Python中的@cache巧妙用法
Python中的@cache有什么妙用?
@cache缓存功能介绍
@cache的应用场景
补充:Python @cache装饰器
Python中的@cache有什么妙用?缓存是一种空间换时间的策略,缓存的设置可以提高计算机系统的性能。具体到代码中,缓存的作用就是提高代码的运行速度,但会占用额外的内存空间。
在Python的内置模块 functools 中,提供了高阶函数 cache() 用于实现缓存,用装饰器的方式使用: @cache。
@cache缓存功能介绍在cache的源码中,对cache的描述是:Simple lightweight unbounded cache. Sometimes called “memoize”. 翻译成中文:简单的轻量级无限制缓存。有时也被称为“记忆化”。
def cache(user_function, /):
'Simple lightweight unbounded cache. Sometimes called "memoize".'
return lru_cache(maxsize=None)(user_function)
cache() 的代码只有一行,调用了 lru_cache() 函数,传入一个参数 maxsize=None。lru_cache() 也是 functools 模块中的函数,查看 lru_cache() 的源码,maxsize 的默认值是128,表示最大缓存128个数据,如果数据超过了128个,则按 LRU(最久未使用)算法删除多的数据。cache()将maxsize设置成None,则 LRU 特性被禁用且缓存数量可以无限增长,所以称为“unbounded cache”(无限制缓存)。
lru_cache() 使用了 LRU(Least Recently Used)最久未使用算法,这也是函数名中有 lru 三个字母的原因。最久未使用算法的机制是,假设一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小, LRU算法选择将最近最少使用的数据淘汰,保留那些经常被使用的数据。
cache() 是在Python3.9版本新增的,lru_cache() 是在Python3.2版本新增的, cache() 在 lru_cache() 的基础上取消了缓存数量的限制,其实跟技术进步、硬件性能的大幅提升有关,cache() 和 lru_cache() 只是同一个功能的不同版本。
lru_cache() 本质上是一个为函数提供缓存功能的装饰器,缓存 maxsize 组传入参数,在下次以相同参数调用函数时直接返回上一次的结果,用以节约高开销或高I/O函数的调用时间。
@cache的应用场景缓存的应用场景很广泛,如静态 Web 内容的缓存,可以直接在用户访问静态网页的函数上加 @cache 装饰器。
一些递归的代码中,存在反复传入同一个参数执行函数代码的情况,使用缓存可以避免重复计算,降低代码的时间复杂度。
接下来,我用斐波那契数列作为例子来说明 @cache 的作用,如果前面的内容你看完了还一知半解,相信看完例子你会茅塞顿开。
斐波那契数列是指这样一个数列:1、1、2、3、5、8、13、21、34、… ,从第三个数开始,每个数都是前两个数之和。斐波那契数列的代码实现不难,大部分程序员入门时都做过,在Python中,实现的代码非常简洁。如下:
def feibo(n):
# 第0个数和第1个数为1
a, b = 1, 1
for _ in range(n):
# 将b赋值给a,将a+b赋值给b,循环n次
a, b = b, a+b
return a
当然,斐波那契数列的代码实现方式有很多种(至少五六种),本文为了说明 @cache 的应用场景,用递归的方式来写斐波那契数列的代码。如下:
def feibo_recur(n):
if n < 0:
return "n小于0无意义"
# n为0或1时返回1(前两个数为1)
if n == 0 or n == 1:
return 1
# 根据斐波那契数列的定义,其他情况递归返回前两个数之和
return feibo_recur(n-1) + feibo_recur(n-2)
递归代码执行时会一直递归到feibo_recur(1)和feibo_recur(0),如下图所示(以求第6个数为例)。
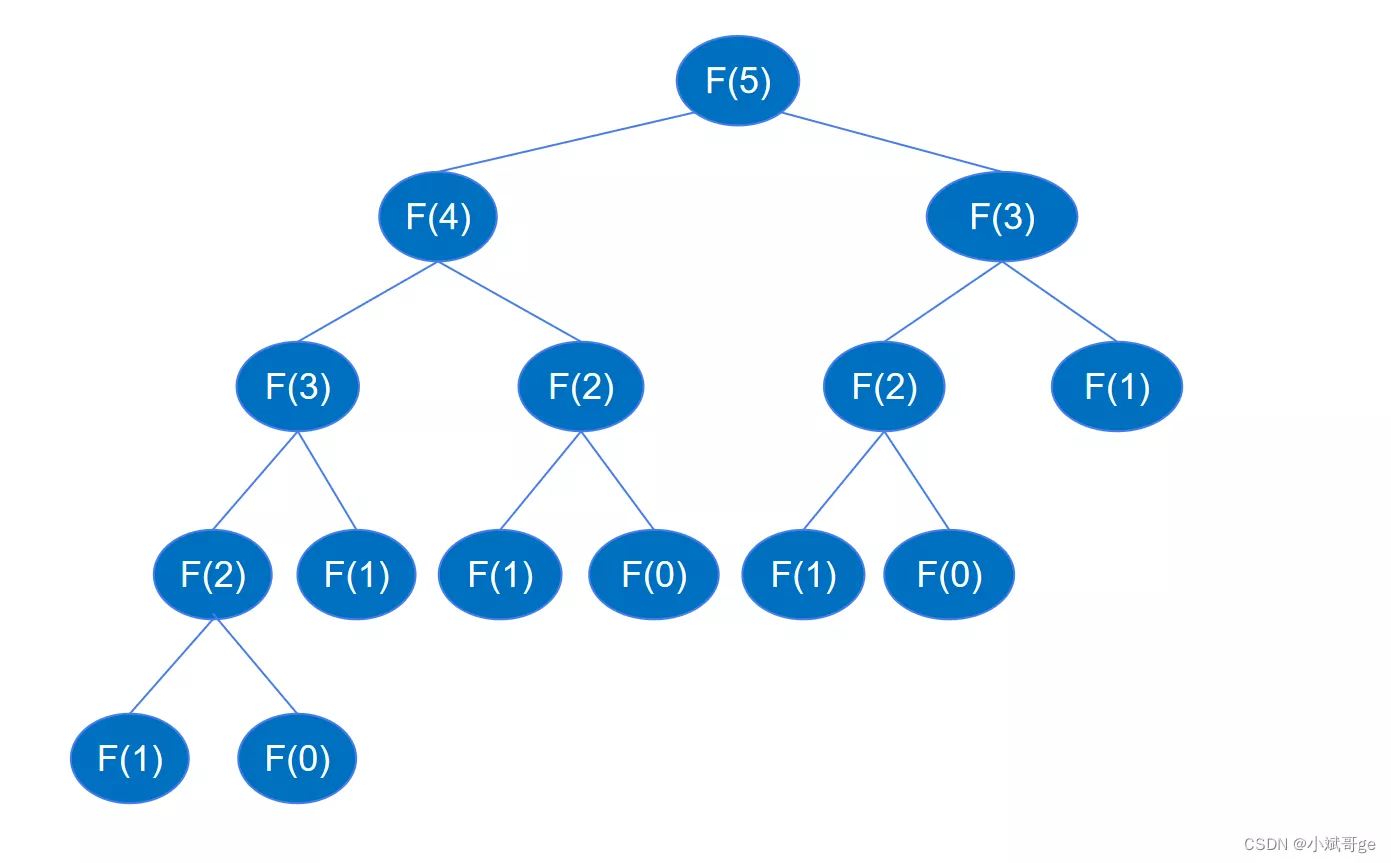
求F(5)时要先求F(4)和F(3),求F(4)时要先求F(3)和F(2),… 以此类推,递归的过程与二叉树深度优先遍历的过程类似。已知高度为 k 的二叉树最多可以有 2k-1 个节点,根据上面递归调用的图示,二叉树的高度是 n,节点最多为 2n-1, 也就是递归调用函数的次数最多为 2n-1 次,所以递归的时间复杂度为 O(2^n) 。
时间复杂度为O(2^n)时,执行时间随 n 的增大变化非常夸张,下面实际测试一下。
import time
for i in [10, 20, 30, 40]:
start = time.time()
print(f'第{i}个斐波那契数:', feibo_recur(i))
end = time.time()
print(f'n={i} Cost Time: ', end - start)
Output:
第10个斐波那契数: 89
n=10 Cost Time: 0.0
第20个斐波那契数: 10946
n=20 Cost Time: 0.0015988349914550781
第30个斐波那契数: 1346269
n=30 Cost Time: 0.17051291465759277
第40个斐波那契数: 165580141
n=40 Cost Time: 20.90010976791382
从运行时间可以看出,在 n 很小时,运行很快,随着 n 的增大,运行时间极速上升,尤其 n 逐步增加到30和40时,运行时间变化得特别明显。为了更清晰地看出时间变化规律,再进一步进行测试。
for i in [41, 42, 43]:
start = time.time()
print(f'第{i}个斐波那契数:', feibo_recur(i))
end = time.time()
print(f'n={i} Cost Time: ', end - start)
Output:
第41个斐波那契数: 267914296
n=41 Cost Time: 33.77224683761597
第42个斐波那契数: 433494437
n=42 Cost Time: 55.86398696899414
第43个斐波那契数: 701408733
n=43 Cost Time: 92.55108690261841
从上面的变化可以看到,时间是指数级增长的(大约按1.65的指数增长),这跟时间复杂度为 O(2^n) 相符。按照这个时间复杂度,假如要计算第50个斐波那契数列,差不多要等一个小时,非常不合理,也说明递归的实现方式运算量过大,存在明显的不足。如何解决这种不足,降低运算量呢?接下来看如何进行优化。
根据前面的分析,递归代码运算量大,是因为递归执行时会不断的计算 feibo_recur(n-1) 和 feibo_recur(n-2),如示例图中,要得到 feibo_recur(5) ,feibo_recur(1) 调用了5次。随着 n 的增大,调用次数呈指数增加,造成了海量不必要的重复,浪费了大量时间。
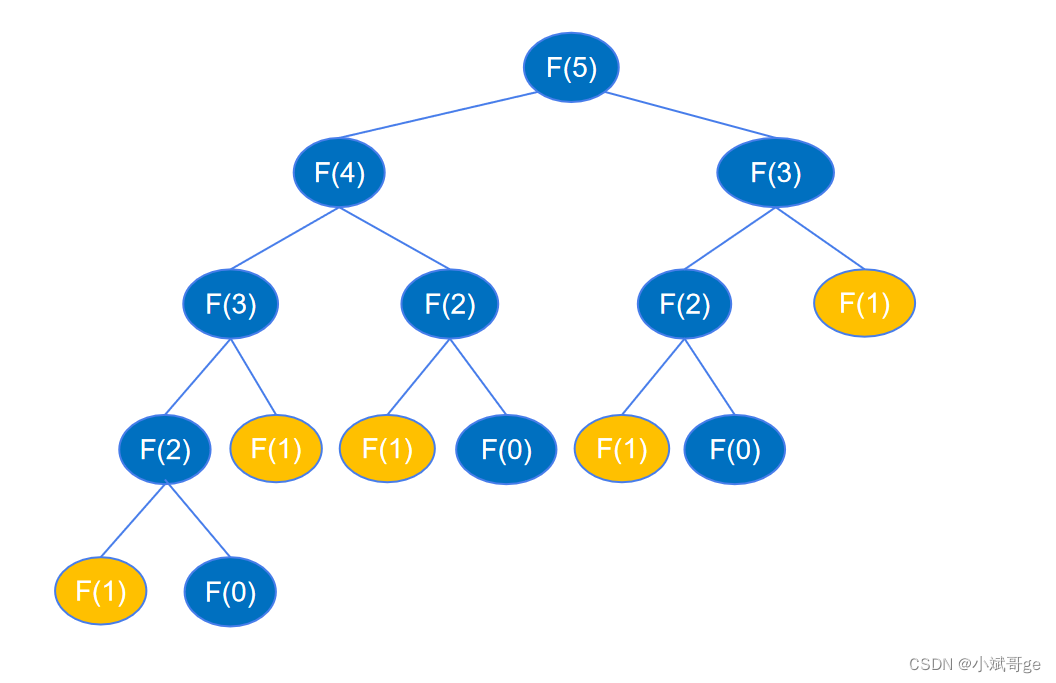
假如有一个地方将每个 n 的执行结果记录下来,当作“备忘录”,下次函数再接收到这个相同的参数时,直接从备忘录中获取结果,而不用去执行递归的过程,就可以避免这些重复调用。在 Python 中,可以创建一个字典或列表来当作“备忘录”使用。
temp = {} # 创建一个空字典,用来记录第i个斐波那契数列的值
def feibo_recur_temp(n):
if n < 0:
return "n小于0无意义"
# n为0或1时返回1(前两个数为1)
if n == 0 or n == 1:
return 1
if n in temp: # 如果temp字典中有n,则直接返回值,不调用递归代码
return temp[n]
else:
# 如果字典中还没有第n个斐波那契数,则递归计算并保存到字典中
temp[n] = feibo_recur_temp(n-1) + feibo_recur_temp(n-2)
return temp[n]
上面的代码中,创建了一个空字典用于存放每个 n 的执行结果。每次调用函数,都先查看字典中是否有记录,如果有记录就直接返回,没有记录就递归执行并将结果记录到字典中,再从字典中返回结果。这里的递归其实都只执行了一次计算,并没有真正的递归,如第一次传入 n 等于 5,执行 feibo_recur_temp(5),会递归执行 n 等于 4, 3, 2, 1, 0 的情况,每个 n 计算过一次后 temp 中都有了记录,后面都是直接到 temp 中取数相加。每个 n 都是从temp中取 n-1 和 n-2 的值来相加,执行一次计算,所以时间复杂度是 O(n) 。
下面看一下代码的运行时间。
for i in [10, 20, 30, 40, 41, 42, 43]:
start = time.time()
print(f'第{i}个斐波那契数:', feibo_recur_temp(i))
end = time.time()
print(f'n={i} Cost Time: ', end - start)
print(temp)
Output:
第10个斐波那契数: 89
n=10 Cost Time: 0.0
第20个斐波那契数: 10946
n=20 Cost Time: 0.0
第30个斐波那契数: 1346269
n=30 Cost Time: 0.0
第40个斐波那契数: 165580141
n=40 Cost Time: 0.0
第41个斐波那契数: 267914296
n=41 Cost Time: 0.0
第42个斐波那契数: 433494437
n=42 Cost Time: 0.0
第43个斐波那契数: 701408733
n=43 Cost Time: 0.0
{2: 2, 3: 3, 4: 5, 5: 8, 6: 13, 7: 21, 8: 34, 9: 55, 10: 89, 11: 144, 12: 233, 13: 377, 14: 610, 15: 987, 16: 1597, 17: 2584, 18: 4181, 19: 6765, 20: 10946, 21: 17711, 22: 28657, 23: 46368, 24: 75025, 25: 121393, 26: 196418, 27: 317811, 28: 514229, 29: 832040, 30: 1346269, 31: 2178309, 32: 3524578, 33: 5702887, 34: 9227465, 35: 14930352, 36: 24157817, 37: 39088169, 38: 63245986, 39: 102334155, 40: 165580141, 41: 267914296, 42: 433494437, 43: 701408733}
可以看到,代码运行时间全都降到小数点后很多位了(时间太小,只显示了 0.0 )。不过,temp 字典里记录了每个数对应的斐波那契数,这需要占用额外的内存空间,用空间换时间。
上面的代码也可以用列表来当“备忘录”,代码如下。
temp = [1, 1]
def feibo_recur_temp(n):
if n < 0:
return "n小于0无意义"
if n == 0 or n == 1:
return 1
if n < len(temp):
return temp[n]
else:
# 第一次执行时,将结果保存到列表中,后续直接从列表中取
temp.append(feibo_recur_temp(n-1) + feibo_recur_temp(n-2))
return temp[n]
现在,已经剖析了递归代码重复执行带来的时间复杂度问题,也给出了优化时间复杂度的方法,让我们将注意力转回到本文介绍的 @cache 装饰器。@cache 装饰器的作用是将函数的执行结果缓存,在下次以相同参数调用函数时直接返回上一次的结果,与上面的优化方式完全一致。
所以,只需要在递归函数上加 @cache 装饰器,递归的重复执行就可以解决,时间复杂度就能从 O(2^n) 降为 O(n) 。代码如下:
from functools import cache
@cache
def feibo_recur(n):
if n < 0:
return "n小于0无意义"
if n == 0 or n == 1:
return 1
return feibo_recur(n-1) + feibo_recur(n-2)
代码比自己实现更加简洁优雅,并且每次使用时直接加上 @cache 装饰器就行,专注处理业务逻辑。下面看一下实际的运行时间。
for i in [10, 20, 30, 40, 41, 42, 43]:
start = time.time()
print(f'第{i}个斐波那契数:', feibo_recur(i))
end = time.time()
print(f'n={i} Cost Time: ', end - start)
Output:
第10个斐波那契数: 89
n=10 Cost Time: 0.0
第20个斐波那契数: 10946
n=20 Cost Time: 0.0
第30个斐波那契数: 1346269
n=30 Cost Time: 0.0
第40个斐波那契数: 165580141
n=40 Cost Time: 0.0
第41个斐波那契数: 267914296
n=41 Cost Time: 0.0
第42个斐波那契数: 433494437
n=42 Cost Time: 0.0
第43个斐波那契数: 701408733
n=43 Cost Time: 0.0
运行时间全都降到小数点后很多位了(只显示了 0.0 ),完美解决问题,非常精妙。以后遇到相似的情况,可以直接使用 @cache ,实现“记忆化”的缓存功能。
补充:Python @cache装饰器参考文档:
[1] Python文档标准库functools:https://docs.python.org/zh-cn/3.11/library/functools.html#functools.cache
@cache和@lru_cache(maxsize=None)可以用来寄存函数对已处理参数的结果,以便遇到相同参数可以直接给出答案。前者不限制存储的数量,后者通过maxsize限制存储的最大数量。
例:
@lru_cache(maxsize=None) # 等价于@cache
def test(a,b):
print('开始计算a+b的值...')
return a + b
可以用来做某些递归、动态规划。比如斐波那契数列的各项值从小到大输出。其实类似用数组保存前项的结果,都需要额外的空间。不过用装饰器可以省略额外空间代码,减少了出错的风险。
到此这篇关于Python中的@cache巧妙用法的文章就介绍到这了,更多相关Python中的@cache内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!