。
"""
#创建一个txt文件,以添加的方式写入内容,编码格式为utf-8
f = open('./我的诗篇.txt','a',encoding='utf-8') # "./"表示当前文件夹
f.write(poetry)
f.close()
结果:
7.5、论坛源码汇总
import requests
import time
import re
import random
from lxml import etree
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
startTime =time.time()#获取开始时的时间
f = open('./朗逸论坛.txt','a',encoding='utf-8')#创建一个txt文件,以添加的方式写入内容,编码格式为utf-8
ips = [] #装载有效IP
for i in range(1,5):#爬取前四页
print ("正在爬取IP第%s页使用代理,请稍等......"%i)
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
ip_url = 'http://www.89ip.cn/index_%s.html'%i #构造链接
res = requests.get(url=ip_url, headers=headers).text
res_re= res.replace('\n', '').replace('\t','').replace(' ','')
# 正则匹配提取信息
re_c = re.compile('(.*?) (.*?) ')
result = re.findall(re_c, res_re)
for i in range(len(result)):
ip = 'http://' + result[i][0] + ':' + result[i][1]
proxies={"http":ip}
#验证IP是否有用
html = requests.get('https://www.baidu.com/', proxies=proxies)
if html.status_code == 200:
ips.append(proxies)
"""下面这个部分分别为爬取首页链接,论题内容和回复,并保存数据"""
for page in range(1,51):#从第一个页面到第50个页面
headers = {
"User-Agent" : UserAgent().chrome #chrome浏览器随机代理
}
print ("================一共有50个主页面,正在爬取第%s个================"%page)
index_url = 'https://ks.pcauto.com.cn/auto_bbs.shtml?q=%C0%CA%D2%DD&key=cms&pageNo=' + str(page)
#设置异常捕捉,try,except
try:
response = requests.get(url=index_url, headers=headers, timeout=5, proxies=ips[random.randint(0 , len(ips)-1)]).text
html_etree = etree.HTML(response) #筛选器格式化
items = html_etree.xpath('//div[@class="content"]/div/strong')#相对定位
for item in items:
href = 'https:' + item.xpath('./a/@href')[0] #"https:" 拼接上a标签的内容,构成完整链接,[0]表示提取数组第一位
time.sleep(0.5) #暂停0.5秒
print (href) #打印链接
source = requests.get(url=href, headers=headers, timeout=5, proxies=ips[random.randint(0 , len(ips)-1)]).text
# 提取全部评论
soup = BeautifulSoup(source, "html.parser")#BeautifulSoup解析器格式化
msg = soup.find(attrs={"class": "post_msg replyBody"})#定位作者笔记
wraps = soup.find(attrs={"class": "post_msg_wrap"})#定位用户评论
txt = msg.get_text().replace("\n","") #get_text()表示提取文字
wrap = wraps.get_text().replace("\n","") #replace("\n","")表示替换掉换行
#把提取到的信息转化为字符型
txt = str(txt)
wrap = str(wrap)
#把信息写入txt文件
f.write(txt)
f.write(wrap)
except:
pass #发现异常就跳过
f.close()#完成后关闭文件
endTime =time.time()#获取结束时的时间
useTime =(endTime-startTime)/60
print ("该次所获的信息一共使用%s分钟"%useTime)
编辑器结果截图:
txt结果截图:

没有什么是一蹴而就的,所有的成果都是在 “零” 的基础上不断摸爬滚打的成果,愿你挺住,一门语言不从入门到放弃,相信它就可以陪你从入门到入土,加油!!!
作者:阿优乐扬