三分钟带你掌握python中的生产者与消费者模式
1. 什么是生产者消费者模式?
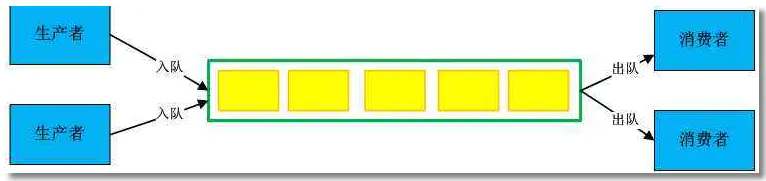
Caption
在线程世界里,生产者就是生产数据(或者说发布任务)的线程,消费者就是消费数据(或者说处理任务)的线程。在任务执行过程中,如果生产者处理速度很快,而消费者处理速度很慢,那么生产者就必须等待消费者处理完,才能继续生产数据。同样的道理,如果消费者的处理能力大于生产者,那么消费者就必须等待生产者提供更多的任务,本质上,这是一种供需不平衡的表现。为了解决这个问题,我们创造了生产者和消费者模式。
2. 生产者消费者模式的工作机制生产者消费者模式是通过一个容器来解决生产者和消费者的强耦合问题。生产者和消费者彼此之间不直接通讯,而是通过阻塞队列来进行通讯,所以生产者生产完数据之后不用等待消费者处理,直接扔给阻塞队列,消费者不直接找生产者要数据,而是从阻塞队列里取,阻塞队列就相当于一个缓冲区,平衡了生产者和消费者的处理能力,解耦了生产者和消费者。
本人主要研究计算机视觉,所以举一个关于视频的栗子。生产者从视频中读取帧,放入队列。消费者从队列中获取帧,然后获得帧的信息。
直接看代码(python3):
# --*-- coding:utf-8 -*-
import cv2
from threading import Thread
from queue import Queue
class Video(object):
def __init__ (self, input_video):
self.path = input_video
self.queue = Queue(10)
self.video = cv2.VideoCapture(self.path)
self.process = Thread(target=self.read)
# 设置守护线程,避免进入死循环
self.process.setDaemon(True)
self.process.start()
def read(self):
succ, frame = self.video.read()
while succ:
self.queue.put(frame)
succ, frame = self.video.read()
self.video.release()
def get(self):
while self.process.is_alive() or self.queue.qsize() > 0:
if(self.queue.qsize() > 0):
frame = self.queue.get()
if frame is None or not frame.any():
continue
#你可以在这里加入其他的函数,这里只是获取帧的尺寸信息,可以替换成目标检测
result = frame.shape
yield result
if __name__ == '__main__':
video = Video("test.mp4")
for result in video.get():
print(result)
print("over")
OK, 就是这么简单,如果你喜欢就关注一下!!!
 CV-deeplearning
CV-deeplearning
 原创文章 15获赞 22访问量 2384
关注
私信
展开阅读全文
原创文章 15获赞 22访问量 2384
关注
私信
展开阅读全文
作者:CV-deeplearning