Python机器学习之决策树
一、要求
二、原理
三、信息增益的计算方法
四、实现过程
五、程序
六、遇到的问题
一、要求
决策树是一种类似于流程图的结构,其中每个内部节点代表一个属性上的“测试”,每个分支代表测试的结果,每个叶节点代表一个测试结果。类标签(在计算所有属性后做出的决定)。从根到叶的路径代表分类规则。
决策树学习的目的是为了产生一棵泛化能力强,即处理未见示例能力强的决策树。因此如何构建决策树,是后续预测的关键!而构建决策树,就需要确定类标签判断的先后,其决定了构建的决策树的性能。决策树的分支节点应该尽可能的属于同一类别,即节点的“纯度”要越来越高,只有这样,才能最佳决策。
经典的属性划分方法:
信息增益
增益率
基尼指数
本次实验采用了信息增益,因此下面只对信息增益进行介绍。
三、信息增益的计算方法
其中D为样本集合,a为样本集合中的属性,Dv表示D样本集合中a属性为v的样本集合。
Ent(x)函数是计算信息熵,表示的是样本集合的纯度信息,信息熵的计算方法如下:

其中pk表示样本中最终结果种类中其中一个类别所占的比例,比如有10个样本,其中5个好,5个不好,则其中p1 = 5/10, p2 = 5/10。
一般而言,信息增益越大,则意味着使用属性α来进行划分所获得的“纯度提升”越大,因此在选择属性节点的时候优先选择信息增益高的属性!
四、实现过程本次设计用到了pandas和numpy库,主要利用它们来对数据进行快速的处理和使用。
首先将数据读入:
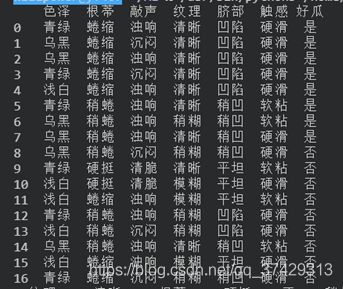
可以看到数据集的标签是瓜的不同的属性,而表格中的数据就是不同属性下的不同的值等。
if(len(set(D.好瓜)) == 1):
#标记返回
return D.好瓜.iloc[0]
elif((len(A) == 0) or Check(D, A[:-1])):
#选择D中结果最多的为标记
cnt = D.groupby('好瓜').size()
maxValue = cnt[cnt == cnt.max()].index[0]
return maxValue
else:
A1 = copy.deepcopy(A)
attr = Choose(D, A1[:-1])
tree = {attr:{}}
for value in set(D[attr]):
tree[attr][value] = TreeGen(D[D[attr] == value], A1)
return tree
TreeGen函数是生成树主函数,通过对它的递归调用,返回下一级树结构(字典)来完成生成决策树。
在生成树过程中,有二个终止迭代的条件,第一个就是当输入数据源D的所有情况结果都相同,那么将这个结果作为叶节点返回;第二个就是当没有属性可以再往下分,或者D中的样本在A所有属性下面的值都相同,那么就将D的所有情况中结果最多的作为叶节点返回。
其中Choose(D:pd.DataFrame, A:list)函数是选择标签的函数,其根据输入数据源和剩下的属性列表算出对应标签信息增益,选择能使信息增益最大的标签返回
def Choose(D:pd.DataFrame, A:list):
result = 0.0
resultAttr = ''
for attr in A:
tmpVal = CalcZengYi(D, attr)
if(tmpVal > result):
resultAttr = attr
result = tmpVal
A.remove(resultAttr)
return resultAttr
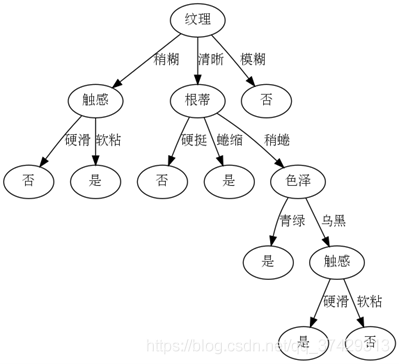
最后是结果:

{‘纹理': {‘稍糊': {‘触感': {‘硬滑': ‘否', ‘软粘': ‘是'}}, ‘清晰': {‘根蒂': {‘硬挺': ‘否', ‘蜷缩': ‘是', ‘稍蜷': {‘色泽': {‘青绿': ‘是', ‘乌黑': {‘触感': {‘硬滑': ‘是', ‘软粘': ‘否'}}}}}}, ‘模糊': ‘否'}}
绘图如下:
主程序
#!/usr/bin/python3
# -*- encoding: utf-8 -*-
'''
@Description:决策树:
@Date :2021/04/25 15:57:14
@Author :willpower
@version :1.0
'''
import pandas as pd
import numpy as np
import treeplot
import copy
import math
"""
@description :计算熵值
---------
@param :输入为基本pandas类型dataFrame,其中输入最后一行为实际结果
-------
@Returns :返回熵值,类型为浮点型
-------
"""
def CalcShang(D:pd.DataFrame):
setCnt = D.shape[0]
result = 0.0
# for i in D.groupby(D.columns[-1]).size().index:
#遍历每一个值
for i in set(D[D.columns[-1]]):
#获取该属性下的某个值的次数
cnt = D.iloc[:,-1].value_counts()[i]
result = result + (cnt/setCnt)*math.log(cnt/setCnt, 2)
return (-1*result)
"""
@description :计算增益
---------
@param :输入为DataFrame数据源,然后是需要计算增益的属性值
-------
@Returns :返回增益值,浮点型
-------
"""
def CalcZengYi(D:pd.DataFrame, attr:str):
sumShang = CalcShang(D)
setCnt = D.shape[0]
result = 0.0
valus = D.groupby(attr).size()
for subVal in valus.index:
result = result + (valus[subVal]/setCnt)*CalcShang(D[D[attr] == subVal])
return sumShang - result
"""
@description :选择最佳的属性
---------
@param :输入为数据源,以及还剩下的属性列表
-------
@Returns :返回最佳属性
-------
"""
def Choose(D:pd.DataFrame, A:list):
result = 0.0
resultAttr = ''
for attr in A:
tmpVal = CalcZengYi(D, attr)
if(tmpVal > result):
resultAttr = attr
result = tmpVal
A.remove(resultAttr)
return resultAttr
"""
@description :检查数据在每一个属性下面的值是否相同
---------
@param :输入为DataFrame以及剩下的属性列表
-------
@Returns :返回bool值,相同返回1,不同返回0
-------
"""
def Check(D:pd.DataFrame, A:list):
for i in A:
if(len(set(D[i])) != 1):
return 0
return 1
"""
@description :生成树主函数
---------
@param :数据源DataFrame以及所有类型
-------
@Returns :返回生成的字典树
-------
"""
def TreeGen(D:pd.DataFrame, A:list):
if(len(set(D.好瓜)) == 1):
#标记返回
return D.好瓜.iloc[0]
elif((len(A) == 0) or Check(D, A[:-1])):
#选择D中结果最多的为标记
cnt = D.groupby('好瓜').size()
#找到结果最多的结果
maxValue = cnt[cnt == cnt.max()].index[0]
return maxValue
else:
A1 = copy.deepcopy(A)
attr = Choose(D, A1[:-1])
tree = {attr:{}}
for value in set(D[attr]):
tree[attr][value] = TreeGen(D[D[attr] == value], A1)
return tree
"""
@description :验证集
---------
@param :输入为待验证的数据(最后一列为真实结果)以及决策树模型
-------
@Returns :无
-------
"""
def Test(D:pd.DataFrame, model:dict):
for i in range(D.shape[0]):
data = D.iloc[i]
subModel = model
while(1):
attr = list(subModel)[0]
subModel = subModel[attr][data[attr]]
if(type(subModel).__name__ != 'dict'):
print(subModel, end='')
break
print('')
name = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '好瓜']
df = pd.read_csv('./savedata.txt', names=name)
# CalcZengYi(df, '色泽')
resultTree = TreeGen(df, name)
print(resultTree)
# print(df[name[:-1]])
Test(df[name[:-1]], resultTree)
treeplot.plot_model(resultTree,"resultTree.gv")
绘图程序
from graphviz import Digraph
def plot_model(tree, name):
g = Digraph("G", filename=name, format='png', strict=False)
first_label = list(tree.keys())[0]
g.node("0", first_label)
_sub_plot(g, tree, "0")
g.view()
root = "0"
def _sub_plot(g, tree, inc):
global root
first_label = list(tree.keys())[0]
ts = tree[first_label]
for i in ts.keys():
if isinstance(tree[first_label][i], dict):
root = str(int(root) + 1)
g.node(root, list(tree[first_label][i].keys())[0])
g.edge(inc, root, str(i))
_sub_plot(g, tree[first_label][i], root)
else:
root = str(int(root) + 1)
g.node(root, tree[first_label][i])
g.edge(inc, root, str(i))
./savedata.txt
六、遇到的问题青绿,蜷缩,浊响,清晰,凹陷,硬滑,是
乌黑,蜷缩,沉闷,清晰,凹陷,硬滑,是
乌黑,蜷缩,浊响,清晰,凹陷,硬滑,是
青绿,蜷缩,沉闷,清晰,凹陷,硬滑,是
浅白,蜷缩,浊响,清晰,凹陷,硬滑,是
青绿,稍蜷,浊响,清晰,稍凹,软粘,是
乌黑,稍蜷,浊响,稍糊,稍凹,软粘,是
乌黑,稍蜷,浊响,清晰,稍凹,硬滑,是
乌黑,稍蜷,沉闷,稍糊,稍凹,硬滑,否
青绿,硬挺,清脆,清晰,平坦,软粘,否
浅白,硬挺,清脆,模糊,平坦,硬滑,否
浅白,蜷缩,浊响,模糊,平坦,软粘,否
青绿,稍蜷,浊响,稍糊,凹陷,硬滑,否
浅白,稍蜷,沉闷,稍糊,凹陷,硬滑,否
乌黑,稍蜷,浊响,清晰,稍凹,软粘,否
浅白,蜷缩,浊响,模糊,平坦,硬滑,否
青绿,蜷缩,沉闷,稍糊,稍凹,硬滑,否
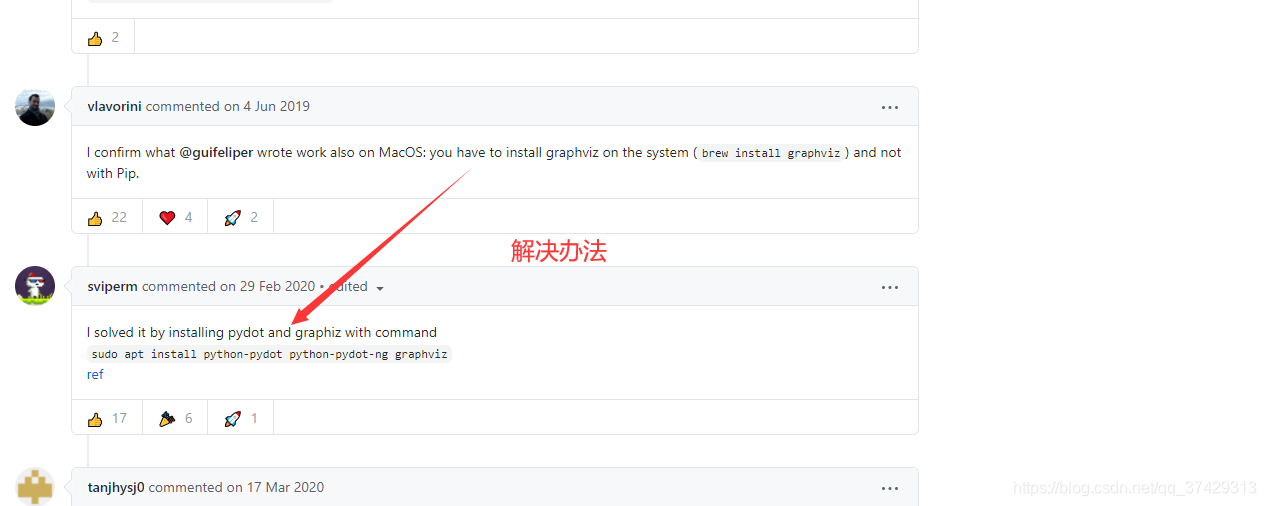
graphviz Not a directory: ‘dot'
解决办法
到此这篇关于Python机器学习之决策树的文章就介绍到这了,更多相关Python决策树内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!