Python 3 最新有道翻译爬取,破解反爬机制,解决{"errorCode":50}错误
文章目录问题有人说:需要修改URL继续完成完美的爬取!附上python3爬取完美代码:补充说明
问题
作者:倚剑天客
因为有道翻译有反爬机制,所以简单的爬肯定不行,最近用Python3 写了一个爬虫程序……
然而,返回结果却是{“errorCode”:50},百感交集。
我的URL:http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule
需要修改成http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule
就是把_o去掉,去掉之后确实能够正常翻译,既能中译英,也能英译中,但是不知道为什么非要这样做,而且貌似效果不是特别好,如果有大牛知道这两个url的区别还请告知,多谢!
从Form Data中分析原因得知,salt,sign,ts三个参数值是动态变化的,每次请求其值都不同,这表明网站对这三个参数作出了加密反爬机制,若想取得数据,就必须先破解其加密机制。
观察这几个参数,猜测salt和ts参数与时间戳有关,具体使用了何种加密方式,还要去看网页代码元素。
右键,查看网页源代码,在html中并没有找到对应参数,那么就可能在js文件中,在网页的最后一部分代码,根据js文件的文件名,猜测这几个参数的获取方式可能在"fanyi.min.js"文件中。
打开该js文件,发现这个文件是处理过的 js,直接看是难以看出逻辑的,所以可以把 js 代码放到一些可以重新排版的工具中再查看,如在线“站长工具”
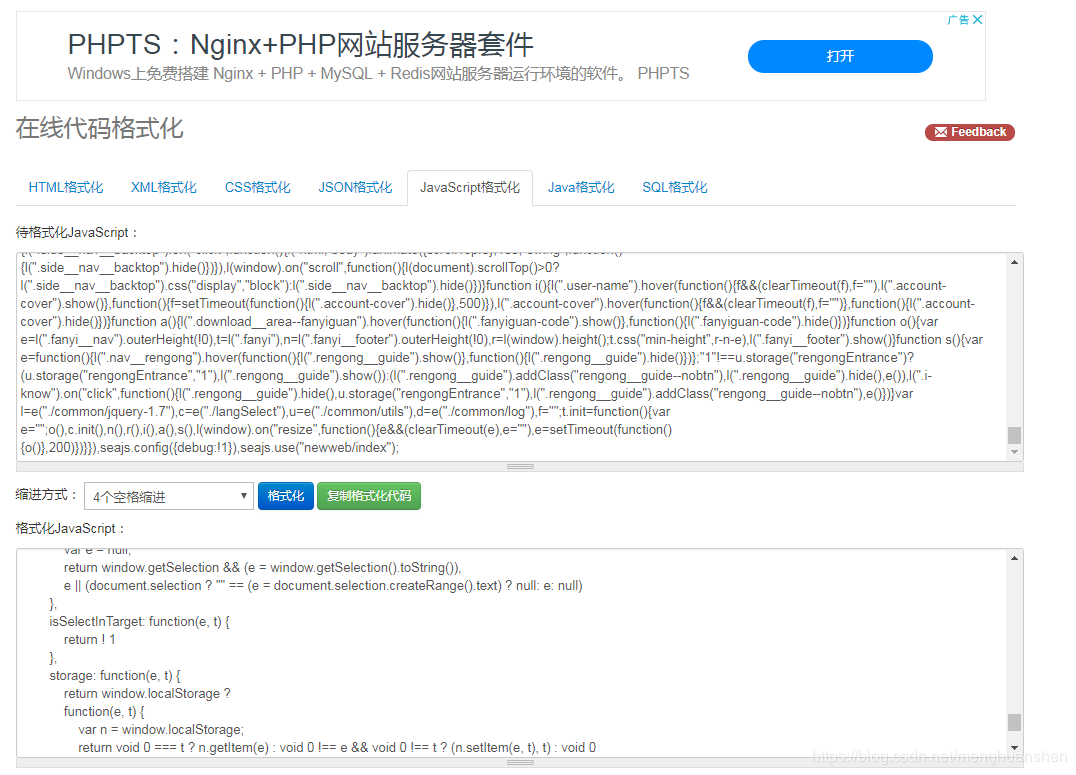
最后可以通过搜索“salt”找到几个参数的生成位置,具体代码片段如下:

从上述参数生成代码中,可知:
(1)网站采用的是md5加密
(2)ts = "" + (new Date).getTime() ,为时间戳
(3)salt = "" + (new Date).getTime() + parseInt(10 * Math.random(), 10)
(4)sign = n.md5("fanyideskweb" + e + i + "@6f#X3=cCuncYssPsuRUE")
其中,e为要翻译内容,i为时间戳,等于ts,其余为固定字符串
明确参数获取方式后,即可编写python代码,破解反爬虫机制。
附上python3爬取完美代码:import hashlib
import random
import time
import urllib.request as requests
import json
import urllib.parse
"""
向有道翻译发送data,得到翻译结果
"""
class Youdao:
def __init__(self, msg):
self.msg = msg
self.url = 'http://fanyi.youdao.com/translate_o?smartresult=dict&smartresult=rule'
self.D = "Nw(nmmbP%A-r6U3EUn]Aj"
self.salt = self.get_salt()
self.sign = self.get_sign()
self.ts = self.get_ts()
def get_md(self, value):
# md5加密
m = hashlib.md5()
# m.update(value)
m.update(value.encode('utf-8'))
return m.hexdigest()
def get_salt(self):
# 根据当前时间戳获取salt参数
s = int(time.time() * 1000) + random.randint(0, 10)
return str(s)
def get_sign(self):
# 使用md5函数和其他参数,得到sign参数
s = "fanyideskweb" + self.msg + self.salt + self.D
return self.get_md(s)
def get_ts(self):
# 根据当前时间戳获取ts参数
s = int(time.time() * 1000)
return str(s)
def get_result(self):
Form_Data = {
'i': self.msg,
'type': 'AUTO',
'smartresult': 'dict',
'client': 'fanyideskweb',
'salt': self.salt,
'sign': self.sign,
'ts': self.ts,
'bv': 'c6b8c998b2cbaa29bd94afc223bc106c',
'doctype': 'json',
'version': '2.1',
'keyfrom': 'fanyi.web',
'ue' : 'UTF-8',
'typoResult': 'true',
'action': 'FY_BY_CLICKBUTTION'
}
Form_Data = urllib.parse.urlencode(Form_Data).encode('utf-8')
headers = {
# 'Accept': 'application/json, text/javascript, */*; q=0.01',
# 'Accept-Encoding': 'gzip, deflate',
# 'Accept-Language': 'zh-CN,zh;q=0.9,mt;q=0.8',
# 'Connection': 'keep-alive',
# 'Content-Length': '240',
# 'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'OUTFOX_SEARCH_USER_ID=-2022895048@10.168.8.76;',
# 'Host': 'fanyi.youdao.com',
# 'Origin': 'http://fanyi.youdao.com',
'Referer': 'http://fanyi.youdao.com/',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; rv:51.0) Gecko/20100101 Firefox/51.0',
# 'X-Requested-With': 'XMLHttpRequest'
}
req = requests.Request(self.url, Form_Data, headers, method='POST')
response = requests.urlopen(req)
html = response.read().decode('utf-8')
translate_results = json.loads(html)
# 找到翻译结果
if 'translateResult' in translate_results:
translate_results = translate_results['translateResult'][0][0]['tgt']
print("翻译的结果是:%s" % translate_results)
else:
print(translate_results)
if __name__ == "__main__":
y = Youdao('I am a soldier, LiLi the grass,wildfires burn born again when the spring breeze the spring, you are a silly force, I love you')
y.get_result()
运行结果如下:
翻译的结果是:我是一名战士,丽丽的小草,野火烧尽时又重生春风春,你是一股傻傻的力量,我爱你
如果是修改_o的翻译结果如下:
翻译的结果是:我是一个士兵,丽丽的草,野火烧重生春风春时,你是一个傻,我爱你
补充说明
如果你用我的程序挂了,那很有可能是这个字符串的问题:
self.D = "Nw(nmmbP%A-r6U3EUn]Aj" #这个字符串是关键
作者:倚剑天客