python机器学习:推荐系统实现(以矩阵分解来协同过滤)
用户和产品的潜在特征编写推荐系统矩阵分解工作原理使用潜在表征来找到类似的产品。
1. 用户和产品的潜在特征我们可以通过为每个用户和每部电影分配属性,然后将它们相乘并合并结果来估计用户喜欢电影的程度。

然后我们使用pandas数据透视表函数来构建评论矩阵。在这一点上,ratings_df包含一个稀疏的评论阵列。

接下来,我们希望将数组分解以找到用户属性矩阵和我们可以重新乘回的电影属性矩阵来重新创建收视率数据。为此,我们将使用低秩矩阵分解算法。我已经在matrix_factorization_utilities.py中包含了这个实现。我们将在下一个视频中详细讨论它是如何工作的,但让我们继续使用它。首先,我们传递了评分数据,但是我们将调用pandas的as_matrix()函数,以确保我们作为一个numpy矩阵数据类型传入。
接下来,这个方法接受一个名为num_features的参数。 Num_features控制为每个用户和每个电影生成多少个潜在特征。我们将以15为起点。这个函数还有个参数regularization_amount。现在让我们传入0.1。在后面的文章中我们将讨论如何调整这个参数。
函数的结果是U矩阵和M矩阵,每个用户和每个电影分别具有15个属性。现在,我们可以通过将U和M相乘来得到每部电影的评分。但不是使用常规的乘法运算符,而是使用numpy的matmul函数,所以它知道我们要做矩阵乘法。
结果存储在一个名为predicted_ratings的数组中。最后,我们将predict_ratings保存到一个csv文件。
首先,我们将创建一个新的pandas数据框来保存数据。对于这个数据框,我们会告诉pandas使用与ratings_df数据框中相同的行和列名称。然后,我们将使用pandas csv函数将数据保存到文件。运行这个程序后可以看到,它创建了一个名为predicted_ratings.csv的新文件。我们可以使用任何电子表格应用程序打开该文件。
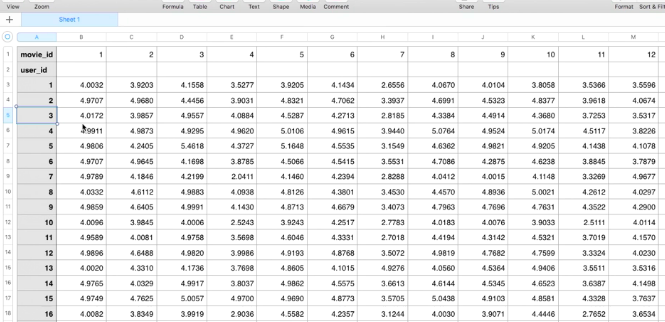
这个数据看起来就像我们原来的评论数据,现在每个单元格都填满了。现在我们评估下每个单个用户会为每个单独的电影评分。例如,我们可以看到用户3评级电影4,他们会给它一个四星级的评级。现在我们知道所有这些评分,我们可以按照评分顺序向用户推荐电影。让我们看看用户1号,看看我们推荐给他们的电影。在所有这些电影中,如果我们排除了用户以前评价过的电影,右边34号电影是最高分的电影,所以这是我们应该推荐给这个用户的第一部电影。当用户观看这部电影时,我们会要求他们评分。如果他们的评价与我们预测的不一致,我们将添加新评级并重新计算此矩阵。这将有助于我们提高整体评分。我们从中获得的评分越多,我们的评分阵列中就会出现的孔越少,我们就有更好的机会为U和M矩阵提供准确的值。
3. 矩阵分解工作原理因为评分矩阵等于将用户属性矩阵乘以电影属性矩阵的结果,所以我们可以使用矩阵分解反向工作以找到U和M的值。在代码中,我们使用称为低秩矩阵分解的算法,去做这个。我们来看看这个算法是如何工作的。矩阵分解是一个大矩阵可以分解成更小的矩阵的思想。所以,假设我们有一个大的数字矩阵,并且假设我们想要找到两个更小的矩阵相乘来产生那个大的矩阵,我们的目标是找到两个更小的矩阵来满足这个要求。如果您碰巧是线性代数的专家,您可能知道有一些标准的方法来对矩阵进行因式分解,比如使用一个称为奇异值分解的过程。但是,这是有这么一个特殊的情况下,将无法正常工作。问题是我们只知道大矩阵中的一些值。大矩阵中的许多条目是空白的,或者用户还没有检查特定的电影。所以,我们不是直接将评级数组分成两个较小的矩阵,而是使用迭代算法估计较小的矩阵的值。我们会猜测和检查,直到我们接近正确的答案。哎哎等等, 咋回事呢?首先,我们将创建U和M矩阵,但将所有值设置为随机数。因为U和M都是随机数,所以如果我们现在乘以U和M,结果是随机的。下一步是检查我们的计算评级矩阵与真实评级矩阵与U和M的当前值有多不同。但是我们将忽略评级矩阵中所有没有数据的点,只看在我们有实际用户评论的地方。我们将这种差异称为成本。成本就是错误率。接下来,我们将使用数字优化算法来搜索最小成本。数值优化算法将一次调整U和M中的数字。目标是让每一步的成本函数更接近于零。我们将使用的函数称为fmin_cg。它搜索使函数返回最小可能输出的输入。它由SciPy库提供。最后,fmin_cg函数将循环数百次,直到我们得到尽可能小的代价。当成本函数的价值如我们所能得到的那样低,那么U和M的最终值就是我们将要使用的。但是因为它们只是近似值,所以它们不会完全完美。当我们将这些U矩阵和M矩阵相乘来计算电影评级时,将其与原始电影评级进行比较,我们会看到还是有一些差异。但是只要我们接近,少量的差异就无关紧要了。
4. 使用潜在特征来找到类似的产品
搜索引擎是用户发现新网站的常用方式。当第一次用户从搜索引擎访问您的网站时,您对用户尚不足以提供个性化推荐,直到用户输入一些产品评论时,我们的推荐系统还不能推荐他们。在这种情况下,我们可以向用户展示与他们已经在查看的产品类似的产品。目标是让他们在网站上,让他们看更多的产品。你可能在网上购物网站上看到过这个功能,如果你喜欢这个产品,你可能也会喜欢这些其他的产品。通过使用矩阵分解计算产品属性,我们可以计算产品相似度。让我们来看看find_similar_products.py。首先,我们将使用pandas的读取CSV功能加载电影评级数据集。
我们还会使用read_csv将movies.csv加载到名为movies_df的数据框中。
然后,我们将使用pandas的数据透视表函数(pivot_table)来创建评分矩阵,我们将使用矩阵分解来计算U和M矩阵。现在,每个电影都由矩阵中的一列表示。首先,我们使用numpy的转置函数来触发矩阵,使每一列变成一行。

这只是使数据更容易处理,它不会改变数据本身。在矩阵中,每个电影有15个唯一的值代表该电影的特征。这意味着其他电影几乎相同的电影应该是非常相似的。要找到类似这个电影的其他电影,我们只需要找到其他电影的编号是最接近这部电影的数字。这只是一个减法问题。让我们选择用户正在看的主要电影,让我们选择电影ID5。
如果你喜欢,你可以选择其他的电影。现在,我们来看看电影ID5的标题和流派。我们可以通过查看movies_df数据框并使用pandas的loc函数通过其索引查找行来做到这一点。让我们打印出该电影的标题和流派。

接下来,让我们从矩阵中获取电影ID为5的电影属性。我们必须在这里减去一个,因为M是0索引,但电影ID从1开始。现在,让我们打印出这些电影属性,以便我们看到它们,这些属性我们准备好找到类似的电影。
第一步是从其他电影中减去这部电影的属性。这一行代码从矩阵的每一行中分别减去当前的电影特征。这给了我们当前电影和数据库中其他电影之间的分数差异。您也可以使用四个循环来一次减去一个电影,但使用numpy,我们可以在一行代码中完成。第二步是取我们在第一步计算出的差值的绝对值,numpy的ABS函数给我们绝对值,这只是确保任何负数出来都是正值。接下来,我们将每个电影的15个单独的属性差异合并为一个电影的总差异分数。 numpy的总和功能将做到这一点。我们还会传入访问权限等于一个来告诉numpy总结每行中的所有数字,并为每行产生一个单独的总和。在这一点上,我们完成了计算。我们只是将计算得分保存回电影列表中,以便我们能够打印每部电影的名称。在第五步中,我们按照我们计算的差异分数对电影列表进行排序,以便在列表中首先显示最少的不同电影。这里pandas提供了一个方便的排序值函数。最后,在第六步中,我们打印排序列表中的前五个电影。这些是与当前电影最相似的电影。
好的,我们来运行这个程序。 我们可以看到我们为这部电影计算的15个属性。这是我们发现的五个最相似的电影。第一部电影是用户已经看过的电影。 接下来的四部电影是我们向用户展示的类似项目。根据他们的头衔,这些电影看起来可能非常相似。他们似乎都是关于犯罪和调查的电影。续集,大城市法官三,都在名单上。这是用户可能也会感兴趣的电影。您可以更改电影ID并再次运行该程序,以查看与其他电影类似的内容。
作者:qq_19600291