python:目标检测模型预测准确度计算方式(基于IoU)
训练完目标检测模型之后,需要评价其性能,在不同的阈值下的准确度是多少,有没有漏检,在这里基于IoU(Intersection over Union)来计算。
希望能提供一些思路,如果觉得有用欢迎赞我表扬我~
IoU的值可以理解为系统预测出来的框与原来图片中标记的框的重合程度。系统预测出来的框是利用目标检测模型对测试数据集进行识别得到的。
计算方法即检测结果DetectionResult与GroundTruth的交集比上它们的并集,如下图:
蓝色的框是:GroundTruth
黄色的框是:DetectionResult
绿色的框是:DetectionResult ⋂GroundTruth
红色的框是:DetectionResult ⋃GroundTruth
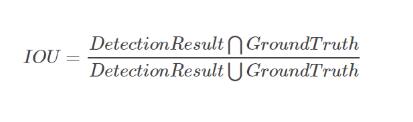

基本思路是先读取原来图中标记的框信息,对每一张图,把所需要的那一个类别的框拿出来,与测试集上识别出来的框进行比较,计算IoU,选择最大的值作为当前框的IoU值,然后通过设定的阈值(漏检0, 0.3, 0.5, 0.7)来进行比较统计,最后得到每个阈值下的所有的判定为正确检测(IoU值大于阈值)的框的数量,然后与原本的标记框的数量一起计算准确度。
其中计算IoU的时候是重新构建一个背景为0的图,设定框所在的位置为1,分别利用原本标注的框和测试识别的框来构建两个这样的图,两者相加就能够让重叠的部分变成2,于是就可以知道重叠部分的大小(交集),从而计算IoU。
构建代码如下:
#读取txt-标准txt为基准-分类别求阈值-阈值为0. 0.3 0.5 0.7的统计
import glob
import os
import numpy as np
#设定的阈值
threshold1=0.3
threshold2=0.5
threshold3=0.7
#阈值计数器
counter0=0
counter1=0
counter2=0
counter3=0
stdtxt=''#标注txt路径
testtxt=''#测试txt路径
txtlist=glob.glob(r'%s\*.txt' %stdtxt)#获取所有txt文件
for path in txtlist:#对每个txt操作
txtname=os.path.basename(path)[:-4]#获取txt文件名
label=1
eachtxt=np.loadtxt(path) #读取文件
for line in eachtxt:
if line[0]==label:
#构建背景为0框为1的图
map1=np.zeros((960,1280))
map1[line[2]:(line[2]+line[4]),line[1]:(line[1]+line[3])]=1
testfile=np.loadtxt(testtxt + txtname + '.txt')
c=0
iou_list=[]#用来存储所有iou的集合
for tline in testfile:#对测试txt的每行进行操作
if tline[0]==label:
c=c+1
map2=np.zeros((960,1280))
map2[tline[2]:(tline[2]+tline[4]),tline[1]:(tline[1]+tline[3])]=1
map3=map1+map2
a=0
for i in map3:
if i==2:
a=a+1
iou=a/(line[3]*line[4]+tline[3]*tline[4]-a)#计算iou
iou_list.append(iou)#添加到集合尾部
threshold=max(iou_list)#阈值取最大的
#阈值统计
if threshold>=threshold3:
counter3=counter3+1
elif threshold>=threshold2:
counter2=counter2+1
elif threshold>=threshold1:
counter1=counter1+1
elif threshold<threshold1:#漏检
counter0=counter0+1
以上这篇python:目标检测模型预测准确度计算方式(基于IoU)就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持软件开发网。
您可能感兴趣的文章:Python计算机视觉里的IOU计算实例python实现BP神经网络回归预测模型python实现的Iou与Giou代码