python+django+mysql 从零搭建资讯类网站10
系列文章将记录本人从零开始搭建资讯类的网站,所有源码都开放哦!欢迎互相讨论学习!
源码下载地址:https://github.com/wuqiwenpk/babyteach
本系列文章导航:https://github.com/wuqiwenpk/babyteach/blob/master/README.md
本篇目的通过爬虫爬取同类资讯网站新闻详情页,并保持内容到数据库中。
本次爬虫测试目标为
列表页:http://www.yuerzaixian.com/a/1171.aspx
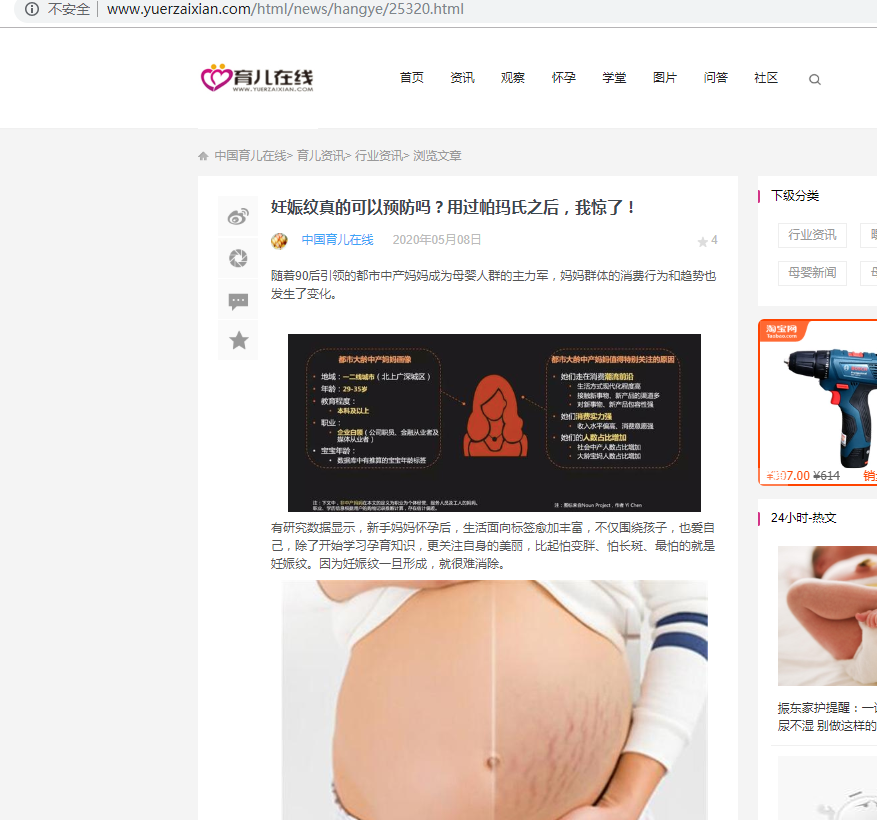
爬取详情页:http://www.yuerzaixian.com/html/news/hangye/25320.html
本文将用到python解析库lxml、requests库对目标网页进行爬虫解析
(注:本系列所有爬虫操作仅用于学习用途)
1、在DjangoProject/babyteach下创建新目录spider并添加py文件:newsspider.py
2.1、引用需要用到的相关库:
import os, django
os.environ.setdefault("DJANGO_SETTINGS_MODULE", "DjangoProject.settings")# project_name 项目名称
django.setup()
import re
import datetime
from babyteach.models import Detail, Tags
import requests
from lxml import etree
2.2、添加方法:
#爬取详情页数据保存到表Detail中
def getdetailbyspider(url):
response = requests.get(url).text
response=response.encode("latin1").decode("UTF-8")#编码转码
# print(response)
x = etree.HTML(response)
x = x.xpath('//div[(@class="content")]')
for item in x:
title = item.xpath('div[@class="title"]/text()')[0] #标题
addtime = item.xpath('div[@class="info"]/span[@class="date"]/text()')[0] #时间
orgwords = item.xpath('div[@class="intro"]') #正文
words = etree.tostring(orgwords[0], encoding="utf-8", pretty_print=True).decode("utf-8")
pic = "/static/babyteach/img/nophoto.gif" #默认封面图
if len(item.xpath('div[@class="intro"]//img/@src'))!=0:
pic ='http://www.yuerzaixian.com/'+ item.xpath('div[@class="intro"]//img/@src')[0]#正文存在图片时保持第一张图片作为封面图
words = words.replace('src="/UploadFiles','src="http://www.yuerzaixian.com/UploadFiles')#处理正文中未添加域名的图片url
pattern = re.compile(r']+>', re.S)
summary = pattern.sub('', words).strip()[0:60]#截取正文前面文字作为简介
print('标题:', title)
print('时间:', addtime)
print('简介:', summary)
print('正文:', words)
#运行函数
getdetailbyspider("http://www.yuerzaixian.com/html/news/hangye/25320.html")
2.3、右键代码运行查看效果:
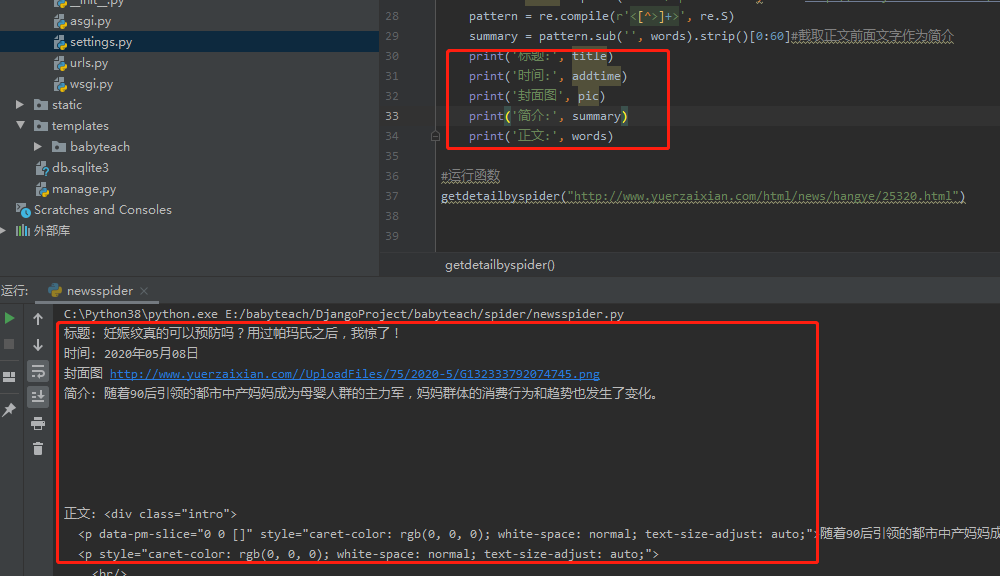
内容能正常获取;
2.4、添加插入到数据库的代码:
#插入到Detail数据库中
detail = Detail()
detail.title = title
detail.summary = summary
detail.addtime = datetime.datetime.strptime(addtime, "%Y年%m月%d日")
detail.author = '育儿在线网'
detail.words = words
detail.clicks = 0
detail.pic = pic
detail.link = url
detail.tag = Tags.objects.get(id=5) #育儿资讯
detail.save()
再次执行代码:
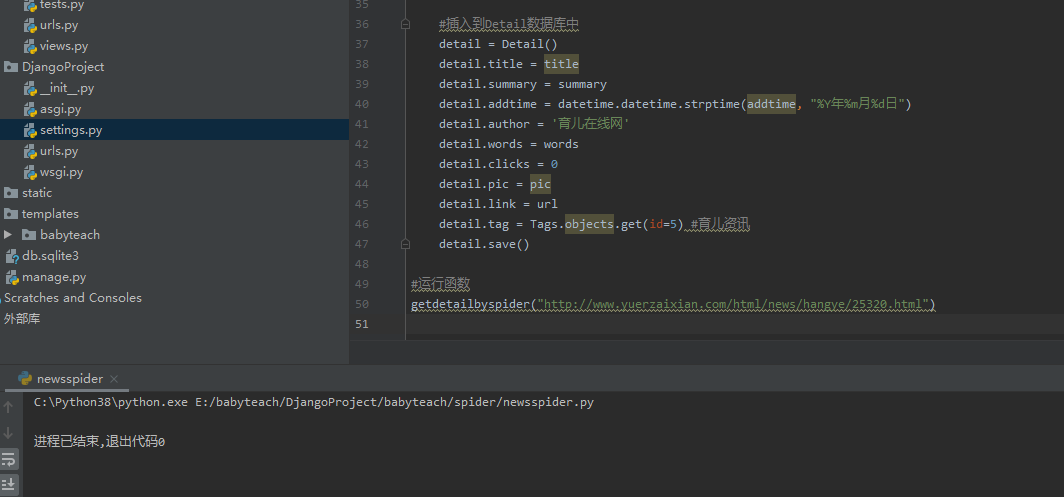
数据库已添加对应数据:

运行网站,访问文章ID为28的看看效果:

通过爬虫爬取同类资讯网站新闻详情页,并保持内容到数据库中。
下一篇将介绍爬取目标网站的列表页,并批量导入详情页内容到数据库中;
完整源码地址:https://github.com/wuqiwenpk/babyteach
 小明太难了
小明太难了
 原创文章 11获赞 1访问量 329
关注
私信
展开阅读全文
原创文章 11获赞 1访问量 329
关注
私信
展开阅读全文
作者:小明太难了