论文笔记:REV2: Fraudulent User Prediction in Rating Platforms
目录
REV2: Fraudulent User Prediction in Rating Platforms
摘要
介绍
Rev2公式
实验结果
摘要Rating platforms能够获取大规模的items(商品或者其他用户)用户评价。然而,Fraudulent User(欺诈型用户)会因为金钱交易提供虚假的评论。本文提出一种欺诈型用户识别系统:REV2。作者提出三种相互依赖的度量属性:用户公正性、评价可靠性以及产品优劣性。直观地说,如果用户提供了接近产品优劣性分数的评价分数,那么他就是公平的。文中使用六个原理来建立分数之间得依赖性,解决cold start problem并加入了behavior properties。REV2在五个数据集上表现比现有的九个算法好。
介绍本文旨在识别那些利用虚假评论牟利的Fraudulent User,这项任务的难点在于缺乏训练labels、正常用户和欺诈型用户样本比例不均衡、以及存在有伪装的欺诈型用户。
作者给出三个公式来计算用户的可信度、评论的可信度以及产品的优劣性。模型使用双向传播的图结构来模拟用户对产品的评价过程。举个例子,在Amazon平台上,假设一个用户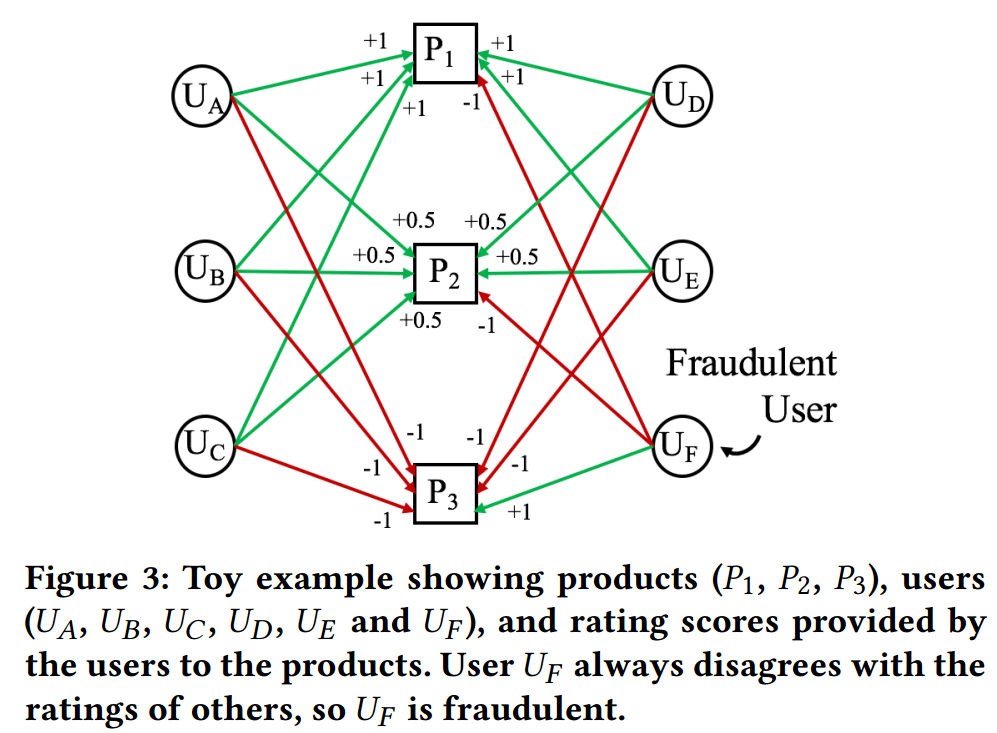
公理6:
对于具有相同的reliabile egonetworks的两个用户,行为得分较高的用户具有较高的公平性。同理可推至评价和产品。
接下来作者开始逐步的提出公式来计算用户公正性分数
关于Cold Start Problem和Behavioral Properties已在公式中做出标注,总计参数7个参数
数据库:Flipkart、Bitcoin OTC、Bitcoin Alpha、Epinions、Amazon
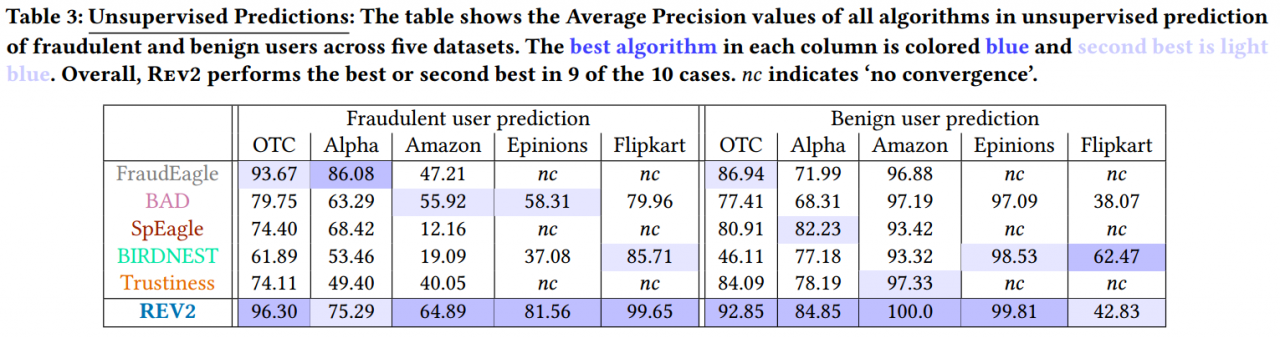
无监督模式实验结果:
监督模式实验结果:
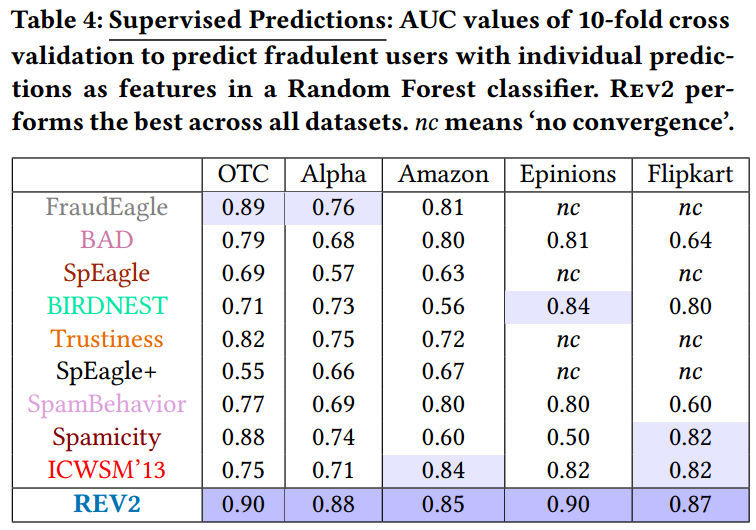
作者总共做了五个实验,分别测试了Rev2算法在无监督模式、监督模式的性能,以及算法鲁棒性和cold start、behavior加入网络的重要性,最后证明Rev2算法的linear scalability。
附:
关于Rev2算法的复现内容将在下一篇博客中介绍,论文中给出的代码问题较多,我会上传修改之后便于运行测试的代码。
作者:Forizon