网页图片批量获取(Python教程)
文章目录图片下载(知识点)正则表达式(知识点)图片链接提取(例题)文本内容分析(例题)图片批量下载(例题) 图片下载(知识点)
urllib 库
我们首先了解一下 urllib 库,它是 Python 内置的 HTTP 请求库,也就是说我们不需要额外安装即可使用,它包含四个模块:
第一个模块 request,它是最基本的 HTTP 请求模块,我们可以用它来模拟发送一请求。就像在浏览器里输入网址,然后敲击回车一样,只需要给库方法传入 URL ,还有额外的参数,就可以模拟实现这个过程了;
第二个 error 模块即异常处理模块,如果出现请求错误,我们可以捕获这些异常,然后进行重试或其他操作,保证程序不会意外终止;
第三个 parse 模块是一个工具模块,提供了许多 URL 处理方法,比如拆分、解析、合并等等的方法;
第四个模块是 robotparser,主要是用来识别网站的 robots.txt 文件,然后判断哪些网站可以爬,哪些网站不可以爬,其实用的比较少。
使用 urlopen() 发送请求
urllib.request 模块提供了最基本的构造 HTTP 请求的方法,利用它可以模拟浏览器的一个请求发起过程,同时它还带有处理 authenticaton(授权验证)、 redirections(重定向)、 cookies(浏览器 Cookies)以及其它内容。
接下来,我们来感受下它的强大之处,以百度为例 ,我们把网页爬取下来。
代码如下:
import urllib.request
response = urllib.request.urlopen('https://www.baidu.com')
print(response.read().decode('utf-8'))
urllib.request.urlopen(URL) :发送 HTTP 请求,返回为 HTTPResponse;
response.read() : 获取 HTTP 请求之后响应的内容。
结果如下:
location.replace(location.href.replace("https://","http://"));
IO open()
file object = open(file_name [, access_mode][, buffering])
打开 file 对象,并返回对应的数据流。如果打开失败,则抛出 IOError异常。
file_name: file_name 变量是一个包含了你要访问的文件名称的字符串值;
access_mode : access_mode 决定了打开文件的模式:只读( r),写入(w),追加(a),创建(x)等。这个参数是非强制的,默认文件访问模式为只读( r);
buffering : 如果 buffering 的值被设为 0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明这就是寄存区的缓冲大小。如果取负值,则寄存区的缓冲大小为系统默认。
上面介绍了这么多知识点,接下来举个“栗子”吧,让我们体验下如何使用 open() 函数。
# -*- coding: UTF-8 -*-
# 打开一个文件(文件必须已经存在)
fo = open("example.txt", "w")
fo.write( """这个博主值得你关注!
这篇博客值得你点赞!
""")
# 关闭打开的文件
fo.close()
效果:

OS库
os 模块代表了程序所在的操作系统,主要用于获取程序运行所在操作系统的相关信息。
举个“栗子”:创建目录:
import os
# 创建的目录
path = "/tmp/home/monthly/daily/hourly"
os.mkdir(path);
print("目录已创建")
os.mkdir()创建该目录,若目录已存在会报错
再举个“栗子”:判断文件或目录是否已存在:
import os
exists = os.path.exists("foo.txt")
if exists:
abspath = os.path.abspath("foo.txt")
print(abspath)
else:
print("文件不存在")
os.path.exists()判断目录或文件是否存在
os.path.abspath()返回绝对路径
正则表达式(知识点)
为什么使用正则表达式?
典型的搜索和替换操作,要求您提供与预期的搜索结果匹配的确切文本。虽然这种技术,对于对静态文本执行简单搜索和替换任务,可能已经足够了,但它缺乏灵活性,若采用这种方法搜索动态文本,也不是不可能,至少也会变得很困难。
比如说,判断邮箱格式是否正确、手机号格式是否正确。这种需求如果不使用正则匹配的话,那么就需要写很多逻辑进行 equals 操作。想一想都很麻烦,麻烦的原因是 equals 操作只能确切匹配,缺乏灵活度。
而正则就不同了,正则可以使用限定符,匹配字符出现的次数,这样一来灵活度都高了。
正则表达式是一个以简单直观的方式通过寻找模式匹配文本的工具
正则表达式的重复限定符
限定符用来指定正则表达式的一个给定组件,必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共 6种。

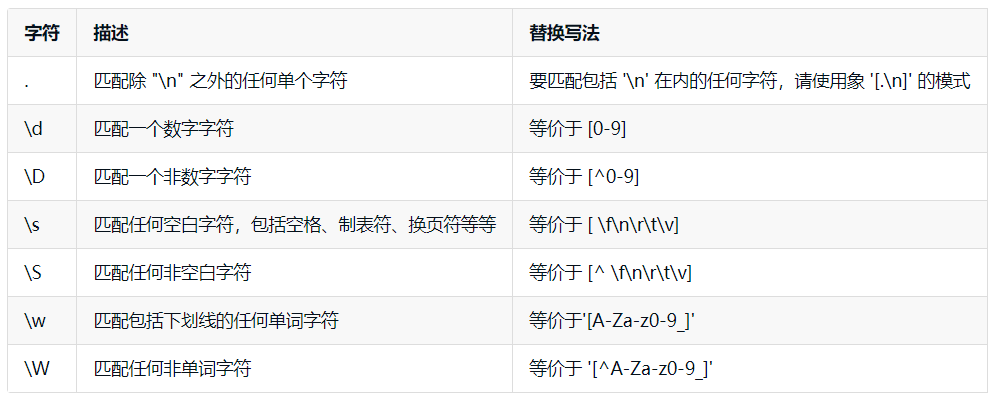
正则表达式的特殊字符类
正则表达式的分组
要实现分组很简单,使用()即可。
从正则表达式的左边开始看,看到的第一个左括号 (表示表示第一个分组,第二个表示第二个分组,依次类推。
a='python正则表达式之分组dfsl
'
print(re.search(r'(.*)',a).group(1))
输出: python正则表达式之分组
re.findall()返回组的列表
re 库的 findall 函数
在字符串中,找到正则表达式所匹配的所有子串,并返回一个列表。如果没有找到匹配的,则返回空列表。
举个“栗子”:查找字符串中的所有数字。
代码如下:
ort re
result1 = re.findall(r'\d+', 'runoob 123 google 456')
result2 = re.findall(r'\d+', 'run88oob123google456', 0, 10)
print(result1)
print(result2)
效果如下:
['123', '456']
['88', '12']
正则表达式的懒惰匹配算法
针对 正则表达式的重复限定符 默认情况下,Python正则表达式的匹配算法采用贪婪性算法(尽可能多的重复前导字符) 如果正则表达式的重复限定符的后面加后缀?,则正则表达式引擎使用懒惰性匹配算法(尽可能少的重复前导字符)
图片链接提取(例题)
使用 urllib 访问 http://www.tencent.com/ 网页,提取其网页中所有的图片链接。
代码:
import urllib.request as req
import re
"""
爬取网页内容
"""
def getHTML(url):
response = req.urlopen(url)
return response.read().decode('utf-8') # 所爬取网站为utf-8编码
"""
获取网页中全部图片的链接
- 如果网页爬取的超链接为相对路径,需要与网页根路径进行补全
- 网页爬取的超链接如果有重复项,需要去重(不一定有重复,但保险起见)
"""
def getImgUrls(html):
root = 'http://www.tencent.com/'
imgUrls = re.findall(r'img src="(.*?)".*>', html)
temp = []
for url in imgUrls:
if url not in temp:
temp.append(url)
for index, url in enumerate(temp):
if root not in url:
temp[index] = root + url
return temp
if __name__ == '__main__':
url = 'http://www.tencent.com/'
html = getHTML(url)
imgUrls = getImgUrls(html)
for url in imgUrls:
print(url)
输出效果(运行时间为2020年5月7日,网站内容可能会变哦):
http://www.tencent.com//data/index/index_detail_1.jpg
http://www.tencent.com//data/index/index_detail_2.jpg
http://www.tencent.com//data/index/index_detail_3.jpg
http://www.tencent.com//img/index/tencent_logo.png
文本内容分析(例题)
通过路径 /root/score.txt,以只读的方式读取 score.txt 文件;
获取 2016年一本线最高的的三个省份,并将其打印到控制台(格式为: 省份**********分数)
score.txt 文件数据类似如下:
甘肃 490 632 621 625 630 597 608
吉林 530 658 639 649 634 599 615
新疆 464 673 617 630 612 534 578
广西 502 642 601 620 603 584 592
上海 360 489 475 480 / / /
广东 508 641 600 613 619 585 597
内蒙古 484 641 615 627 623 558 597
陕西 470 665 628 638 639 596 615
四川 532 665 626 643 651 612 623
黑龙江 486 667 623 641 628 580 600
安徽 518 655 620 631 647 608 621
河北 525 682 654 667 669 640 649
江西 529 645 614 629 613 589 599
浙江 600 692 670 679 676 652 661
湖南 517 662 635 644 646 593 609
宁夏 465 637 565 597 590 481 526
山东 537 679 655 665 660 597 637
河南 523 665 644 652 659 629 638
山西 519 639 617 625 638 579 599
天津 512 659 634 649 600 537 567
北京 548 662 607 629 613 570 592
重庆 525 671 644 655 654 634 642
云南 525 680 653 663 663 627 639
青海 416 596 562 580 571 502 533
江苏 353 404 376 386 384 355 366
福建 465 632 614 623 606 485 576
海南 602 829 710 750 737 672 700
贵州 473 671 627 643 658 600 616
辽宁 498 660 624 637 641 607 621
湖北 512 665 622 640 637 604 614
以第一行数据为例,对数据结构进行说明:
甘肃 490 632 621 625 630 597 608 , 第一列为省份,
第二列为 2016年的一本线分数 490,
第三列为 2015年的一本线分数 632,
其次类推,分别是 2014、 2013、 2012、 2011、 2010 年的分数线。
代码:
# 先读取所有省份和对应的2016年一本线分数,分别存入列表prov和score
prov, score = [], []
with open(r'/root/score.txt', 'r') as f:
for line in f.readlines():
t = line.split()
prov.append(t[0])
score.append(int(t[1]))
# 对prov和score中的数据进行排序
temp = list(zip(prov, score)) # 把prov和score压缩为一个列表tmp
'''
对temp排序,当列表元素是元组时,
需要以元组的第二个元素进行排序,即根据一本线分数排序,
所以写了takeSecond()函数
'''
def takeSecond(elem):
return elem[1]
temp.sort(reverse=True, key=takeSecond) # 降序排序
# 获取 2016年一本线最高的的三个省份,并将其打印到控制台
for i in range(3):
p = str(temp[i][0])
s = str(temp[i][1])
print(p + '**********' + s)
效果:
海南**********602
浙江**********600
北京**********548
图片批量下载(例题)
以http://www.tencent.com/该网址为例,将网页上的所有图片批量下载到一个文件夹中。
三个步骤就可以完成了
如何获取 HTML 源码, 如何获取 HTML 源码上的指定标签, 如何使用 OS 模块完成目录的创建。import urllib.request as req
import re
import os
# 获取网页的HTML源码,返回HTML源码
def getHTML(url):
response = req.urlopen(url)
return response.read().decode('utf-8')
# 从HTML代码中提取图片的网址,返回图片链接列表
def getImgUrls(html):
root = 'http://www.tencent.com/'
imgUrls = re.findall(r'img src="(.*?)".*>', html)
temp = []
for url in imgUrls:
if url not in temp:
temp.append(url)
for index, url in enumerate(temp):
if root not in url:
temp[index] = root + url
return temp
# 下载一幅图片,图片的链接为url,下载后的图片名字为name
def downloadImg(url, name):
response = req.urlopen(url)
img = open(name, 'wb') # 以二进制形式写入
img.write(response.read())
img.close()
# 将url对应网页上所有图片下载到dirPath文件夹
def downloadAllImg(url, dirPath):
# 若文件夹不存在,则创建
exists = os.path.exists(dirPath)
if not exists:
os.mkdir(dirPath)
# 获取网页上所有图片的网址
html = getHTML(url)
imgUrls = getImgUrls(html)
print(os.path)
# 下载图片,注意异常处理
for url in imgUrls:
imgName = os.path.split(url)[1] # 获取文件名
filePath = os.path.join(dirPath, imgName) # 存放入文件夹内的完整路径名
try:
downloadImg(url, filePath)
except:
continue
if __name__ == '__main__':
url = 'http://www.tencent.com/'
dirPath = 'D:\imgs'
downloadAllImg(url, dirPath)
os.path.split(path) 以 path 中最后一个 / 作为分隔符,分隔后,将索引为0的视为目录(路径),将索引为1的视为文件名
os.path.join(path1, path2, ...) 以/拼接参数
 索儿呀
索儿呀
 原创文章 181获赞 823访问量 29万+
关注
私信
展开阅读全文
原创文章 181获赞 823访问量 29万+
关注
私信
展开阅读全文
作者:索儿呀