从朴素贝叶斯到N-gram语言模型_CodingPark
在本文中你将会学到朴素贝叶斯是什么、朴素贝叶斯有什么应用、实际工程上的小技巧等
N-grame是什么、它比朴素贝叶斯好在哪里等
贝叶斯公式 + 条件独立假设 = 朴素贝叶斯
贝叶斯方法是一个历史悠久,有着坚实的理论基础的方法,同时处理很多问题时直接而又高效,很多高级自然语言处理模型也可以从它演化而来。因此,学习贝叶斯方法,是研究自然语言处理问题的一个非常好的切入口。
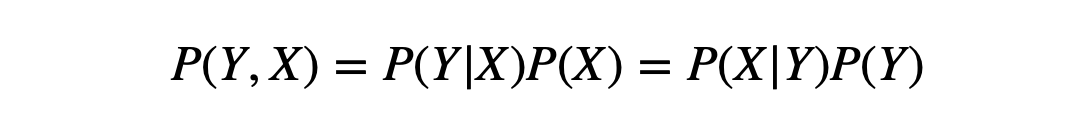
由 联合概率公式 可推导出 贝叶斯公式
贝叶斯公式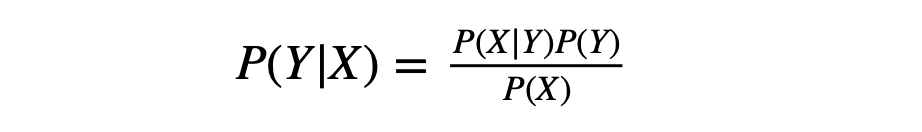
其中 P(Y)叫做先验概率, P(Y|X) 叫做后验概率, P(Y,X)叫做联合概率。
在机器学习的视角下,我们把 X 理解成“具有某特征”
把 Y理解成“类别标签”
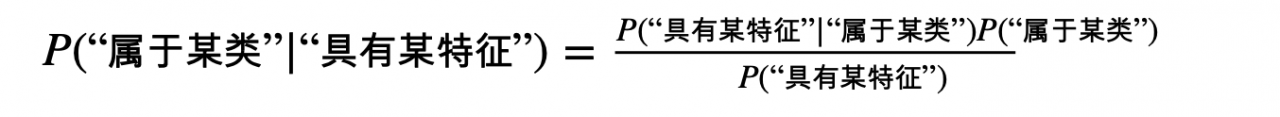
解释上述公式:
P(“属于某类”|“具有某特征”)=在已知某样本“具有某特征”的条件下,该样本“属于某类”的概率。所以叫做后验概率。
P(“具有某特征”|“属于某类”)=在已知某样本“属于某类”的条件下,该样本“具有某特征”的概率(可求)。
P(“属于某类”)=(在未知某样本具有该“具有某特征”的条件下,)该样本“属于某类”的概率。所以叫做先验概率(可求)。
P(“具有某特征”)=(在未知某样本“属于某类”的条件下,)该样本“具有某特征”的概率(可求)。
而我们二分类问题的最终目的就是要判断 P(“属于某类”|“具有某特征”)是否大于1/2就够了。贝叶斯方法把计算“具有某特征的条件下属于某类”的概率转换成需要计算“属于某类的条件下具有某特征”的概率,而后者获取方法就简单多了,我们只需要找到一些包含已知特征标签的样本,即可进行训练。而样本的类别标签都是明确的,所以贝叶斯方法在机器学习里属于有监督学习方法。
分词一个很悲哀但是很现实的结论:训练集是有限的,而句子的可能性则是无限的。所以覆盖所有句子可能性的训练集是不存在的。
解决方法:句子的可能性无限,但是词语就那么些!分词也就是把一整句话拆分成更细粒度的词语来进行表示
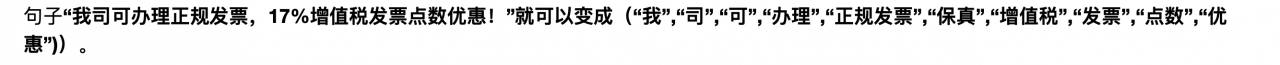
因此贝叶斯公式就变成了:
但是我们可以从公式中发现,这也没法进行计算呀?
上面等式