Python练习之读取XML节点和属性值的方法
面试题
有一个test.xml文件,要求读取该文件中products节点的所有子节点的值以及子节点的属性值。
test.xml文件:
<!-- products.xml -->
<root>
<products>
<product uuid='1234'>
<id>10000</id>
<name>苹果</name>
<price>99999</price>
</product>
<product uuid='1235'>
<id>10001</id>
<name>小米</name>
<price>999</price>
</product>
<product uuid='1236'>
<id>10002</id>
<name>华为</name>
<price>9999</price>
</product>
</products>
</root>
解析
# coding=utf-8
from xml.etree.ElementTree import parse
doc = parse('./products.xml')
print(type(doc))
for item in doc.iterfind('products/product'):
id = item.findtext('id')
name = item.findtext('name')
price = item.findtext('price')
uuid = item.get('uuid')
print('uuid={}, id={}, name={}, price={}'.format(uuid, id, name, price), end='\n----------\n')
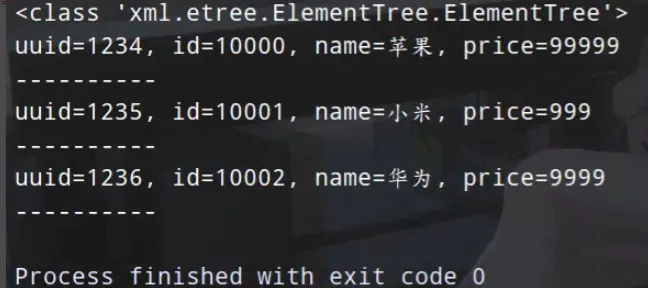
通过parse函数可以读取XML文档,该函数返回ElementTree类型的对象,通过该对象的iterfind方法可以对XML中特定节点进行迭代。
XML结构的独特,使得它很方便在任何应用程序中读和写数据,所以XML非常快就成为数据交换的唯一公共语言,虽然不同软件也支持其他的数据交换格式,但这并不影响,支持XML数据交换格式的应用程序可以十分容易的与windows,linux或者其他平台产生的信息结合,然后可以十分方便的加载XML数据到程序中并分析它,最后以XML格式输出结果。
不过细心的朋友应该能发现,这个格式的数据与我们在爬虫爬取数据时,未经处理的原始数据格式十分相像,甚至读取操作都几乎一模一样,有兴趣的朋友可以自行去搜索看看这两种数据格式的背景哦
到此这篇关于Python练习之读取XML节点和属性值的方法的文章就介绍到这了,更多相关Python读取XML内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!