Python 爬取豆瓣电影Top250
文章目录
一、多线程爬取电影封面保存到本地
二、爬取电影的基本信息保存到Excel
查看各页面的url:
第一页:https://movie.douban.com/top250?start=0&filter=
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
第十页:https://movie.douban.com/top250?start=225&filter=
分析可得页面url的规律:
url_list = [“https://movie.douban.com/top250?start={}&filter=”.format(x * 25) for x in range(10)]
单线程版
import requests
from lxml import etree
import datetime
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1"
}
# 设置保存路径 保存到指定文件夹 路径复制过来
path = input("请输入保存路径:")
start_time = datetime.datetime.now()
def get_pic(url):
rep = requests.get(url, headers=headers).text
html = etree.HTML(rep)
# 获取电影封面图 电影名称 xpath定位提取 得到的是列表
src = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/img/@src')
name = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/img/@alt')
# 保存到本地
for src, name in zip(src, name):
file_name = name + ".jpg"
img = requests.get(src, headers=headers).content
with open(path + "/" + file_name, "wb") as f:
f.write(img)
if __name__ == "__main__":
# 列表推导式得到url列表 10页的电影信息 Top250
url_list = ["https://movie.douban.com/top250?start={}&filter=".format(x * 25) for x in range(10)]
for url in url_list:
get_pic(url)
delta = (datetime.datetime.now() - start_time).total_seconds()
print("抓取250张电影封面图用时:{}s".format(delta))
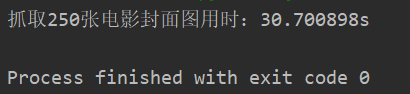
单线程抓取250张电影封面图所用时间:
多线程版
import requests
from lxml import etree
import datetime
from concurrent.futures import ThreadPoolExecutor
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/21.0.1180.89 Safari/537.1"
}
# 设置保存路径 保存到指定文件夹 路径复制过来
path = input("请输入保存路径:")
start_time = datetime.datetime.now()
def get_pic(url):
rep = requests.get(url, headers=headers).text
html = etree.HTML(rep)
# 获取电影封面图 电影名称 xpath定位提取 得到的是列表
src = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/img/@src')
name = html.xpath('//*[@id="content"]/div/div[1]/ol/li/div/div[1]/a/img/@alt')
# 保存到本地
for src, name in zip(src, name):
file_name = name + ".jpg"
img = requests.get(src, headers=headers).content
with open(path + "/" + file_name, "wb") as f:
f.write(img)
if __name__ == "__main__":
# 列表推导式得到url列表 10页的电影信息 Top250
url_list = ["https://movie.douban.com/top250?start={}&filter=".format(x * 25) for x in range(10)]
with ThreadPoolExecutor(max_workers=4) as executor:
executor.map(get_pic, url_list)
delta = (datetime.datetime.now() - start_time).total_seconds()
print("抓取250张电影封面图用时:{}s".format(delta))
多线程抓取250张电影封面图所用时间:

程序成功运行,250张电影封面图保存到了本地文件夹,通过比较,开多线程抓取电影封面图,抓取效率有明显提高。
 原创文章 1获赞 1访问量 17
关注
私信
展开阅读全文
原创文章 1获赞 1访问量 17
关注
私信
展开阅读全文
作者:叶庭云