学习python的第五天 半自动爬虫开发 一半手动一半自动地进行爬虫 爬csdn
正则表达式
学习python的第五天 (2020.04.010)
知识梳理
作者:白小梦啊!
打开csdn官网,选择程序人生菜单栏,查看源代码,复制源代码,保存txt文本文件,通过python从文本文件中获取然后保存到csv文件中,今天就把发帖人、发帖标题和阅读量和点赞数爬出来。
涉及的知识如下:
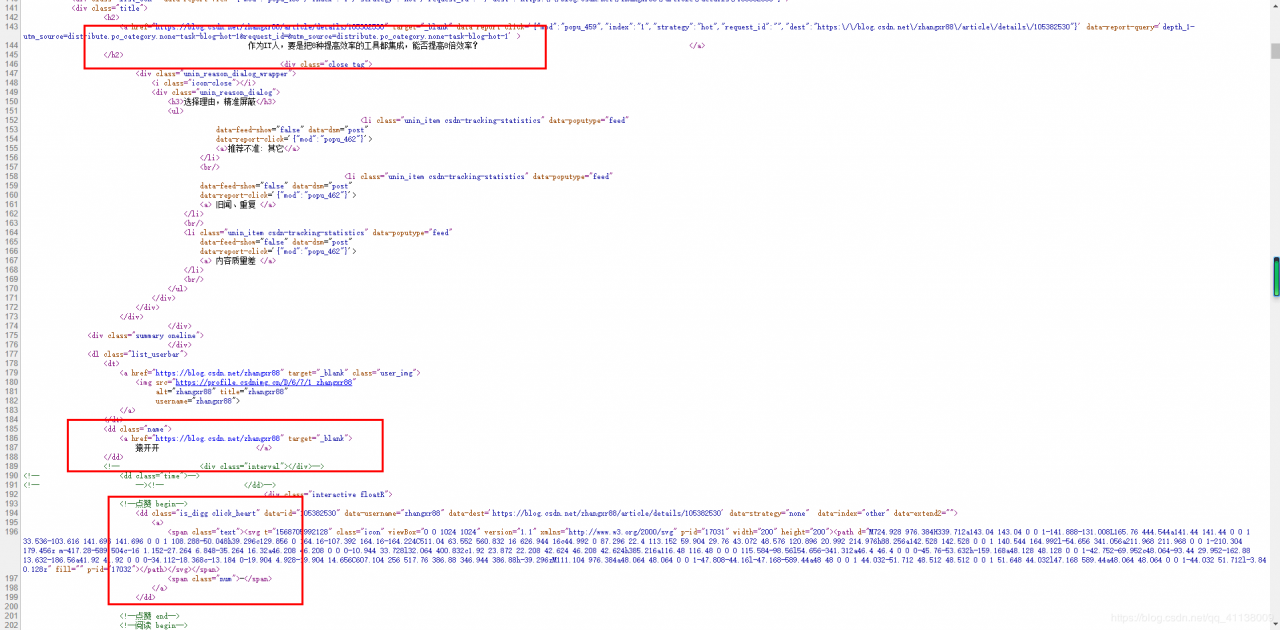
1.在浏览器中查看网站的源代码
2.使用python读文本文件
3.正则表达式的应用
4.先抓大再抓小的匹配技巧
5.使用python写csv文件
要爬取的东西如下图红色文本框
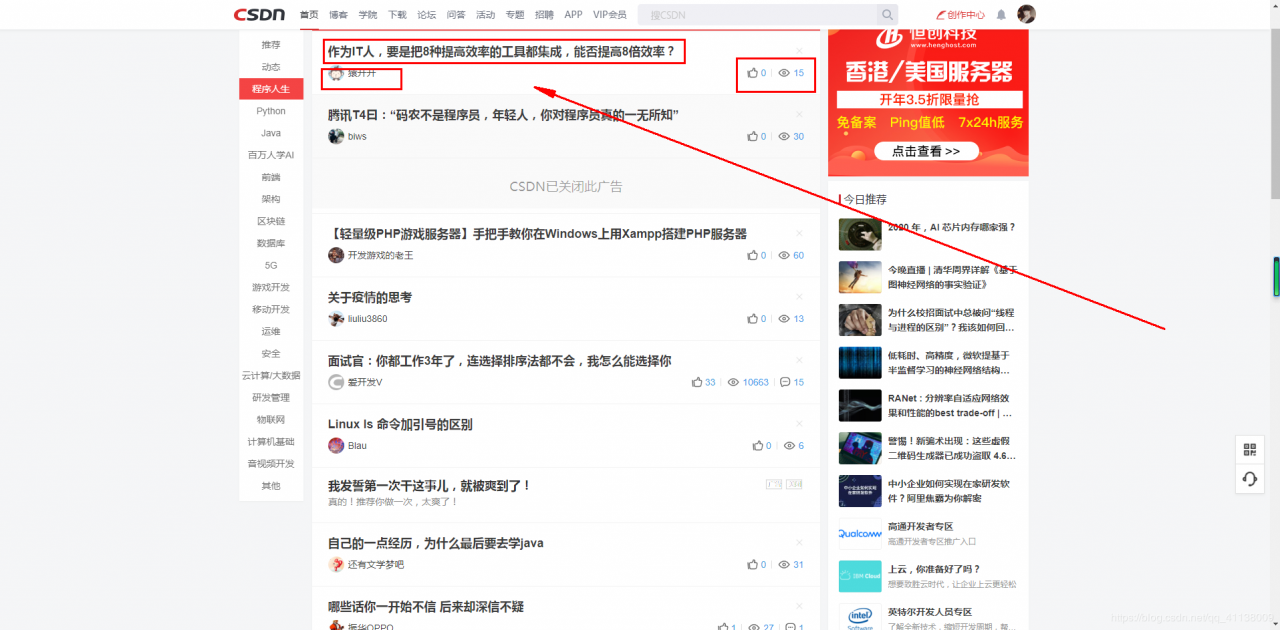
在源代码 找出要爬出来的内容
#coding:utf-8
#coding: GBK
import re
import csv
with open('lol.txt','r',encoding='utf-8')as f:
txt=f.read()
zhi_list=[]
username = re.findall('target="_blank">\\n (.*?) \\n (.*?) <',txt,re.S)
print(username)
print(boss)
i=0
with open('result.csv','a',encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=['name', 'title'])
writer.writeheader()
for i in range(len(username)):
zhi = {'name':username[i],'title':boss[i]}
print(zhi)
writer.writerow(zhi)
运行结果
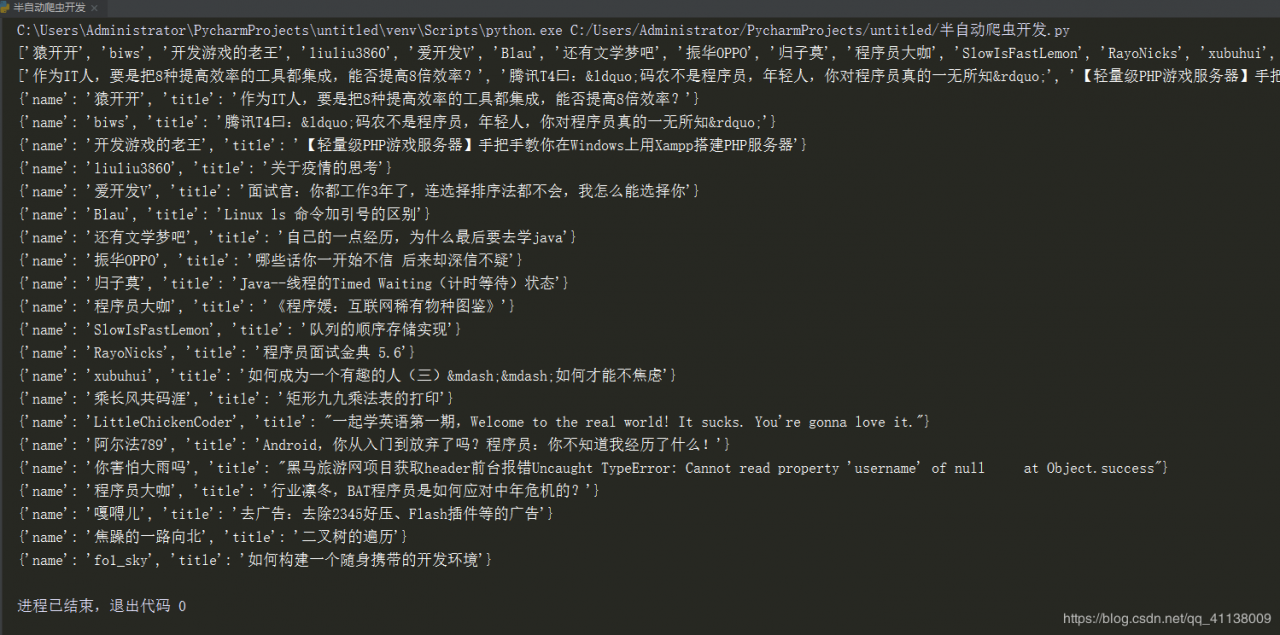

本来早都可以写完了,老是报错,根据书上写了还是有问题,最后只有自己跟着逻辑走,还好,写出来了,虽然不是很完美,但至少成功了,今天没有白费,花的时间比较多,( •̀ ω •́ )y我是猪啊,我是猪啊,我是猪啊!
作者:白小梦啊!