使用Python工具包Openpyxl进行Excel处理
目录
1 背景
2 相关资料
3 Excel结构
4 Openpyxl的总结
4.1 搭建环境
4.2 导入工具包
4.3 读取文件
4.4 按行读取,按列读取
4.5 读取值
4.6 访问和修改cell
4.7 合并单元格
4.8 存储
4.9 其它
4.9.1 文件格式
4.9.2 拷贝值和样式
1 背景前两天家里人有一个工作要做:把一张从系统里导出来的excel表分割成多个长度不统一的部分,而且分割以后需要提取里面的姓名等分别分发给对应的人。观察表格以后我发现每一个分割部分都有重复的标题,而且需要提取的姓名等信息的位置相对标题是固定的,于是想到写代码来识别标题进行分割,然后再提取姓名分别导出。
先是查到excel自带的VBA,但是感觉不太习惯这个代码风格,又查到在python里用pandas,xlrd,openpyxl等可以处理excel,于是进行尝试。最后选定了调用比较方便、交互很人性化的openpyxl,大概花了两个多小时解决了问题,把每个人的表格都分别导出,而且姓名等信息作为文件名,结果还不错。
下面就稍微总结一下。
2 相关资料 手册:这是有人在简书上翻译的openpyxl的手册,很短小精炼,看完后表格的基本操作都能做了。 官方文档:如果要深入学习或使用高级功能还是要看文档看相关资料前我建议我们先把excel的结构回顾一下,这样操作起来会更得心应手。
3 Excel结构之所以说openpyxl交互人性化是因为它的结构就是根据excel的结构进行设计的。首先来回顾一下excel:
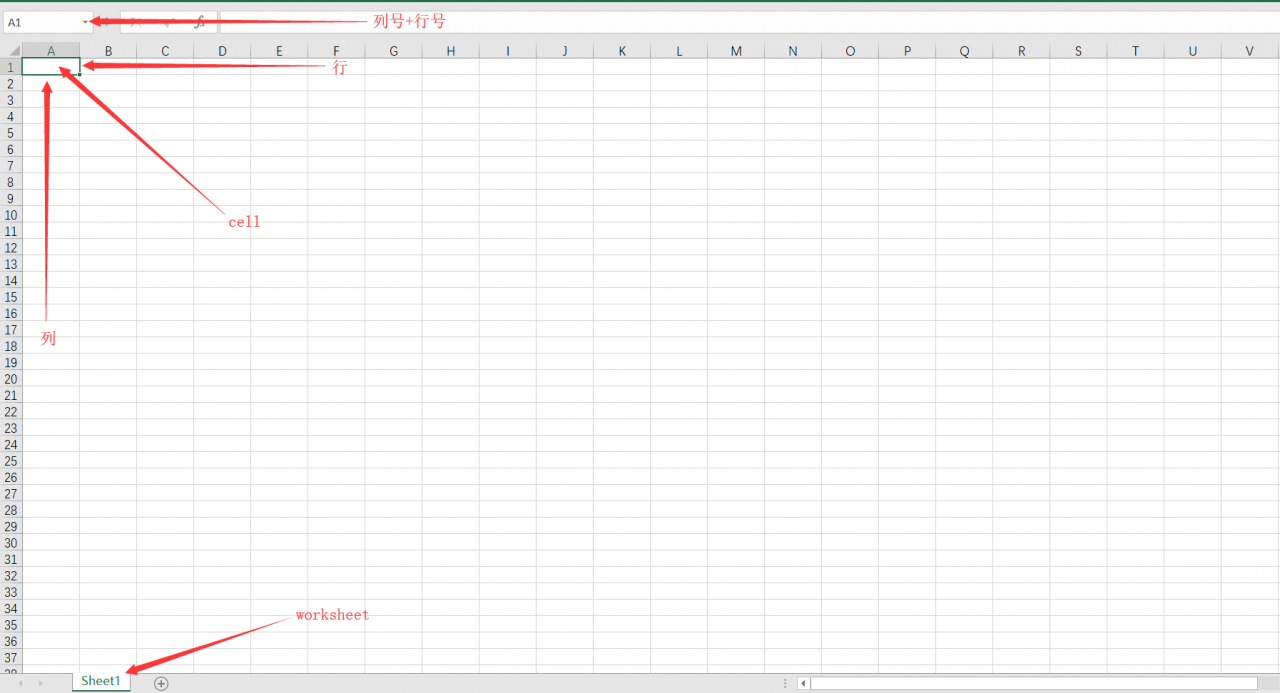
图中是一个新建excel文件打开后的样子,我们可以把它想象成一本账本:
每一个excel文件是一个workbook(一本账本)
每一个workbook里可以创建多个worksheet(在每一本账本里有很多页)
每一个worksheet里有很多行rows和很多列columns,行标用数字表示,列标用字母表示
行与列的交叉处是一个单元格cell(一条记账),每个cell有很多的属性:
编号:用cell所处行列唯一表示,即column+row
值:每个cell中记录的内容
数据类型:字符、数字、日期等
样式:底色、字体等
4 Openpyxl的总结 4.1 搭建环境
因为阅读的对象可能不是专业编程人员,所以介绍一下基本环境的搭建,搭环境一共三步:
安装python环境
安装pip
通过pip来安装openpyxl工具包
第一步装环境的时候可以顺便安装一个IDE(集成开发环境),比如Pycharm,Anaconda等,这样安装工具包可以直接在IDE里进行。
4.2 导入工具包首先在python文件中导入openpyxl进行使用,导入workbook对于大多情况已经够用了
import openpyxl as xl
from openpyxl import workbook
4.3 读取文件
将.xlsx文件转化为workbook变量wb,并提取workbook中的第一个sheet存到变量ws,这样可以对worksheet做很多我们在excel里的操作了
filename = "full/path/of/xlsx"
# load file
wb = xl.load_workbook(filename)
# get the first sheet
ws = wb1.worksheets[0]
4.4 按行读取,按列读取
用worksheet的iter_rows()和iter_cols()方法可以读取出每一行/列,再在每一行/列中循环读取就可以获取每一个cell,这时候print出来的是该cell的编号信息。
# read by row
for row in ws.iter_rows():
for cell in row:
print(cell)
# read by column
for col in ws.iter_cols():
for cell in col:
print(cell)
4.5 读取值
获取cell后只用调用cell的方法_value就可以获取cell中的内容
# read by row
for row in ws.iter_rows():
for cell in row:
print(cell._value)
# read by column
for col in ws.iter_cols():
for cell in col:
print(cell._value)
4.6 访问和修改cell
可以直接通过给出序号的方式直接访问和编辑单元格,序号的规范是列号(字母)+行号(数字),如"A1"
# c1 get A1
c1 = ws['A1']
# c2 get A1
c2 = ws.cell(row=1, column=1)
# eidt A2
ws['A2'] = 1
4.7 合并单元格
合并单元格也是excel中非常常见的操作,在excel中只需要拖选中要合并的框然后点击合并即可;openpyxl同理,拖动的步骤由切片完成,切片方法是'起始cell编号:终止cell编号 ',合并调用的是worksheet的函数merge_cells
# merge A1 to F1
ws.merge_cells('A1:F1')
4.8 存储
存储的对象是workbook,当对worksheet进行操作后直接存储其所属的workbook,存储的格式仍然是xlsx
filename_save = "path/of/save"
wb.save(filename_save)
4.9 其它
还有两点想要补充说明一下:
4.9.1 文件格式
目前Openpyxl可以读取的是office2003以后的excel格式即.xlsx,因此如果表格是旧格式.xls的需要将文件另存一下,切记不要直接修改后缀名,可能导致文件不可用。
4.9.2 拷贝值和样式
这个问题是我在做的时候遇到的,当从一个worksheet拷贝value到另一个worksheet时,其样式不会跟随拷贝。如果要连带样式一起拷贝需要加入如下语句:
from copy import copy
# copy 1 to 10
start = 1
end = 10
# max column
mc = ws.max_column
#
for i in range(start, end + 1):
for j in range(1, mc + 1):
# reading cell value from source excel file
source_cell = worksheet.cell(row=i, column=j)
# writing the read value to destination excel file
target_cell = ws_save.cell(row=i-start+1, column=j)
# copy style, comment and hyperlink
if source_cell.has_style:
target_cell._style = copy(source_cell._style)
target_cell.font = copy(source_cell.font)
target_cell.border = copy(source_cell.border)
target_cell.fill = copy(source_cell.fill)
target_cell.number_format = copy(source_cell.number_format)
target_cell.protection = copy(source_cell.protection)
target_cell.alignment = copy(source_cell.alignment)
if source_cell.hyperlink:
target_cell._hyperlink = copy(source_cell.hyperlink)
if source_cell.comment:
target_cell.comment = copy(source_cell.comment)
# copy value
target_cell.value = source_cell._value
target_cell.data_type = source_cell.data_type
请注意的是cell无法拷贝列宽和行高,列宽行高要通过worksheet的column_dimensions和row_dimensions属性来修改,可以参考这篇文章,另外可以查到一些自适应宽高的方法。
欢迎交流和指正。
作者:一步徐龙的浪