十行Python代码爬取豆瓣电影Top250信息
十行Python代码爬取豆瓣电影Top250信息实验环境爬取网页内容1、确认我们需要爬取的内容2、获取请求头信息3、使用requests模拟连接并获取网页HTML解析网页内容1、查看爬取到的HTML,确定需要解析的HTML数据内容2、使用pyquery对获取的HTML进行解析模拟翻页浓缩代码
作者:WaltonZhong
相信大家都有过找片两小时,找到累了不想看的经历吧,给大家个建议:在豆瓣高分电影排行榜上挨部看下去,高效不纠结,还都是好片。
今天讲的实例就是用Python爬取豆瓣Top250的电影信息(包含电影排名、电影名、评分、链接),仅用十行代码即可实现,内容简单易上手,小白看完也能学会。
整个流程分为爬取数据、解析数据两个部分,首先先看一下实验环境:
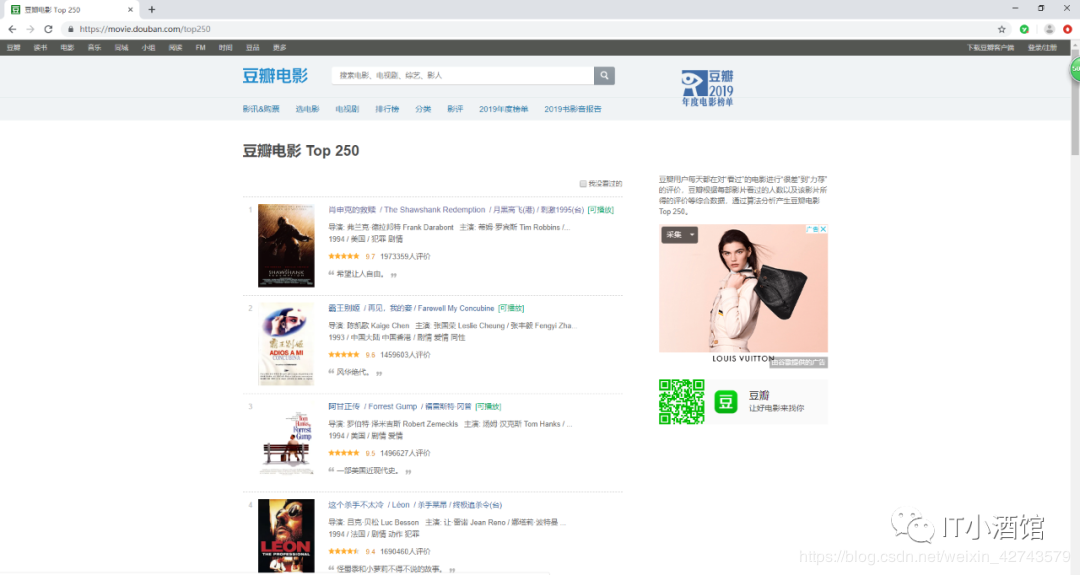
实验环境 Windows 10 Python 3.7.3 使用库: requests pyquery 爬取网页内容 1、确认我们需要爬取的内容https://movie.douban.com/top250
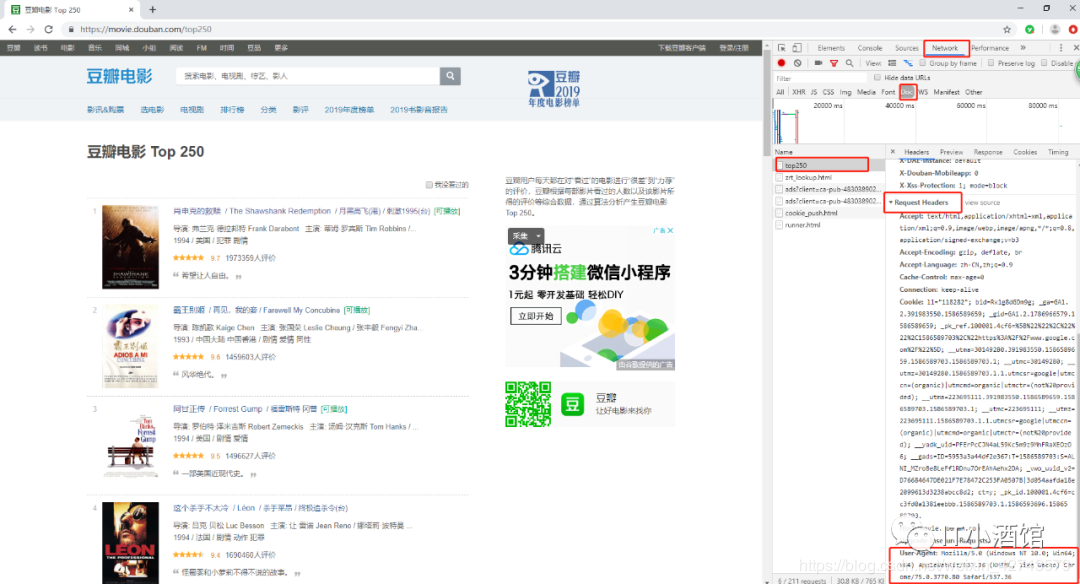
按F12查看网页审查元素并刷新网页,找到连接请求头,复制浏览器信息(因为当前很多网站都有反爬机制,如果模拟连接时不带如Host、User-Agent等信息将会被拒绝连接,此站仅需User-Agent即可)
import requests
from pyquery import PyQuery as pq
url = 'https://movie.douban.com/top250'
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'
}
response = requests.get(url, headers=header).text
print(response)
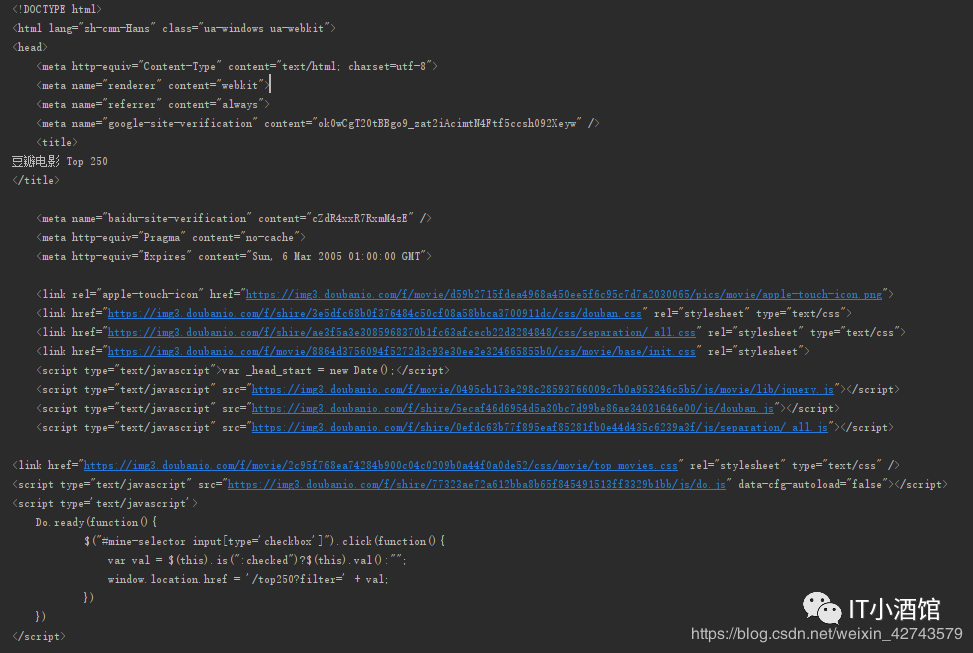
部分HTML内容如下:

html = pq(response)
for item in html('.item').items():
num = item.find('.pic em').text()
title = item.find('.title').html()
link = item.find('.pic a').attr('href')
star = item.find('.rating_num').text()
print(num, title, star, link)
内容输出:

到这里其实已经基本输出我们想要的内容了,但是细心的同学可能发现了,输出的内容只有25条,而不是我们想要的250条。这是因为我们只获取了第一页的内容,而查看网站发现网站总共是有10页的,我们还需实现模拟翻页才能实现效果。
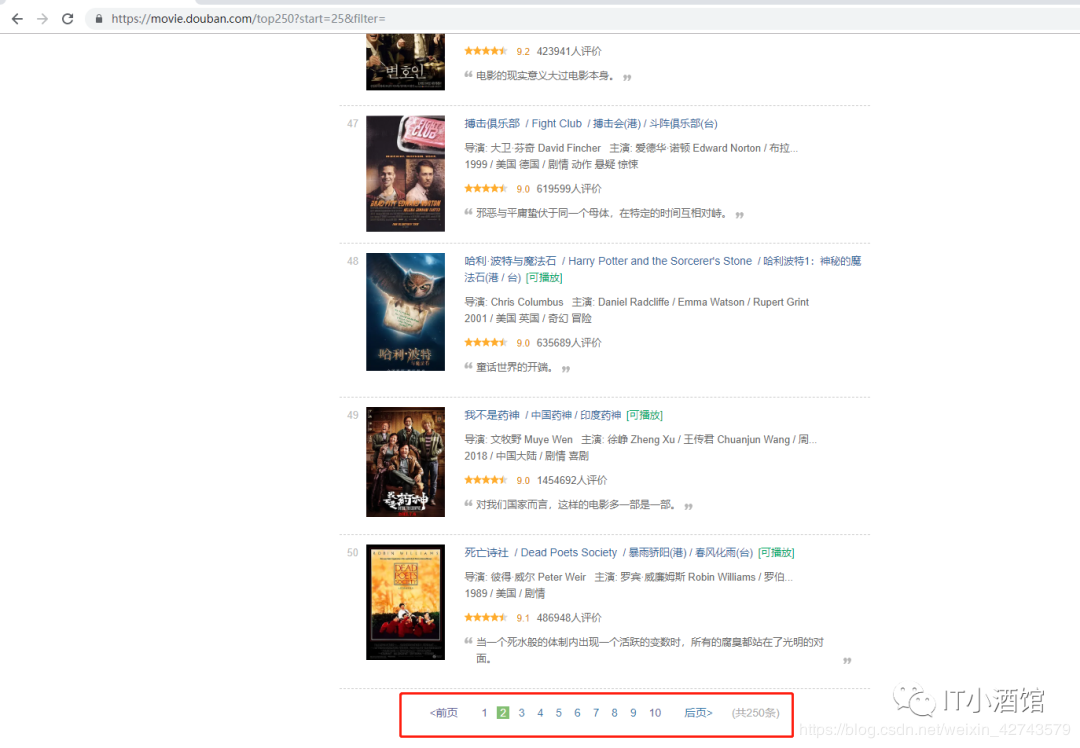
我们对比一下第1、2、10页的url
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=225&filter=
不难发现,每页的索引起始值都是25的整数倍,因为每页都仅展示25部电影信息,所以我们可以在url上做个循环,实现逐页爬取,代码如下:
for page in range(0,250,25):
url = 'https://movie.douban.com/top250?start={}'.format(page)
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'
}
response = requests.get(url, headers=header).text
html = pq(response)
for item in html('.item').items():
num = item.find('.pic em').text()
title = item.find('.title').html()
link = item.find('.pic a').attr('href')
star = item.find('.rating_num').text()
print(num, title, star, link)
结果输入:
其实到这里就已经实现了所有功能了,但是毕竟标题是写的十行代码实现,不能做标题党,这逼还是得装完…
浓缩代码:
import requests
from pyquery import PyQuery as pq
for url in ['https://movie.douban.com/top250?start={}'.format(page) for page in range(0,250,25)]:
html = pq(requests.get(url, headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.80 Safari/537.36'}).text)
for item in html('.item').items():
num = item.find('.pic em').text()
title = item.find('.title').html()
link = item.find('.pic a').attr('href')
star = item.find('.rating_num').text()
print(num, title, star, link)
不多不少,十行刚好~
以上是本期的所有内容,感谢您的阅读~
希望每个看完本文的您都能有所收获,如果您觉得本文不错,可以点一波关注或者关注一下我的公众号~
您的支持是我最大的动力!

作者:WaltonZhong