Python 详解通过Scrapy框架实现爬取CSDN全站热榜标题热词流程
前言
环境部署
实现过程
创建项目
定义Item实体
关键词提取工具
爬虫构造
中间件代码构造
制作自定义pipeline
settings配置
执行主程序
执行结果
总结
前言接着我的上一篇:Python 详解爬取并统计CSDN全站热榜标题关键词词频流程
我换成Scrapy架构也实现了一遍。获取页面源码底层原理是一样的,Scrapy架构更系统一些。下面我会把需要注意的问题,也说明一下。
提供一下GitHub仓库地址:github本项目地址
环境部署scrapy安装
pip install scrapy -i https://pypi.douban.com/simple
selenium安装
pip install selenium -i https://pypi.douban.com/simple
jieba安装
pip install jieba -i https://pypi.douban.com/simple
IDE:PyCharm
google chrome driver下载对应版本:google chrome driver下载地址
检查浏览器版本,下载对应版本。
下面开始搞起。
创建项目使用scrapy命令创建我们的项目。
scrapy startproject csdn_hot_words
项目结构,如同官方给出的结构。
按照之前的逻辑,主要属性为标题关键词对应出现次数的字典。代码如下:
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnHotWordsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
words = scrapy.Field()
关键词提取工具
使用jieba分词获取工具。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/11/5 23:47
# @Author : 至尊宝
# @Site :
# @File : analyse_sentence.py
import jieba.analyse
def get_key_word(sentence):
result_dic = {}
words_lis = jieba.analyse.extract_tags(
sentence, topK=3, withWeight=True, allowPOS=())
for word, flag in words_lis:
if word in result_dic:
result_dic[word] += 1
else:
result_dic[word] = 1
return result_dic
爬虫构造
这里需要给爬虫初始化一个浏览器参数,用来实现页面的动态加载。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/11/5 23:47
# @Author : 至尊宝
# @Site :
# @File : csdn.py
import scrapy
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from csdn_hot_words.items import CsdnHotWordsItem
from csdn_hot_words.tools.analyse_sentence import get_key_word
class CsdnSpider(scrapy.Spider):
name = 'csdn'
# allowed_domains = ['blog.csdn.net']
start_urls = ['https://blog.csdn.net/rank/list']
def __init__(self):
chrome_options = Options()
chrome_options.add_argument('--headless') # 使用无头谷歌浏览器模式
chrome_options.add_argument('--disable-gpu')
chrome_options.add_argument('--no-sandbox')
self.browser = webdriver.Chrome(chrome_options=chrome_options,
executable_path="E:\\chromedriver_win32\\chromedriver.exe")
self.browser.set_page_load_timeout(30)
def parse(self, response, **kwargs):
titles = response.xpath("//div[@class='hosetitem-title']/a/text()")
for x in titles:
item = CsdnHotWordsItem()
item['words'] = get_key_word(x.get())
yield item
代码说明
1、这里使用的是chrome的无头模式,就不需要有个浏览器打开再访问,都是后台执行的。
2、需要添加chromedriver的执行文件地址。
3、在parse的部分,可以参考之前我文章的xpath,获取到标题并且调用关键词提取,构造item对象。
中间件代码构造添加js代码执行内容。中间件完整代码:
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
from scrapy import signals
from scrapy.http import HtmlResponse
from selenium.common.exceptions import TimeoutException
import time
from selenium.webdriver.chrome.options import Options
# useful for handling different item types with a single interface
from itemadapter import is_item, ItemAdapter
class CsdnHotWordsSpiderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_spider_input(self, response, spider):
# Called for each response that goes through the spider
# middleware and into the spider.
# Should return None or raise an exception.
return None
def process_spider_output(self, response, result, spider):
# Called with the results returned from the Spider, after
# it has processed the response.
# Must return an iterable of Request, or item objects.
for i in result:
yield i
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
def process_start_requests(self, start_requests, spider):
# Called with the start requests of the spider, and works
# similarly to the process_spider_output() method, except
# that it doesn't have a response associated.
# Must return only requests (not items).
for r in start_requests:
yield r
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
class CsdnHotWordsDownloaderMiddleware:
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
def process_request(self, request, spider):
js = '''
let height = 0
let interval = setInterval(() => {
window.scrollTo({
top: height,
behavior: "smooth"
});
height += 500
}, 500);
setTimeout(() => {
clearInterval(interval)
}, 20000);
'''
try:
spider.browser.get(request.url)
spider.browser.execute_script(js)
time.sleep(20)
return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source,
encoding="utf-8", request=request)
except TimeoutException as e:
print('超时异常:{}'.format(e))
spider.browser.execute_script('window.stop()')
finally:
spider.browser.close()
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
return response
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
制作自定义pipeline
定义按照词频统计最终结果输出到文件。代码如下:
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
from itemadapter import ItemAdapter
class CsdnHotWordsPipeline:
def __init__(self):
self.file = open('result.txt', 'w', encoding='utf-8')
self.all_words = []
def process_item(self, item, spider):
self.all_words.append(item)
return item
def close_spider(self, spider):
key_word_dic = {}
for y in self.all_words:
print(y)
for k, v in y['words'].items():
if k.lower() in key_word_dic:
key_word_dic[k.lower()] += v
else:
key_word_dic[k.lower()] = v
word_count_sort = sorted(key_word_dic.items(),
key=lambda x: x[1], reverse=True)
for word in word_count_sort:
self.file.write('{},{}\n'.format(word[0], word[1]))
self.file.close()
settings配置
配置上要做一些调整。如下调整:
# Scrapy settings for csdn_hot_words project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# https://docs.scrapy.org/en/latest/topics/settings.html
# https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'csdn_hot_words'
SPIDER_MODULES = ['csdn_hot_words.spiders']
NEWSPIDER_MODULE = 'csdn_hot_words.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
# USER_AGENT = 'csdn_hot_words (+http://www.yourdomain.com)'
USER_AGENT = 'Mozilla/5.0'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
# CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
DOWNLOAD_DELAY = 30
# The download delay setting will honor only one of:
# CONCURRENT_REQUESTS_PER_DOMAIN = 16
# CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
# TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent': 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/27.0.1453.94 Safari/537.36'
}
# Enable or disable spider middlewares
# See https://docs.scrapy.org/en/latest/topics/spider-middleware.html
SPIDER_MIDDLEWARES = {
'csdn_hot_words.middlewares.CsdnHotWordsSpiderMiddleware': 543,
}
# Enable or disable downloader middlewares
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html
DOWNLOADER_MIDDLEWARES = {
'csdn_hot_words.middlewares.CsdnHotWordsDownloaderMiddleware': 543,
}
# Enable or disable extensions
# See https://docs.scrapy.org/en/latest/topics/extensions.html
# EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
# }
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'csdn_hot_words.pipelines.CsdnHotWordsPipeline': 300,
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/autothrottle.html
# AUTOTHROTTLE_ENABLED = True
# The initial download delay
# AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
# AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
# AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
# AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
# HTTPCACHE_ENABLED = True
# HTTPCACHE_EXPIRATION_SECS = 0
# HTTPCACHE_DIR = 'httpcache'
# HTTPCACHE_IGNORE_HTTP_CODES = []
# HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
执行主程序
可以通过scrapy的命令执行,但是为了看日志方便,加了一个主程序代码。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2021/11/5 22:41
# @Author : 至尊宝
# @Site :
# @File : main.py
from scrapy import cmdline
cmdline.execute('scrapy crawl csdn'.split())
执行结果
执行部分日志
得到result.txt结果。
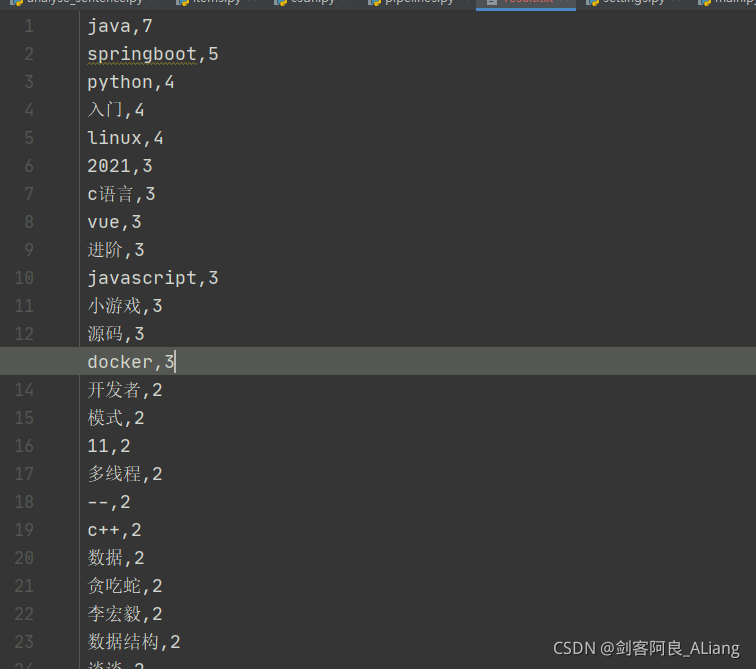
看,java还是yyds。不知道为什么2021这个关键词也可以排名靠前。于是我觉着把我标题也加上2021。
GitHub项目地址在发一遍:github本项目地址
申明一下,本文案例仅研究探索使用,不是为了恶意攻击。
分享:
凡夫俗子不下苦功夫、死力气去努力做成一件事,根本就没资格去谈什么天赋不天赋。
——烽火戏诸侯《剑来》
如果本文对你有用的话,请不要吝啬你的赞,谢谢。

以上就是Python 详解通过Scrapy框架实现爬取CSDN全站热榜标题热词流程的详细内容,更多关于Python Scrapy框架的资料请关注软件开发网其它相关文章!