Python实现爬取马云的微博功能示例
本文实例讲述了Python实现爬取马云的微博功能。分享给大家供大家参考,具体如下:
分析请求
我们打开 Ajax 的 XHR 过滤器,然后一直滑动页面加载新的微博内容,可以看到会不断有Ajax请求发出。
我们选定其中一个请求来分析一下它的参数信息,点击该请求进入详情页面,如图所示:
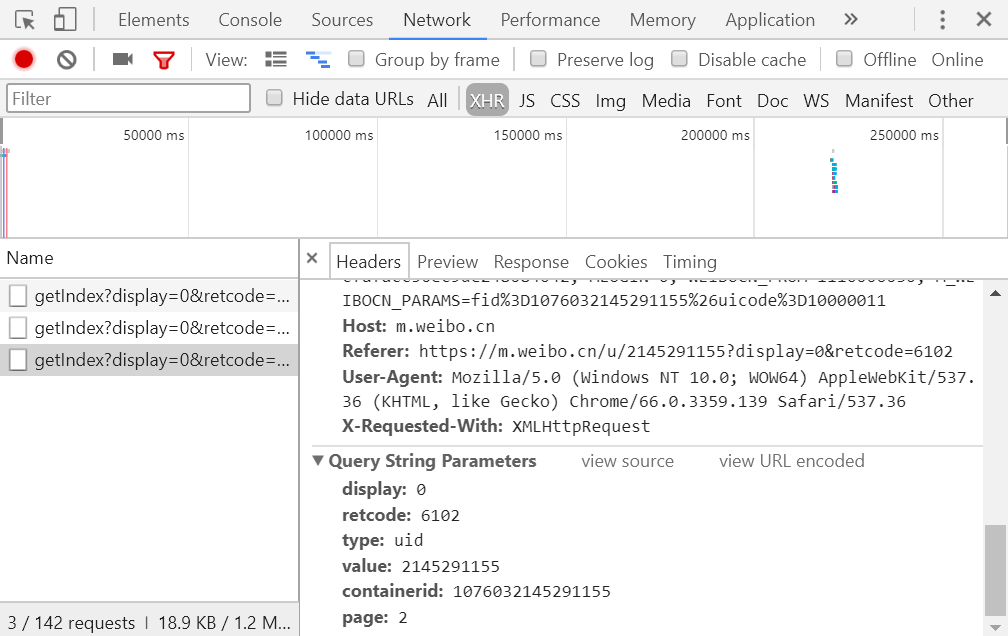
可以发现这是一个 GET 请求,请求的参数有 6 个:display、retcode、type、value、containerid 和 page,观察这些请求可以发现只有 page 在变化,很明显 page 是用来控制分页的。
分析响应
如图所示:
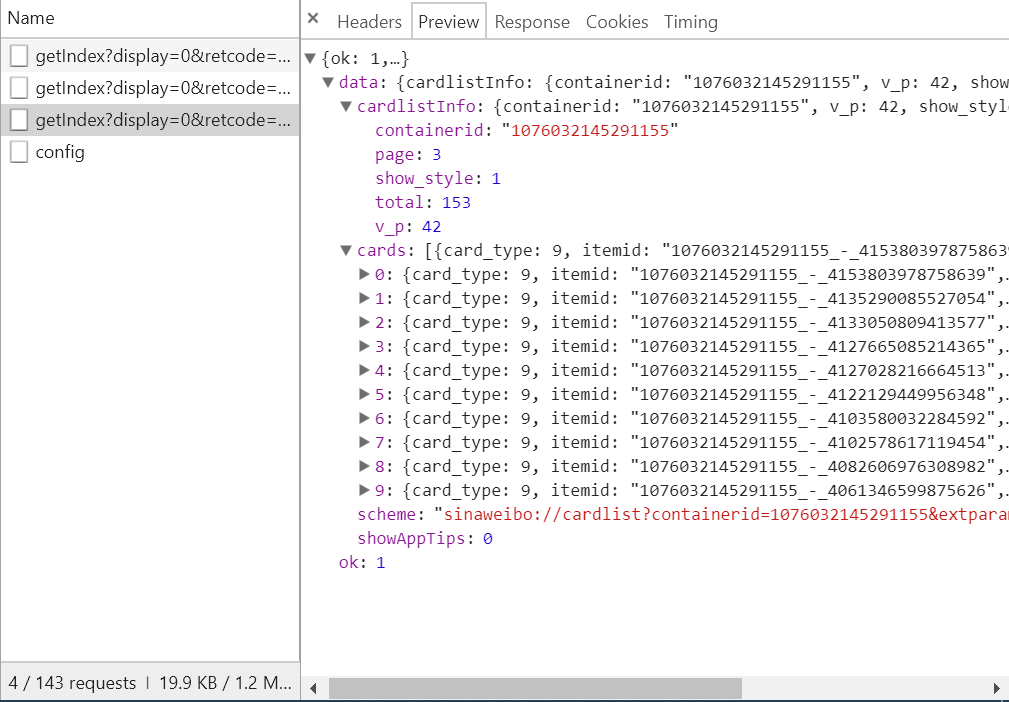
它是一个 Json 格式,浏览器开发者工具自动为做了解析方便我们查看,可以看到最关键的两部分信息就是 cardlistInfo 和 cards,将二者展开,cardlistInfo 里面包含了一个比较重要的信息就是 total,经过观察后发现其实它是微博的总数量,我们可以根据这个数字来估算出分页的数目。
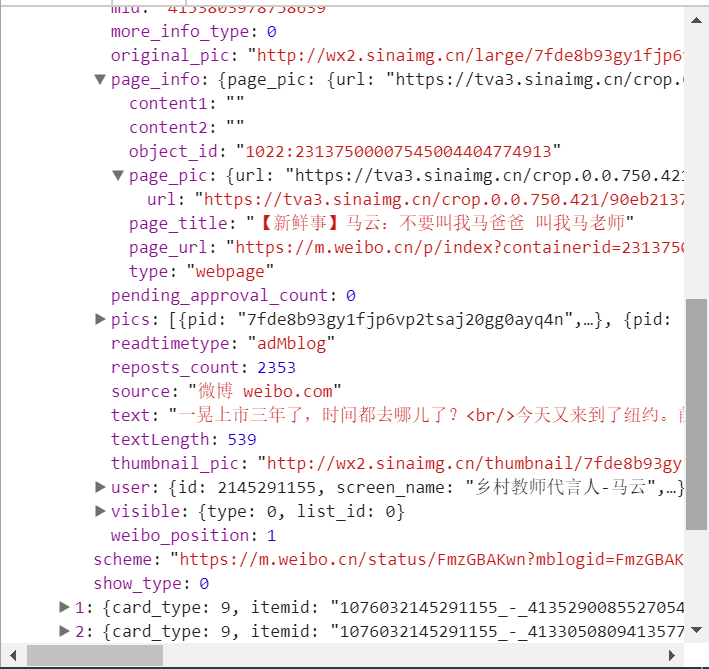
发现它又有一个比较重要的字段,叫做 mblog,继续把它展开,发现它包含的正是微博的一些信息。比如 attitudes_count 赞数目、comments_count 评论数目、reposts_count 转发数目、created_at 发布时间、text 微博正文等等,得来全不费功夫,而且都是一些格式化的内容,所以我们提取信息也更加方便了。
这样我们可以请求一个接口就得到 10 条微博,而且请求的时候只需要改变 page 参数即可。这样我们只需要简单做一个循环就可以获取到所有的微博了。
实战演练
在这里我们就开始用程序来模拟这些 Ajax 请求,将马云的所有微博全部爬取下来。
首先我们定义一个方法,来获取每次请求的结果,在请求时page 是一个可变参数,所以我们将它作为方法的参数传递进来,代码如下:
from urllib.parse import urlencode
import requests
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2145291155',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
def get_page(page):
params = {
'display': '0',
'retcode': '6102',
'type': 'uid',
'value': '2145291155',
'containerid': '1076032145291155',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json()
except requests.ConnectionError as e:
print('Error', e.args)
首先在这里我们定义了一个 base_url 来表示请求的 URL 的前半部分,接下来构造了一个参数字典,其中 display、retcode、 type、value、containerid 是固定的参数,只有 page 是可变参数,接下来我们调用了 urlencode() 方法将参数转化为 URL 的 GET请求参数,即类似于display=0&retcode=6102&type=uid&value=2145291155&containerid=1076032145291155&page=2 这样的形式,随后 base_url 与参数拼合形成一个新的 URL,然后我们用 Requests 请求这个链接,加入 headers 参数,然后判断响应的状态码,如果是200,则直接调用 json() 方法将内容解析为 Json 返回,否则不返回任何信息,如果出现异常则捕获并输出其异常信息。
随后我们需要定义一个解析方法,用来从结果中提取我们想要的信息,比如我们这次想保存微博的 正文、赞数、评论数、转发数这几个内容,那可以先将 cards 遍历,然后获取 mblog 中的各个信息,赋值为一个新的字典返回即可。
from pyquery import PyQuery as pq
def parse_page(json):
if json:
items = json.get('cards')
for item in items:
item = item.get('mblog')
weibo = {}
weibo['微博内容:'] = pq(item.get('text')).text()
weibo['转发数'] = item.get('attitudes_count')
weibo['评论数'] = item.get('comments_count')
weibo['点赞数'] = item.get('reposts_count')
yield weibo
在这里我们借助于 PyQuery 将正文中的 HTML 标签去除掉。
最后我们遍历一下 page,将提取到的结果打印输出即可。
if __name__ == '__main__':
for page in range(1, 50):
json = get_page(page)
results = parse_page(json)
for result in results:
print(result)
另外我们还可以加一个方法将结果保存到 本地 TXT 文件中。
def save_to_txt(result):
with open('马云的微博.txt', 'a', encoding='utf-8') as file:
file.write(str(result) + '\n')
代码整理
import requests
from urllib.parse import urlencode
from pyquery import PyQuery as pq
base_url = 'https://m.weibo.cn/api/container/getIndex?'
headers = {
'Host': 'm.weibo.cn',
'Referer': 'https://m.weibo.cn/u/2145291155',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
}
max_page = 50
def get_page(page):
params = {
'display': '0',
'retcode': '6102',
'type': 'uid',
'value': '2145291155',
'containerid': '1076032145291155',
'page': page
}
url = base_url + urlencode(params)
try:
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.json(), page
except requests.ConnectionError as e:
print('Error', e.args)
def parse_page(json, page: int):
if json:
items = json.get('data').get('cards')
for index, item in enumerate(items):
if page == 1 and index == 1:
continue
else:
item = item.get('mblog')
weibo = {}
weibo['微博内容:'] = pq(item.get('text')).text()
weibo['转发数:'] = item.get('attitudes_count')
weibo['评论数:'] = item.get('comments_count')
weibo['点赞数:'] = item.get('reposts_count')
yield weibo
def save_to_txt(result):
with open('马云的微博.txt', 'a', encoding='utf-8') as file:
file.write(str(result) + '\n')
if __name__ == '__main__':
for page in range(1, max_page + 1):
json = get_page(page)
results = parse_page(*json)
for result in results:
print(result)
save_to_txt(result)
最后结果为:
{'微博内容:': '公安部儿童失踪信息紧急发布平台,现在有了阶段性成果。上线两年时间,发布3053名儿童失踪信息,找回儿童2980名,找回率97.6%……失踪儿童信息会触达到几乎每一个有手机的用户,这对拐卖儿童的犯罪分子更是巨大的震慑!\n为找回孩子的家长欣慰,为这个“互联网+打拐”平台的创建而感动,也 ...全文', '转发数:': 82727, '评论数:': 9756, '点赞数:': 18091}
{'微博内容:': '#马云乡村教师奖#说个喜事:马云乡村教师奖的获奖老师丁茂洲,元旦新婚,新娘也是一名教师。丁老师坦白,他是2015年得了乡村教师奖以后,才被现在的女朋友给“瞄上的”。其实马云乡村教师奖,不光女朋友喜欢,重要的是丈母娘也喜欢!\n丁老师的学校,陕西安康市三星小学,在一个贫困 ...全文', '转发数:': 37030, '评论数:': 8176, '点赞数:': 3931}
{'微博内容:': '双十一结束了,想对300万快递员、对所有物流合作伙伴说声谢谢!你们创造了世界商业的奇迹!双十一的三天里产生了10亿多个包裹,菜鸟网络用了一周的时间送完,抵达世界各个角落,这是世界货运业的奇迹,更是商业世界协同合作的奇迹。10年前,我们不敢想象中国快递 ...全文', '转发数:': 85224, '评论数:': 21615, '点赞数:': 5044}
{'微博内容:': '今晚11.11,准备好了吗?注意休息,开心快乐。姑娘们,今晚是你们的节日。男人们,反正钱是用来花的,花钱不心疼的日子只有今天!', '转发数:': 76803, '评论数:': 22068, '点赞数:': 4773}
本文参考崔庆才的《python3 网络爬虫开发实战》。
更多关于Python相关内容可查看本站专题:《Python Socket编程技巧总结》、《Python正则表达式用法总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》及《Python文件与目录操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
您可能感兴趣的文章:Python网络爬虫之爬取微博热搜python爬虫爬取微博评论案例详解Python爬虫爬取新浪微博内容示例【基于代理IP】利用Python爬取微博数据生成词云图片实例代码详解用python写网络爬虫-爬取新浪微博评论