python爬取豆瓣电影Top250(小白系列)
本文是作者在通过B站跟着李巍老师学习以后所写,记一次学习笔记,自己为了方便自己以后回顾模仿 。
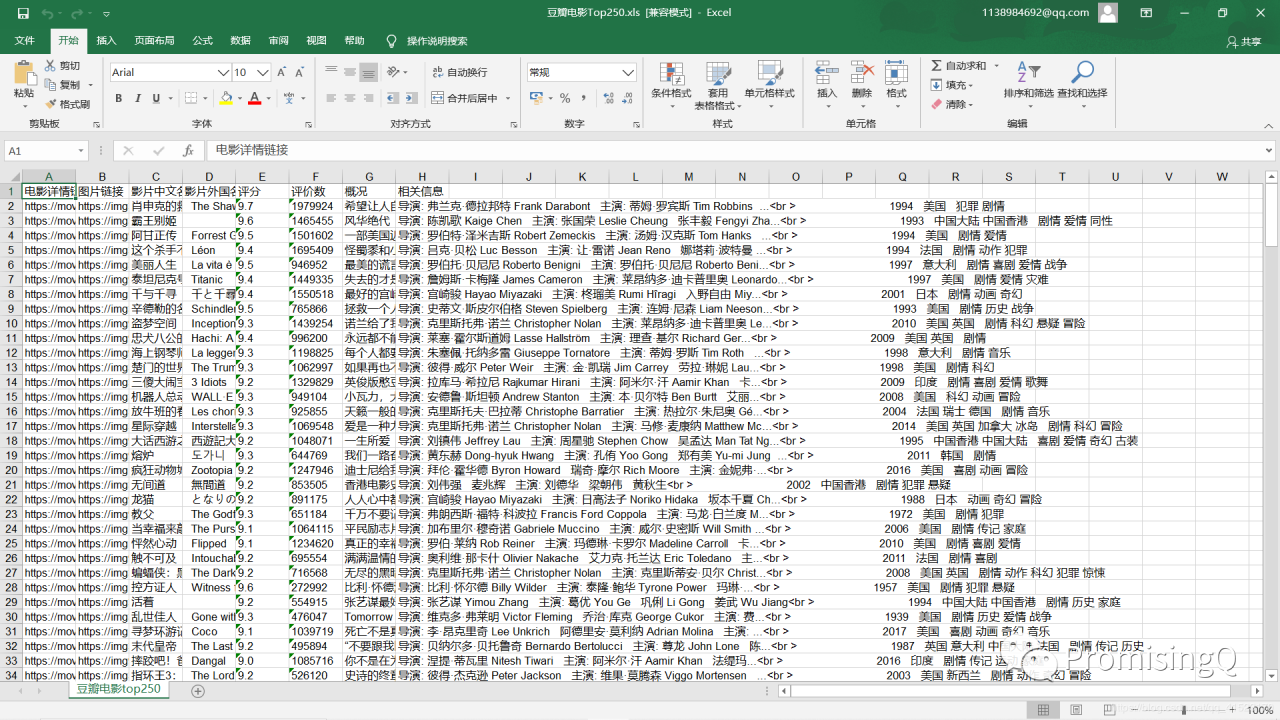
本文是最终爬取排行榜,相关知识储备在我的微信公共号(名称:PromisingQ)已发,后续还会不定期更新:
 bd = re.sub('/'," ",bd) #去掉/
data.append(bd.strip()) #去掉前后的空格
datalist.append(data) #把处理好的一部电影信息放入;list
#print(data)
return datalist
#得到指定一个url的网页内容
def askURL(url):
head = { #模拟浏览器头部信息,向豆瓣服务器发送信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
#用户代理,告诉豆瓣服务器我们是什么类型的机器、浏览器(本质上是告诉浏览器我们可以接收什么水平的内容)
request = urllib.request.Request(url,headers = head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#3.保存数据
def saveData(datalist,savepath):
print('save...')
book = xlwt.Workbook(encoding = "utf-8",style_compression = 0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影top250',cell_overwrite_ok = True) #创建工作表,可覆盖
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i])#列名
for i in range(0,250):
print("第%d条:"%(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
if __name__ == "__main__": #当程序执行时
#调用函数
main()
print("爬取完毕!")
bd = re.sub('/'," ",bd) #去掉/
data.append(bd.strip()) #去掉前后的空格
datalist.append(data) #把处理好的一部电影信息放入;list
#print(data)
return datalist
#得到指定一个url的网页内容
def askURL(url):
head = { #模拟浏览器头部信息,向豆瓣服务器发送信息
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36"
}
#用户代理,告诉豆瓣服务器我们是什么类型的机器、浏览器(本质上是告诉浏览器我们可以接收什么水平的内容)
request = urllib.request.Request(url,headers = head)
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
#print(html)
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
return html
#3.保存数据
def saveData(datalist,savepath):
print('save...')
book = xlwt.Workbook(encoding = "utf-8",style_compression = 0) #创建workbook对象
sheet = book.add_sheet('豆瓣电影top250',cell_overwrite_ok = True) #创建工作表,可覆盖
col = ("电影详情链接","图片链接","影片中文名","影片外国名","评分","评价数","概况","相关信息")
for i in range(0,8):
sheet.write(0,i,col[i])#列名
for i in range(0,250):
print("第%d条:"%(i+1))
data = datalist[i]
for j in range(0,8):
sheet.write(i+1,j,data[j]) #数据
book.save(savepath) #保存
if __name__ == "__main__": #当程序执行时
#调用函数
main()
print("爬取完毕!")
运行结果如下图所示:

最后附上公众号的二维码,大家一起探讨,一起进步!

作者:Qian途