python用baidu-aip进行数字识别
一、背景
作者:J符离
得到一张数据表如下,现在想把图片中的数字提取出来,之前一直是用在线转换网站:https://ocr.wdku.net/进行处理,结果今天用太频繁了,不让我免费用,居然想跟我收钱,我怎么可能交这种钱呢,于是就打算自己花点时间试试强大的python。
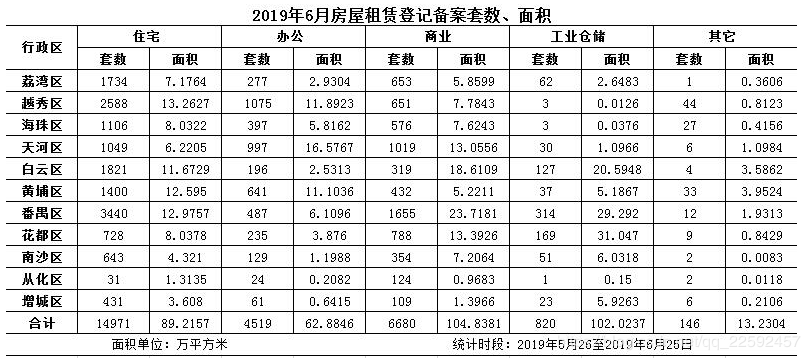
进行图片识别最常用有2种方式,一种是用tesserocr库,需要先安装tesseract,在之前已经玩过,具体可看之前的文章《python 爬取自如网租房信息(解决照片价格问题)》;第二种方式使用百度AI。
使用百度AI需要先申请接口
申请地址:http://ai.baidu.com/
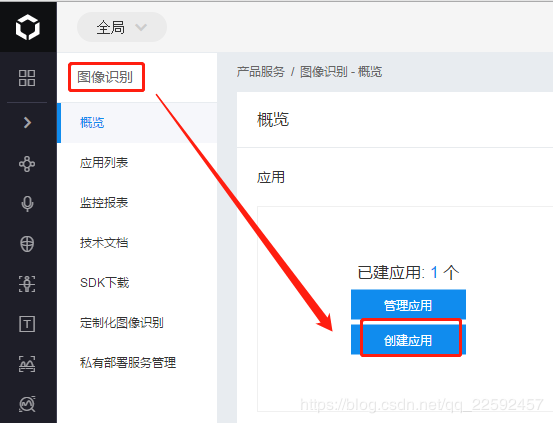
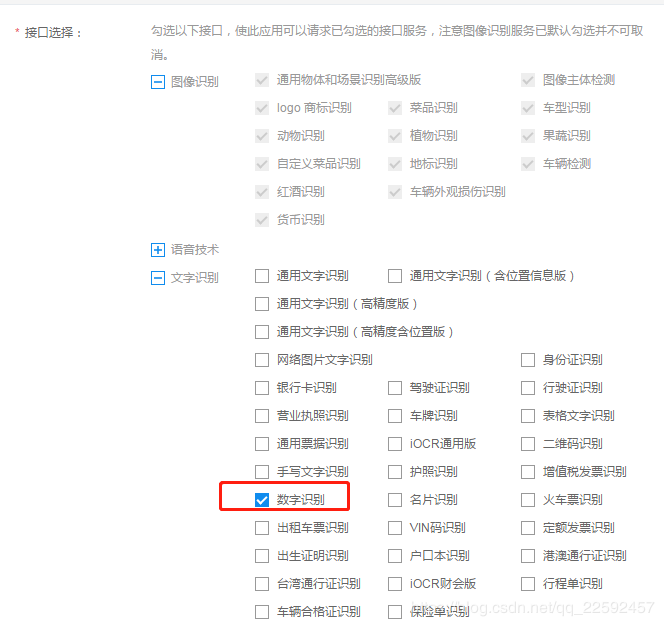
登陆后,选择图像识别–创建应用–选择“数字识别”,然后给应用命名
成功后应用列表会有这么一列,这三个参数就是你要用到的

先用pip install baidu-aip将库装上,然后把库导进来
import os
from aip import AipOcr
# 定义常量,请用你刚才自己申请的AI接口
APP_ID = '18508112'
API_KEY = 'MBENTsZcwWLO8*****'# 公钥
SECRET_KEY = 'zcztKxB7WuQSAbA6Cwp***' # 密钥
aipOcr = AipOcr(APP_ID, API_KEY, SECRET_KEY) # 初始化AipFace对象
AipOcr有很多种方法

这里我们只是用数字识别的方法numbers,具体各种方法的使用可以到百度AI网站上查一下:https://ai.baidu.com/ai-doc/OCR/Ok3h7y1vo
Path="E:/tables/" # 读取图片
all_picture_Path = os.listdir(Path) #统计文件下图片个数
def get_content(picturePath):
with open(picturePath, 'rb') as fp:
return fp.read()
for picture in all_picture_Path:
pic = get_content(Path+picture)
res = aipOcr.numbers(pic,options=None)
for i in range(0,len(res['words_result'])):
print(res['words_result'][i]['words'])
代码挺简单就实现了,然鹅,结果感人,解析出来的数字糟糕得不行
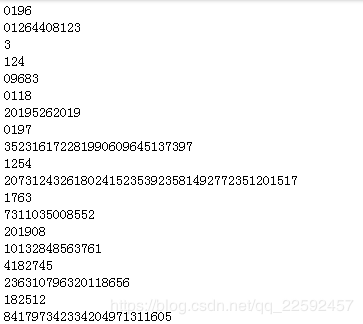
同样是上面的素材,我又用tesserocr的方法跑了一遍,结果一样,都没办法解析出来完整的信息。看来直接对复杂图表照片的解析,这些简单的识别方法还是不能满足要求。
又尝试了一下,如果是解析下面这种图片,百度AI能完美解析出来。
![]()
大概率情况下,如果图片要素不多,没有复杂的干扰(如我图片结构或文字说明等),百度AI和tesserocr都能很好的解析出来,但是一旦图表复杂了,这两种方法都很难生效。
作者:J符离