Andrew Ng Machine learning——Work(One)——Linear regression——Univerate(Based on Python 3.7)
Python 3.7
所用数据链接::https://pan.baidu.com/s/1YGsencu8wrilvrjuSteGZQ
提取码:c3yy
题目:为选定创办超市地点,我们有来自多个不同城市的人口(x)和利润(y) 数据,先希望根据这些数据利用线性回归来预测利润与人口的关系,从而选择超市创办地点。
1.0 package首先引入相应的包,以便后续使用。
import numpy as np #处理矩阵,转换数据格式必备
import pandas as pd #读取数据,加工数据
import matplotlib.pyplot as plt #绘图
1.1 load data
读入数据,代码如下:
def load_data(path): #定义函数,名为load_data,有一个参数path
data=pd.read_csv(path,header=None,names=['population','profit'])
#读取数据,其中path为数据路径,header代表列索引,默认为0,也就是以第一行为列索引,这里关闭默认,改用后面的names为列索引
return data ,data.head(),data.describe()
# 返回数据,表头以及数据的统计信息
查看返回值:
data,data_head,data_describe=load_data('ex1data1.txt')
print(data_head)
print(data_describe)

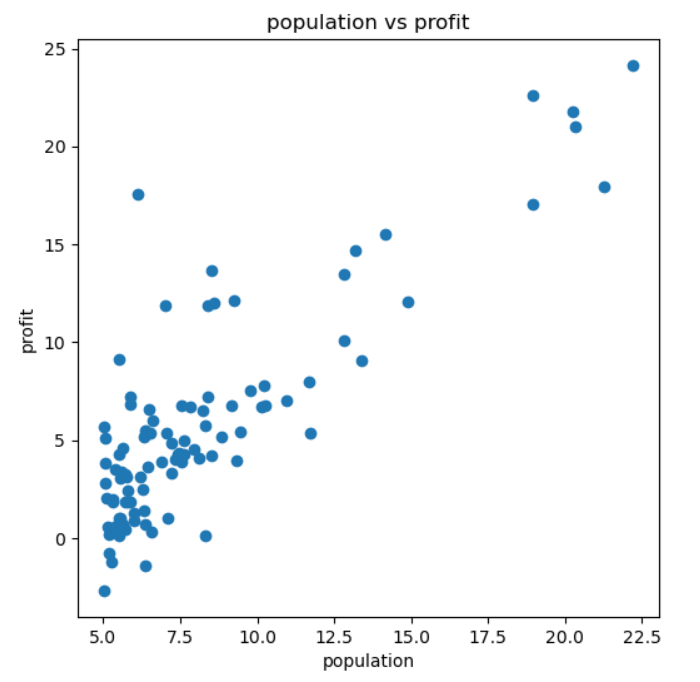
读取完数据后,最好能够将其可视化,以加深对数据的直观认识。事实上这一步虽然不是算法的核心,但个人认为对于数据分布的直观认识往往也十分重要,下面给出代码:
def visualization_data():
#定义函数,函数名称为cisualization_data,无传入变量
fig,ax=plt.subplots(figsize=(6,6))
# fig可以理解为创建一个画布,ax可以理解为画布中的具体内容,figsize指明画布大小为6*6
ax.scatter(data['population'],data['profit'])
#scatter指明画图类型为散点图,其中传入参数,前两个为位置参数,按位置对应依次为散点的x坐标和y坐标,第三个参数label指明了该图的名称
ax.set_xlabel('population')
#设置横坐标名称为 population
ax.set_ylabel('profit')
# 设置纵坐标名称为 profit
ax.set_title('population vs profit')
# 设置该图主题为 population vs profit
plt.show()
# 可视化
结果如下:
 原创文章 11获赞 98访问量 6万+
关注
私信
展开阅读全文
原创文章 11获赞 98访问量 6万+
关注
私信
展开阅读全文
作者:AI小小白