Python的学习心得和知识总结(三)|Python基础(列表、元组、字典和集合)
2020年4月5日13:32:07
注:因为最近3天是清明节,中国以国家的名义纪念 在此次瘟疫中丧生的同胞。本人的这篇博客 全文将以 黑色和灰色 来书写,以谨记国殇。
接下来,我们学习新的知识 Python序列。
序列 什么是序列 列表(List)是什么 列表对象的常用方法列表对象的四种创建列表元素的增加删除列表元素的访问计数列表对象的切片操作列表元素的排序逆序列表相关的内置函数 多维列表(List的延伸) 二维列表 元组(Tuple)是什么元组的创建删除元组的访问计数元组的内置函数生成器推导式创建元组元组的内容小结 字典(Dictionary)是什么字典的创建删除字典的键值访问字典元素的增删字典的序列解包字典的数据存储字典的底层原理(存取) 集合(Set)是什么集合的创建删除集合的相关操作 什么是序列序列就是一种数据存储方式,用来存储一系列的数据。Python里面的序列结构主要有:字符串、列表、元组、字典和集合。 今天我们先学习列表和元组部分。
序列在内存之中 就是一块用来存放多个值的连续的内存空间。比如:一个整数序列[10,20,30,40],就可以表示为如下:【10】【20】【30】【40】,这是连续存放的。
注:之前学的字符串 也是序列的一种,因为它叫 字符序列:里面存的都是字符。 而列表可以存储任何类型的对象(列表可以是任意对象的序列)。即:字符串和列表都是序列类型,字符串是字符序列 列表是任何元素的序列。
而之前我们也说过:在Python里面 “一切皆对象”,因此在内存之中,a=[10,20,30,40] 实质的存储格式如下:
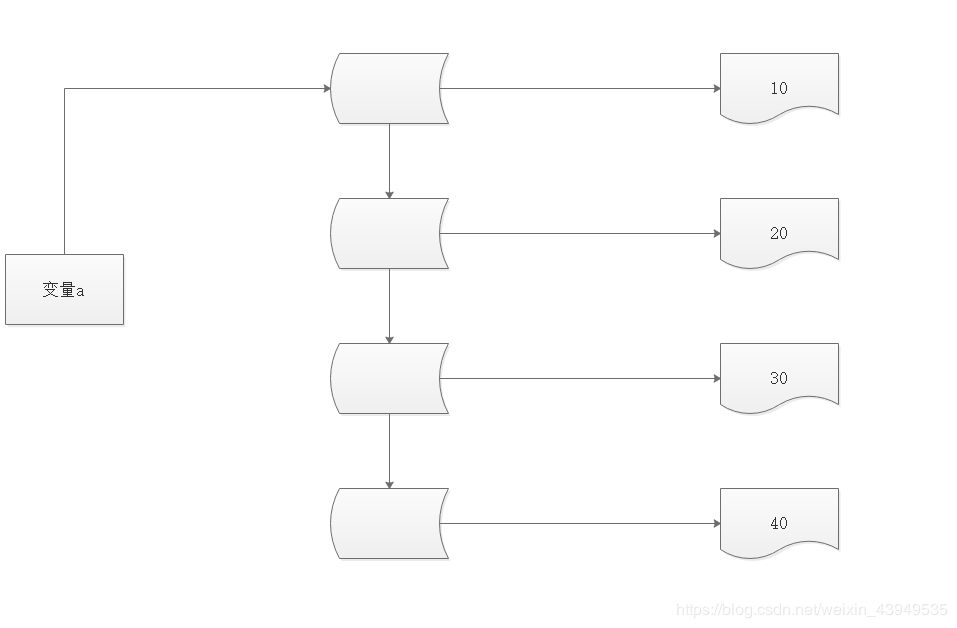
如上图 这个序列(准确的来说 是列表),【】里面存储了4个对象(也就是上图最右边的4个数字 对象);四个对象创建OK后,会把对象的ID 依次存在中间的四个空格里面(这4个是连续的地址空间);最后 整个列表也是一个对象,再把其地址 给到变量a。(最后变量a里面存储的就是列表的起始地址)也即:a[1] = 20.
列表是内置可变序列,是包含多个元素的有序且连续的内存空间(存储任意数目 任意类型的数据集合)。 列表的定义 标准语法格式如下所示:
a=[10,20,30,40]
里面的10 20 30 40倍称为是 列表a的元素。当然这4个元素都是数字,而我们的列表是可以存储任意类型的元素,如下也是可以的:
a=[10,20.0,‘China’,True]
注:列表对象的大小不是固定不变的,可以随着需要进行改变。如下:
列表对象的常用方法其背景如下:
>>> a=[10,20.0,'China',True]
>>> b=[11,21.0,'HeNan',True]
>>> a
[10, 20.0, 'China', True]
>>> b
[11, 21.0, 'HeNan', True]
>>>
增加元素
>>> a.append(1840) #将元素 1840 增加到列表a的尾部
>>> a
[10, 20.0, 'China', True, 1840]
>>> a.extend(b) #将列表b的全部元素 都续到列表a的尾部
>>> a
[10, 20.0, 'China', True, 1840, 11, 21.0, 'HeNan', True]
>>> b.insert(4,1942) #将在列表b的 指定位置 插入元素1942
>>> b
[11, 21.0, 'HeNan', True, 1942]
>>>
删除元素
>>> a
[10, 20.0, 'China', True, 1840, 11, 21.0, 'HeNan', True]
>>> a.remove(21.0) #在列表a里面删除 首次出现 的指定元素21.0
>>> a
[10, 20.0, 'China', True, 1840, 11, 'HeNan', True]
>>> len(a) #返回该列表里面元素的个数
8
>>> a.pop(7) #删除 并 返回该列表指定位置index处的元素。通常是最后一个元素
True
>>> a
[10, 20.0, 'China', True, 1840, 11, 'HeNan']
>>> b
[11, 21.0, 'HeNan', True, 1942]
>>> b.clear() #删除该列表里面所有元素 并不是删除我这个列表对象
>>> b
[]
>>>
查看元素
>>> b
[]
>>> b.index(1) #是返回该列表里面 1 这个值的第一次出现的索引位置。不存在则抛异常
Traceback (most recent call last):
File "", line 1, in
b.index(1)
ValueError: 1 is not in list
>>> a
[10, 20.0, 'China', True, 1840, 11, 'HeNan']
>>> a.index(1) #1 这个值是有的,True就是1.其索引位置为3 如下
3
>>> a[3]
True
>>>
>>> a
[10, 20.0, 'China', True, 1840, 11, 'HeNan']
>>> a.append(True)
>>> a
[10, 20.0, 'China', True, 1840, 11, 'HeNan', True]
>>> a.count(1) # 返回指定元素 1 出现的总次数
2
>>>
列表操作
>>> c=[5,3,4,1,2]
>>> c
[5, 3, 4, 1, 2]
>>> c.reverse() #该列表 所有元素原地翻转
>>> c
[2, 1, 4, 3, 5]
>>> c.sort() #列表元素 进行排序(默认从小到大)
>>> c
[1, 2, 3, 4, 5]
>>> d=c.copy() #copy做的是一个 浅拷贝
>>> d
[1, 2, 3, 4, 5]
>>>
列表对象的四种创建
一个列表对象的生成方式可以有以下四种:
基本语法[]创建 list()函数创建 range()函数创建 推导式生成列表OK,下面逐一进行列举:
使用[] 方式(最基本 最简单 最常见)来进行创建对象。
>>> c=[5,3,4,1,2]
>>> b=[] #创建空列表对象
>>> c
[5, 3, 4, 1, 2]
>>> b
[]
>>>
使用list()来创建对象:可以将任何可以迭代的数据转化为列表
>>> a=list() #创建一个空的列表对象
>>> a
[]
>>> b=list(range(10)) #传递数字 转化为列表对象
>>> b
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> list("我爱中国") #把字符串里面的字符 挨个转化到列表
['我', '爱', '中', '国']
>>>
range()创建整数列表:非常方便的创建整数列表对象
其语法格式为:
range(start,end,step)
start:表示起始数字,默认为0 optional
end :表示结尾数字 required ------------------>同样:包头不包尾,即不会有end的
step:表示步长,默认为1 optional
在Python3里面,range()返回的是一个 range对象(可迭代化的数据),而不是列表。如上面所示,我们可以借助于list()函数来将其转化成列表对象。实例如下:
>>> list(range(3,9,2)) #包头不包尾
[3, 5, 7]
>>> list(range(10,2,-1)) #步长-1 从【start,end) 即:倒着数
[10, 9, 8, 7, 6, 5, 4, 3]
>>> list(range(2,-10,-1)) #同上,只是结束直到 -9
[2, 1, 0, -1, -2, -3, -4, -5, -6, -7, -8, -9]
>>> list(range(2,2,-1)) #这也是倒着数 可是木有数据
[]
>>>
注:倒着数(步长为负) 需要start>end 才会有数据。 否则都会为空。
>>> list(range(-3,-11,-2))
[-3, -5, -7, -9]
>>>
解释上面: -3 > -10,然后步长为-2。因此开始数:第一个肯定为-3 顺着坐标轴往左走,包头不包尾 最后不要-11。
下面看一下 最后一种创建方法:推导式生成列表
使用列表推导式可以非常方便的创建列表(可以创建非常复杂的一些序列),且广泛使用于 for循环和if判断中。下面看一下一些实例:
>>> a=[i+1 for i in range(10)] #循环创建多个元素:0到9 执行表达式:1到10
>>> a
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
>>> a=[i*2 for i in range(10)] #循环创建多个元素:0到9 执行表达式:0到18
>>> a
[0, 2, 4, 6, 8, 10, 12, 14, 16, 18]
>>> a=[i*2 for i in range(100)if i%9==0] #循环创建多个元素:0到99 执行表达式。得到0 2 4--198,最后再用if进行过滤
>>> a
[0, 18, 36, 54, 72, 90, 108, 126, 144, 162, 180, 198]
>>>
列表元素的增加删除
之前也说了列表的内容不是固定不变的,当列表里面执行增加删除元素的时候 列表会自动的进行内存管理,这一点就极大的方便了程序开发工作。我们这里类比一下C语言里面的 数组(顺序存储结构),虽然Python会自动的进行内存的管理 但是效率问题是非常严重的(涉及到大量数据的移动 拷贝等)。当然 为了提高列表的操作效率,这也就限制(尽量)我们在列表尾部进行增删数据。
下面首先说一下增加的一些方法:
append()方法:原地修改列表对象,是真正的在列表尾部进行增加。其效率也就非常高(原地的意思:不创建新的列表对象)>>> a=[1,2]
>>> a
[1, 2]
>>> a.append("hello")
>>> a
[1, 2, 'hello']
>>> a.append(["world",True])
>>> a
[1, 2, 'hello', ['world', True]]
>>>
加法+运算符操作:它不是在尾部添加元素,而是创建新的列表对象。也就是将两个列表合并,将它俩里面的元素 依次都拷贝到新的列表对象里面。(涉及到大量的拷贝操作,不推荐使用于大量元素的场景)
>>> a=[2,8]
>>> b=["佳人"]
>>> id(a)
2714613982208
>>> a=a+b
>>> a
[2, 8, '佳人']
>>> id(a) #这里产生了新的列表对象
2714614348416
>>>
insert()插入元素:使用insert()、remove()、pop()、del()等函数的时候,若是操作的元素不是列表尾部的元素。那么就会涉及到被处理的指定元素的后面元素的 移动操作。这点也可以类比C语言进行学习。如下:
>>> a
[1, 2, 'hello', ['world', True]]
>>> a.insert(2,3)
>>> a
[1, 2, 3, 'hello', ['world', True]]
>>> a.remove(3)
>>> a
[1, 2, 'hello', ['world', True]]
>>> a.pop(1)
2
>>> a
[1, 'hello', ['world', True]]
>>>
乘法 X 的使用使用乘法是可以扩展列表的,进而来生成一个新的列表对象。这个新的对象是原列表元素的多次重复。
>>> a=[6]
>>> b=a*6
>>> a
[6]
>>> b
[6, 6, 6, 6, 6, 6]
>>>
这里小结一下:适用于乘法操作的有 字符串 列表 元组。
接下来说一下列表元素删除的一些方法:
del()函数:删除列表指定位置的元素。(也是后面元素值的向前覆盖) pop()函数:删除 并 返回指定位置的元素。若是未指定位置,则默认删除列表尾部元素>>> a=[1,2,3,4,5]
>>> a
[1, 2, 3, 4, 5]
>>> del a[1]
>>> a
[1, 3, 4, 5]
>>> a.pop()
5
>>> a
[1, 3, 4]
>>> a.pop(1)
3
>>> a
[1, 4]
>>>
remove()方法:删除首次出现的 指定元素。若是该元素不存在 则抛异常
>>> b=[2,4,5,6,7,2,3,4,5]
>>> b
[2, 4, 5, 6, 7, 2, 3, 4, 5]
>>> b.remove(4)
>>> b
[2, 5, 6, 7, 2, 3, 4, 5]
>>> b.remove(9)
Traceback (most recent call last):
File "", line 1, in
b.remove(9)
ValueError: list.remove(x): x not in list
>>>
看了上面的增加删除,其实质上都是一样的:都是数组元素的拷贝 移动。
列表元素的访问计数对于元素的访问,我们最常见的就是通过 下标。也就是索引 【0,len-1】,超出范围则抛异常。
下面我们讲一下 index()函数的使用,它可以获得指定元素在列表中 首次出现的索引位置。 其使用语法为:里面的start end是指定了搜索的范围,可以省略。
index(value,start,end)
如下:
>>> a=[1,2,3,4,5,5,4,3,2,1,1,2,3,4,5]
>>> a
[1, 2, 3, 4, 5, 5, 4, 3, 2, 1, 1, 2, 3, 4, 5]
>>> a.index(2)
1
>>> a.index(2,5,9)
8
>>> a.index(2,9)
11
>>>
使用count()函数 可以获得指定元素在列表中出现的次数;len()函数是返回列表里面元素个数
>>> a
[1, 2, 3, 4, 5, 5, 4, 3, 2, 1, 1, 2, 3, 4, 5]
>>> a.count(4)
3
>>>
注:使用上面的count 就可以判断一个元素是否存在于列表之中(返回值0 自然是不存在);但是我们也可以使用 in关键字来判断(返回True,False)。
>>> a.count(4)
3
>>> a
[1, 2, 3, 4, 5, 5, 4, 3, 2, 1, 1, 2, 3, 4, 5]
>>> 10 in a
False
>>> 4 in a
True
>>>
列表对象的切片操作
类似于前面字符串的切片操作,列表对象也有相应的切片操作。对于切片操作:其广泛使用于 列表、元组和字符串等。 其格式如下:
slice[起始偏移量start:终止偏移量end:步长step]
上面的step可以省略,下面是一些具体的实例:
同理,先演示三个量都是正数的情形:
背景如下:
>>> list=[10,20,30]
>>> list
[10, 20, 30]
| 操作和说明 | 例子 | 最终结果 |
|---|---|---|
| [:] 提取整个列表 | list[:] | [10, 20, 30] |
| [start:]从start索引处开始到结尾 | list[1:] | [20, 30] |
| [:end]从头到end-1处 | list[:2] | [10, 20] |
| [start:end]从start索引处开始到end-1 | [10, 20, 30, 40][1:3] | [20, 30] |
| [start: end :step]从start索引处开始到end-1,步长为step | [10, 20, 30, 40,50,60,70][1:6:2] | [20, 40, 60] |
下面看一下三个量都是负数的情形:
背景如下:
>>> list=[10,20,30,40,50,60,70]
>>> list
[10, 20, 30, 40, 50, 60, 70]
>>>
| 具体实例 | 实例说明 | 最终结果 |
|---|---|---|
| list[-3:] | 倒着数3个 | [50, 60, 70] |
| list[-5:-3] | 包头不包尾 倒数第五个到倒数第三个(不要) | [30, 40] |
| list[::-1] | 反向提取 | [70, 60, 50, 40, 30, 20, 10] |
注:当切片操作时,起始偏移量和终止偏移量 不在[0,len-1]时,也不会报错。因为起始偏移量 小于0会被处理为0;终止偏移量大于len-1会被当成取到最结尾。如下:
>>> list
[10, 20, 30, 40, 50, 60, 70]
>>> list[1:100]
[20, 30, 40, 50, 60, 70]
>>>
下面看一下列表对象的遍历:
>>> list
[10, 20, 30, 40, 50, 60, 70]
>>> for i in list:
print(i)
10
20
30
40
50
60
70
>>>
-----------------------------------
>>> list=[10, 20, 30, 40, 50, 60, 70]
>>> list
[10, 20, 30, 40, 50, 60, 70]
>>> for i in list:
print(i,end=' ')
10 20 30 40 50 60 70
>>>
列表元素的排序逆序
对于列表排序而言,存在两种:
修改原列表,不创建新的列表对象(这里是调用列表的sort方法)>>> a=[5,6,4,2,9,7,1,3]
>>> a
[5, 6, 4, 2, 9, 7, 1, 3]
>>> id(a)
1602872472128
>>> a.sort() #默认排序是 升序
>>> a
[1, 2, 3, 4, 5, 6, 7, 9]
>>> id(a)
1602872472128
>>> a.sort(reverse=True) #设置成降序
>>> a
[9, 7, 6, 5, 4, 3, 2, 1]
>>> id(a)
1602872472128
>>>
当然也可以打乱顺序,进行乱序 如下:
>>> a
[9, 7, 6, 5, 4, 3, 2, 1]
>>> id(a)
1602872472128
>>> import random
>>> random.shuffle(a) #打乱顺序
>>> a
[5, 1, 6, 2, 4, 9, 7, 3]
>>> id(a)
1602872472128
>>>
以上的排序 都没有创建新的列表对象。
创建一个新的列表对象需要使用上内置函数sorted()进行排序,这个方法 最后返回一个新的列表对象 而不修改原列表。
>>> a=[5,6,4,2,9,7,1,3]
>>> a
[5, 6, 4, 2, 9, 7, 1, 3]
>>> id(a)
2636370801408
>>> b=sorted(a) #内置函数,默认升序
>>> b
[1, 2, 3, 4, 5, 6, 7, 9]
>>> a
[5, 6, 4, 2, 9, 7, 1, 3]
>>> id(a)
2636370801408
>>> c=sorted(a,reverse=True) #也可以逆序
>>> c
[9, 7, 6, 5, 4, 3, 2, 1]
>>> id(a)
2636370801408
>>>
下面来看一下,内置函数reversed()支持逆序排列:
内置函数reversed()也支持进行逆序排序,不过 与上面列表对象的reverse()方法不同的是:前者只是返回一个逆序排列的迭代器对象。
>>> a=[5,6,4,2,9,7,1,3]
>>> a
[5, 6, 4, 2, 9, 7, 1, 3]
>>> id(a)
1510164808256
>>> b=reversed(a)
>>> b
#是一个翻转迭代器
>>> a
[5, 6, 4, 2, 9, 7, 1, 3]
>>> id(b)
1510172202176
>>> list(b) #使用list进行 转化为列表
[3, 1, 7, 9, 2, 4, 6, 5]
>>> list(b) #这个迭代器对象只能够用一次
[]
>>> a[::-1]
[3, 1, 7, 9, 2, 4, 6, 5]
>>>
列表相关的内置函数
max()、min()函数和sum()函数:
>>> a=[5,6,4,2,9,7,1,3]
>>> a
[5, 6, 4, 2, 9, 7, 1, 3]
>>> max(a)
9
>>> min(a)
1
>>> sum(a)
37
>>> b=["1",'0']
>>> sum(b)
Traceback (most recent call last):
File "", line 1, in
sum(b)
TypeError: unsupported operand type(s) for +: 'int' and 'str'
>>>
注:sum函数对于非数值型的列表进行 运算时,会报错 如上。
多维列表(List的延伸) 二维列表我们上面说的列表都指的是一维列表:存储一维的、线性的数据。作为延伸,二维列表主要是存储 表格的、二维的数据。如下:(网上找的图片,关键信息已被我涂掉)
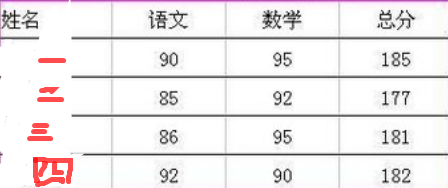
如何使用Python进行存储上面的数据呢?
>>> form=[
["一",90,95,185],
["二",85,92,177],
["三",86,95,181],
["四",92,90,182]
]
>>> form
[['一', 90, 95, 185], ['二', 85, 92, 177], ['三', 86, 95, 181], ['四', 92, 90, 182]]
>>> form[3]
['四', 92, 90, 182]
>>> form[3][3]
182
>>>
其内存结构如下:
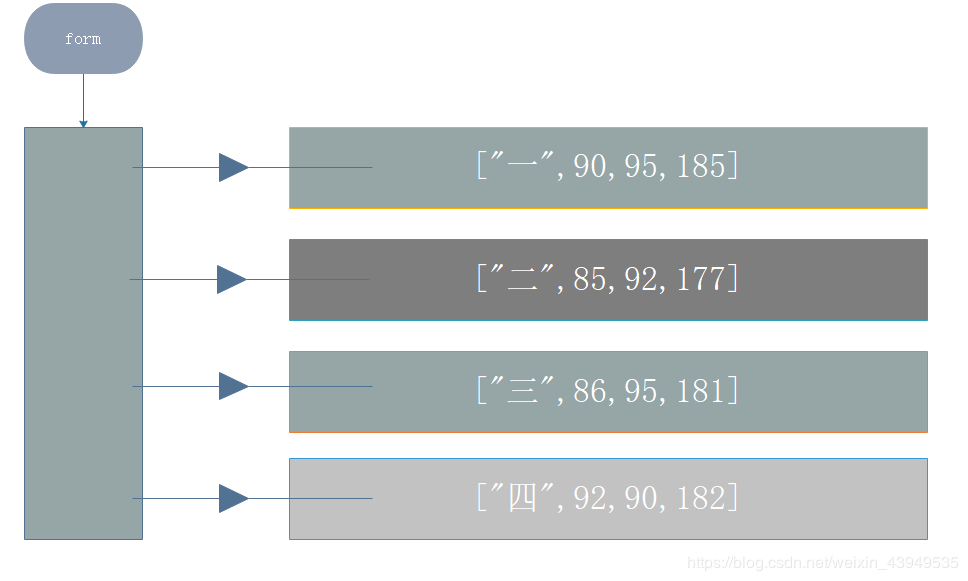
>>> for i in range(4):
for j in range(4):
print(form[i][j],end=' ')
print()
一 90 95 185
二 85 92 177
三 86 95 181
四 92 90 182
>>>
元组(Tuple)是什么
上面的列表是可变的序列(也即:可以任意修改列表里面的元素);而元组属于不可变序列,即:不能够修改元组中的元素。 因此,对于元组而言 也就少了增加删除修改元素等方法了。
元组的创建删除元组的创建有两种方式:
使用()来创建元组,小括弧可以省略>>> a=(1,2.3)
>>> type(a)
>>> b=1,2,3
>>> type(b)
>>>
但是,若是这个元组只有一个元素的时候,则后面必须加上逗号。
>>> a=(1) #这里 被解释成了 int
>>> a
1
>>> type(a)
--------------------------------------------
>>> b=(2,)
>>> type(b)
>>> b
(2,)
>>> c=3, #这种方式 省略小括弧 也是可以的
>>> c
(3,)
>>> type(c)
>>>
借助于tuple()创建元组:里面传递的参数为 可迭代的对象
>>> b=tuple() #创建一个空的元组对象
>>> b
()
>>> type(b)
>>> a=tuple('song') #下面是传入 可迭代化的对象
>>> a
('s', 'o', 'n', 'g')
>>> c=tuple(range(5))
>>> c
(0, 1, 2, 3, 4)
>>> d=tuple([1,2,3,4])
>>> d
(1, 2, 3, 4)
>>> e=tuple(list(range(10)))
>>> e
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
>>>
这里小结一下:
List:list()可以接收元组、字符串、迭代器对象和其他序列类型来 生成列表 List:tuple()可以接收列表、字符串、迭代器对象和其他序列类型来 生成元组元组的删除方式如下:(del 进行删除)
>>> e=tuple(list(range(10)))
>>> e
(0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
>>> type(e)
>>> del e
>>> e
Traceback (most recent call last):
File "", line 1, in
e
NameError: name 'e' is not defined
>>> type(e)
Traceback (most recent call last):
File "", line 1, in
type(e)
NameError: name 'e' is not defined
>>>
元组的访问计数
元组的元素是不可以被修改的,如下:
>>> c=tuple(range(5))
>>> c
(0, 1, 2, 3, 4)
>>> c[1]=11
Traceback (most recent call last):
File "", line 1, in
c[1]=11
TypeError: 'tuple' object does not support item assignment
>>>
但是访问是没有问题的,如下:
>>> c[1]
1
>>> c[1:3]
(1, 2)
>>> c[:4]
(0, 1, 2, 3)
>>> c[::-1]
(4, 3, 2, 1, 0)
>>>
注:如上 元组的元素访问和列表一样,只是这里返回的是元组对象。
元组的排序,如下:
元组排序不同于列表的排序方式:列表有自己的list.sort()方法 然而元组没有,所以元组要进行排序,只能使用内置函数sorted(tuple),并生成新的列表对象。 你没有看错,这里就是列表对象!
>>> t=(3,2,5,6,1,9,8)
>>> t
(3, 2, 5, 6, 1, 9, 8)
>>> newt=sorted(t)
>>> t
(3, 2, 5, 6, 1, 9, 8)
>>> newt
[1, 2, 3, 5, 6, 8, 9]
>>> type(t)
>>> type(newt)
>>>
元组的内置函数
>>> a=1,2
>>> b=3,1,4
>>> a+b
(1, 2, 3, 1, 4)
>>> len(a+b)
5
>>> max(a+b)
4
>>> min(a+b)
1
>>> sum(a+b)
11
>>>
下面看一下zip()方法 :将多个列表的对应位置的元素 合并成为元组,并返回这个zip对象。
>>> a=[1,3,5]
>>> b=[2,4,6]
>>> c=['s','j','z']
>>> d=zip(a,b,c)
>>> d
>>> list(d)
[(1, 2, 's'), (3, 4, 'j'), (5, 6, 'z')]
>>>
使用list()来使用其内容的时候(转化为列表),这个列表里面的每个元素都是一个元组。
生成器推导式创建元组从形式上来看,元组的生成器推导式 和 列表推导式类似,只是生成器推导式 使用小括弧。列表推导式直接生成列表对象;生成器推导式 生成的既非列表,亦非元组 而是生成器对象。
因此在进行遍历操作的时候, 我们可以如下去操作:
通过这个生成器对象,转化成列表 或者 元组 使用生成器对象的__next__()方法来遍历 直接作为迭代器对象使用注:无论是什么方式使用,元素遍历结束之后 这个生成器对象就无效了。若是需要再次重新访问该对象里面的元素,需要重新创建该生成器对象。
>>> g=(i+1 for i in range(5))
>>> type(g)
#这是一个生成器对象
>>> id(g)
1735374711488
>>> tuple(g)
(1, 2, 3, 4, 5)
>>> list(g) #只能够访问一次元素,第二次就空了,需要再生成一次
[]
>>> g=(i+1 for i in range(5))
>>> id(g)
1735375278816
>>> list(g)
[1, 2, 3, 4, 5]
>>> tuple(g) #只能够访问一次元素,第二次就空了,需要再生成一次
()
>>>
或者使用其next方法,如下:
>>> g=(i+1 for i in range(5))
>>> g.__next__()
1
>>> g.__next__()
2
>>> g.__next__()
3
>>> g.__next__()
4
>>> g.__next__()
5
>>> g.__next__() #这里已经没有内容了
Traceback (most recent call last):
File "", line 1, in
g.__next__()
StopIteration
>>>
元组的内容小结
元组的核心特点:它是不可变序列
元组的访问,以及处理的速度比列表要快
和整数、字符串一样,元组也是可以作为字典的键。而列表永远不能作为字典的键 (因为前三者都是不可变的)
那么什么是字典呢?
字典(Dictionary)是什么字典是 K-V的 无序的 可变序列,其中的每个元素都是一个键值对。(包含:键对象和值对象) 对于我们所熟知的键值对而言,Python这里就是通过“键对象”来实现快速获取 删除 更新其对应的“值对象”。
这里的键对象 是任意的不可变数据(整数、浮点数、字符串和元组),绝对不能是(列表、字典和集合)这些可变对象;此外 key不可以重复。 而值对象则可以是任何的数据,并且可以重复。下面来看一个典型的字典实例:
>>> d={"name":"宋宝宝",'age':22,"University":"清华大学"}
>>> d
{'name': '宋宝宝', 'age': 22, 'University': '清华大学'}
>>> type(d)
>>>
字典的创建删除
上面就已经展示了 使用{}进行创建字典对象。也可以通过dict()函数来创建,如下:
>>> d1={} #空的字典对象
>>> d2=dict() #空的字典对象
>>> type(d1)
>>> type(d2)
>>> d3=dict(name="宋宝宝",age=22,University="清华大学")
>>> d3
{'name': '宋宝宝', 'age': 22, 'University': '清华大学'}
>>> type(d3)
>>> d4=dict([("name",'宋宝宝'),("age",22),('University',"清华大学")])
>>> d4
{'name': '宋宝宝', 'age': 22, 'University': '清华大学'}
>>>
下面通过zip()函数来创建字典对象,如下:
>>> key=['name','age',"University"]
>>> value=['宋宝宝',22,'清华大学']
>>> z=zip(key,value)
>>> z
>>> type(z)
>>> d=dict(z)
>>> d
{'name': '宋宝宝', 'age': 22, 'University': '清华大学'}
>>> type(d)
>>> z
>>> d1=dict(z) #这个z 也是只能够使用一次
>>> d1
{}
>>>
下面通过 fromkeys()方法来创建value为空的 字典,如下:
>>> a=dict.fromkeys(['name','age',"University"]) #传入所有的键
>>> a
{'name': None, 'age': None, 'University': None}
>>>
字典的键值访问
背景如下:
>>> d={"name":"宋宝宝",'age':22,"University":"清华大学"}
>>> d
{'name': '宋宝宝', 'age': 22, 'University': '清华大学'}
>>> type(d)
>>>
使用键key,来访问值value。若是键不存在,则抛异常:
>>> d['name']
'宋宝宝'
>>> d['age']
22
>>> d['salary']
Traceback (most recent call last):
File "", line 1, in
d['salary']
KeyError: 'salary'
>>>
通过get()方法来得到值 建议使用,原因:指定键不存在的时候,返回None;或者也可以设置 返回默认的对象。
>>> d.get('University')
'清华大学'
>>> print(d.get('salary'))
None
>>> print(d.get('salary','Key salary is not existing')) #这里是 设置 返回默认的对象
Key salary is not existing
>>> print(d.get('name','Key name is not existing')) #人家存在,就返回其值
宋宝宝
>>>
下面是列出所有的键值对。列出所有的键、列出所有的值。如下:
>>> d={"name":"宋宝宝",'age':22,"University":"清华大学"}
>>> d
{'name': '宋宝宝', 'age': 22, 'University': '清华大学'}
>>> d.items()
dict_items([('name', '宋宝宝'), ('age', 22), ('University', '清华大学')])
>>> d.keys()
dict_keys(['name', 'age', 'University'])
>>> d.values()
dict_values(['宋宝宝', 22, '清华大学'])
>>>
计算键值对的个数、检测一个key是否存在于字典中。如下:
>>> d1={"name":"宋宝宝",'age':22,"University":"清华大学"}
>>> len(d1)
3
>>> 'age' in d1
True
>>> '666' in d1
False
>>> 22 in d1
False
>>>
字典元素的增删
给一个字典增加 键值对的时候,若键存在 则覆盖掉旧的K-V对;若不存在 则直接新增。
>>> d={"name":"宋宝宝",'age':22,"University":"清华大学"}
>>> d
{'name': '宋宝宝', 'age': 22, 'University': '清华大学'}
>>> d['age']=23
>>> d
{'name': '宋宝宝', 'age': 23, 'University': '清华大学'}
>>> d['score']=423
>>> d
{'name': '宋宝宝', 'age': 23, 'University': '清华大学', 'score': 423}
>>>
使用update()将 新的字典对象的全部K-V对都添加到旧的字典对象上面。若键存在(有重复) 则覆盖掉旧的K-V对
>>> d
{'name': '宋宝宝', 'age': 23, 'University': '清华大学', 'score': 423}
>>> d1={"sex":"纯爷们儿",'age':24}
>>> d.update(d1)
>>> d
{'name': '宋宝宝', 'age': 24, 'University': '清华大学', 'score': 423, 'sex': '纯爷们儿'}
>>>
字典中元素的删除,可以使用del()函数。clear()方法删除所有的键值对、pop()方法删除指定的键值对,并返回对应的“值对象”
>>> d={'name': '宋宝宝', 'age': 24, 'University': '清华大学', 'score': 423, 'sex': '纯爷们儿'}
>>> d
{'name': '宋宝宝', 'age': 24, 'University': '清华大学', 'score': 423, 'sex': '纯爷们儿'}
>>> del(d['name'])
>>> d
{'age': 24, 'University': '清华大学', 'score': 423, 'sex': '纯爷们儿'}
>>> a=d.pop('age')
>>> a
24
>>> d
{'University': '清华大学', 'score': 423, 'sex': '纯爷们儿'}
>>> d.clear()
>>> d
{}
popitem() 它是依次删除 并 返回该键值对。因为字典是 “无序可变序列”,它没有首尾元素的概念。popitem 是弹出随机的项,非常适用于 一个接一个移除并处理项。(因为无须首先获取键的列表)
>>> d={'name': '宋宝宝', 'age': 24, 'University': '清华大学', 'score': 423, 'sex': '纯爷们儿'}
>>> d
{'name': '宋宝宝', 'age': 24, 'University': '清华大学', 'score': 423, 'sex': '纯爷们儿'}
>>> d.popitem()
('sex', '纯爷们儿')
>>> d
{'name': '宋宝宝', 'age': 24, 'University': '清华大学', 'score': 423}
>>> d.popitem()
('score', 423)
>>> d
{'name': '宋宝宝', 'age': 24, 'University': '清华大学'}
>>> d.popitem()
('University', '清华大学')
>>> d
{'name': '宋宝宝', 'age': 24}
>>> d.popitem()
('age', 24)
>>> d
{'name': '宋宝宝'}
>>> d.clear()
>>> d
{}
>>>
字典的序列解包
序列解包可以使用在 元组、列表和字典之中(如下),它可以使得我们更加方便地对多个变量赋值。
>>> a,b=(1,2)
>>> a
1
>>> b
2
>>> (m,n)=(1,2)
>>> m
1
>>> n
2
>>> [x,y]=[1,2]
>>> x
1
>>> y
2
>>>
序列解包当用在字典身上的时候,默认是对 “key”进行的操作。若是需要对键值对操作,则需要使用items();若是需要对值操作,则需要使用values()。
>>> d={'name': '宋宝宝', 'age': 24, 'University': '清华大学', 'score': 423, 'sex': '纯爷们儿'}
>>> name,age,University,score,sex=d
>>> name #这个默认是对键 进行的操作
'name'
>>> age
'age'
>>> University
'University'
>>> score
'score'
>>> sex
'sex'
>>>
上面是默认操作,下面使用对象的方法来实现 对键值对或者值的操作:
>>> name,age,University,score,sex=d.items() #这是在对键值对
>>> name
('name', '宋宝宝')
>>> sex
('sex', '纯爷们儿')
>>> name,age,University,score,sex=d.values() #这时候 赋的值就是K-V的值value了
>>> age
24
>>> University
'清华大学'
>>>
字典的数据存储
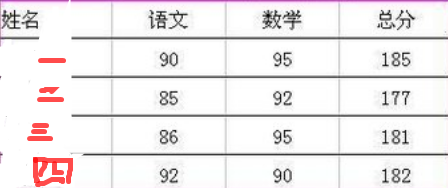
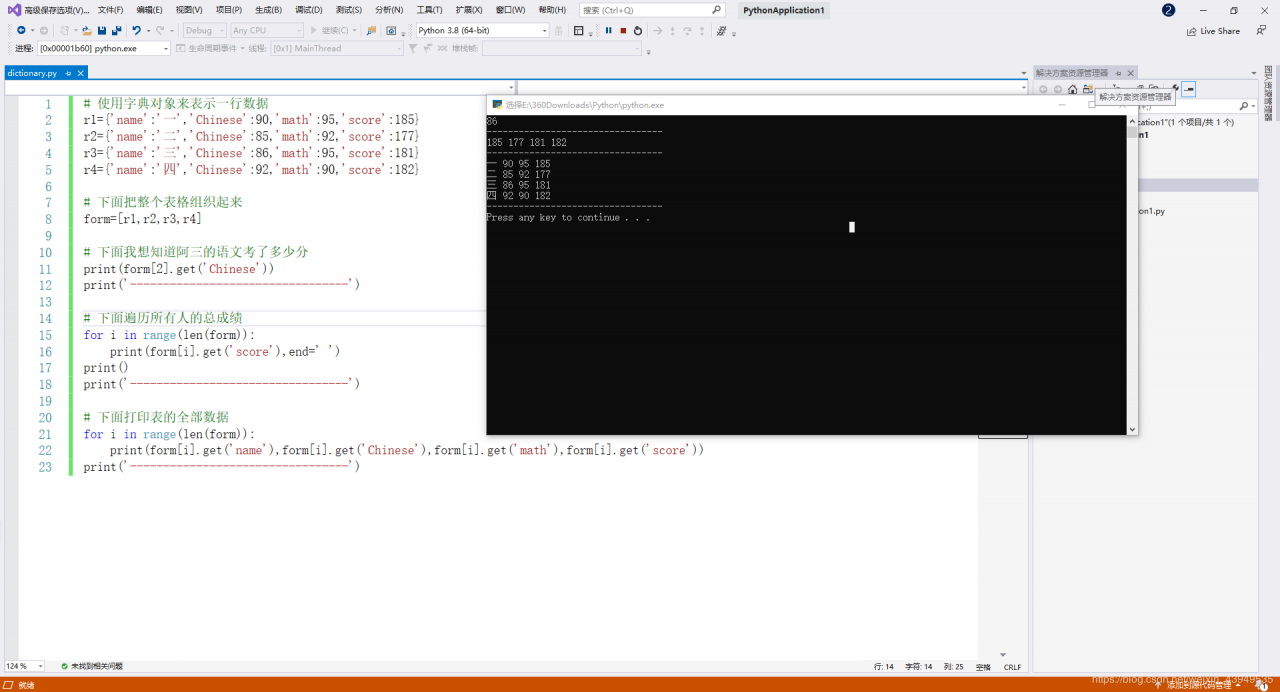
这是我们上面的一张图,下面的操作:表格数据使用字典和列表存储,并实现访问
代码如下:
# 使用字典对象来表示一行数据
r1={'name':'一','Chinese':90,'math':95,'score':185}
r2={'name':'二','Chinese':85,'math':92,'score':177}
r3={'name':'三','Chinese':86,'math':95,'score':181}
r4={'name':'四','Chinese':92,'math':90,'score':182}
# 下面把整个表格组织起来
form=[r1,r2,r3,r4]
# 下面我想知道阿三的语文考了多少分
print(form[2].get('Chinese'))
print('---------------------------------')
# 下面遍历所有人的总成绩
for i in range(len(form)):
print(form[i].get('score'),end=' ')
print()
print('---------------------------------')
# 下面打印表的全部数据
for i in range(len(form)):
print(form[i].get('name'),form[i].get('Chinese'),form[i].get('math'),form[i].get('score'))
print('---------------------------------')
字典对象的核心 就是散列表(Hash table)。哈希表也就是一个稀疏矩阵(里面总是有空白元素的数组),数组的每个单元叫做 桶(bucket)。每个桶也是由两部分组成:
键对象的引用 key ref 值对象的引用 value ref在组织结构和桶大小一致的情况下,我们可以通过偏移量 就可以对指定的桶进行读取。如下图(来自于网络)所示:
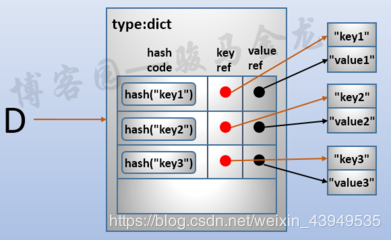
既然是要计算哈希值的,这就是为啥要求key 是不可变的数据。
第一部分:下面先看一下,如何将一个K-V对放入到字典里面:
背景如下:
>>> d={}
>>> type(d)
>>> d
{}
>>> d['name']='宋'
>>> bin(hash('name'))
'-0b110110110000000100101000011111111000101010111010000010100011100'
>>>
假设,字典对象创建完之后 稀疏矩阵的长度(数组)为8(其二进制表示1000):那么我们要把
d[‘name’]=‘宋’
这个键值对放到字典对象里面,以下步骤就是:
1、计算键的哈希值:bin(hash(‘name’)) 如上
2、我们可以这里算出来最右3位数:100 即4作为偏移量。注:主要8个桶 下标是0到7 这也就是为什么一次取3个二进制数字
3、就可以把这个键值对放到数组 下标为4的 地方(桶)里面。不过需要查看该桶是否为空,为空放里面;不为空,再取左边临近的3位 011,即3的 地方(桶)里面······ 一直到放入为止。若是全部找完都是满的,那么需要去进行 数组扩容(数组到达比例上限,将自动扩容)(8到16 32等,然后把旧的拷贝;之后取hash值的时候 就是4 5位的截取)
第二部分:下面看一下,如何从字典里面根据建来查找一个K-V对:
我们上面说的是 根据键对象的hash值,来确定应放置的桶的索引。而下面说的是 根据键对象的hash值来取出来值对象:
>>> d
{'name': '宋'}
>>> d.get('name')
'宋'
>>>
下面分解这个过程(调用get方法:根据键name来查找到键值对,从而找到其值对象‘宋’):
d.get(‘name’)
‘宋’
1、计算键对象name的hash值 就是上面存的时候的值HSA1
2、数组长度为8,因此取的时候 还是一次3位。拿出来最右边的3位100,即:偏移量4。
3、看这个桶里面是否为空:为空 则返回NONE;不为空 则将这个bucket的键对象取出来算hash值HSA2,和我们的HSA1值比较。
4、若是值一样,则匹配成功 就将对应的值对象返回。不相等 则依次再取临近的3位,计算hash值HSA3 重复上面的过程。
5、结果只有两种:找到 返回值对象; 找不到 返回NONE
第三部分:下面小结一下,字典的用法特点:
1、键对象必须是可以计算hash值的,如下:
@1:数字、字符串和元组 这些内置的类型
@2:自定义对象的话,需要满足3点:支持hash()函数;支持通过__eq__()方法来检测是否相等;若a==b为True,则hash(a)==hash(b) 也必须为真。
2、字典的用法是以空间换取时间的典型 其所占内存开销巨大;但是hash的优势:键对象的查询 快
3、往字典里面添加新键,可能会导致扩容。(之后hash表中 键的次序变化),注:不要在遍历字典的同时,进行字典的修改。 最好是:先遍历,把需要的取出来;然后再进行修改
集合set是无序可变的,里面元素不可以重复。实质上,集合的底层是由 字典来完成的。set的所有元素都是字典中的“键对象key”,因此它就可以保证不可重复的唯一性。
集合的创建删除第一部分:下面来看一下集合的创建方法:
1、使用{}来创建新的集合对象,使用add方法来添加元素:
>>> d={} #若是空的,这就成了 字典
>>> d
{}
>>> type(d)
>>> s={'政治','英语'} #这是集合
>>> s
{'英语', '政治'}
>>> type(s)
>>> s.add('数学','912') #add的时候 一次添加一个
Traceback (most recent call last):
File "", line 1, in
s.add('数学','912')
TypeError: add() takes exactly one argument (2 given)
>>> s.add('数学') #添加之后的顺序 是乱序的
>>> s
{'数学', '英语', '政治'}
>>> s.add(912)
>>> s
{'数学', '英语', 912, '政治'}
>>>
注:集合对象里面的元素是不可以重复的,倘若是 我使用add(912),集合里面是不会有两份912的。
2、使用set()函数来将 我们的 列表、元组等可迭代化的对象都转化成集合。若是之前元素存在着重复,则只保留一份。
>>> list=['数学', '英语', 912, '政治',912]
>>> list
['数学', '英语', 912, '政治', 912]
>>> set=set(list)
>>> set
{'数学', '英语', 912, '政治'}
>>>
第二部分:下面来看一下集合的删除方法:
主要是使用remove()来删除指定的元素;clear()来清空整个集合:
>>> set
{'数学', '英语', 912, '政治'}
>>> set.remove('政治')
>>> set
{'数学', '英语', 912}
>>> set.clear()
>>> set
set()
>>> type(set)
>>>
集合的相关操作
谈到集合,我们会想起来:什么 交 并 差等集合运算。背景如下:
>>> set1=set(range(5))
>>> set2=set((3,4,5,6,7))
>>> set1
{0, 1, 2, 3, 4}
>>> set2
{3, 4, 5, 6, 7}
>>> type(set1)
>>> type(set2)
>>>
1、并运算
>>> set1|set2
{0, 1, 2, 3, 4, 5, 6, 7}
---------------------------
>>> set1.union(set2)
{0, 1, 2, 3, 4, 5, 6, 7}
2、交运算
>>> set1&set2
{3, 4}
---------------------------
>>> set1.intersection(set2)
{3, 4}
3、差运算
>>> set1-set2
{0, 1, 2}
>>> set2-set1
{5, 6, 7}
---------------------------
>>> set2.difference(set1)
{5, 6, 7}
>>>
下面还有一些其他的操作:
>>> set1&set1
{0, 1, 2, 3, 4}
>>> set1-set1
set()
>>> set1|set1
{0, 1, 2, 3, 4}
2020年4月12日10:50:29
作者:孤傲小二~阿沐