Extracting Implicit Social Relation for Social Recommendation Techniques in User Rating Prediction
通常来说,推荐模型主要有两个变种,一种是基于内容的,一种是协同过滤。而协同过滤的核心思想就是,利用每一个用户的反馈,来提供推荐。协同过滤又可以进一步分为基于模型的,和基于近邻的(最经典的CF),而基于模型的,只用将预测模型的参数学习到就可以了。
现在,大多推荐模型为了解决冷启动和稀疏问题,正在不遗余力的引入社交网络中的信任关系。然而,这个信任关系,要么是从显式的数据中直接获取的,要么是作为隐式数据从其它数据中推测出来的。这就对于那些没有social network数据的场景,是一个巨大的挑战。而且,那些social network中的噪声和weak tie同样对于trust-based方法的使用造成阻碍(ps:所以作者的研究是有价值的)。
那么这篇文章中,作者提出了一种既利用了显式数据和隐式数据的模型,作者可以在没有trust数据的情况下,从rating数据中提取社交关系,并且RMSE和MSE还可以和普通的社交推荐一样好。
作者在这里提到了一大串利用了信任关系结合评分矩阵做推荐额模型,然后作者提到,“但是它们大多都忽视implicit friendship relation 在推荐过程中的作用”,也就是说这些模型的user relation都是显式的数据,而那些隐式的关系,这些模型并未考虑到。据作者说,这个作者是第一个利用隐式的社交关系来提高推荐accuracy的人。
其次,作者的模型名为HellTrustSVD,其主要创新点主要在从评分矩阵中挖掘隐式的社交关系,而基础的模型则是TrustSVD,主要改进就在TrustSVD的trust矩阵上。
从explicit数据中挖掘出来的social relation 有点近似于两个节点的相似度。
本文选用Hellinger distance(海明格距离)来计算两个节点的距离。选择海明格距离的原因是,这个模型的具有一定的统计性和随机性。两节点间海明格距离的计算主要依赖于两个node的领接节点的度分布概率(先将user-item化为二部图,二部图参考2009年中科院周波的文章)
![]()
之后我们会得到一个N×NN\times NN×N的矩阵,N就是用户的数量,每一行自然就是该用户对其它用户的信任程度,距离少一个阈值就看做一个tie,其实得到的海明格距离也就是tie的强度。
在TrustSVD中,有信任矩阵TTT,其中Ti,jT_i,_jTi,j是由truster u(委托人)和trustee v(受托人)的内积和得来的,即<pu,wv>
,然后再用矩阵分解的思路得到u和v的隐向量做推荐。而作者这篇文章中,作者主要是用从评分矩阵推出的implicit 数据(是一个基于海明格距离的距离矩阵)来替代TrustSVD中的信任矩阵T,其它工作与TrustSVD相同。
Experimental Evaluation首先,作者先肯定他用implicit数据代替explicit数据的这一思路,如图作者利用从评分矩阵中提取出来的距离矩阵来替代信任矩阵,其它部分不变。实验结果如下,发现用距离矩阵和信任矩阵(括号里面是信任矩阵的结果)效果差不多,由此证明implicit数据与explicit数据同样重要的结论。
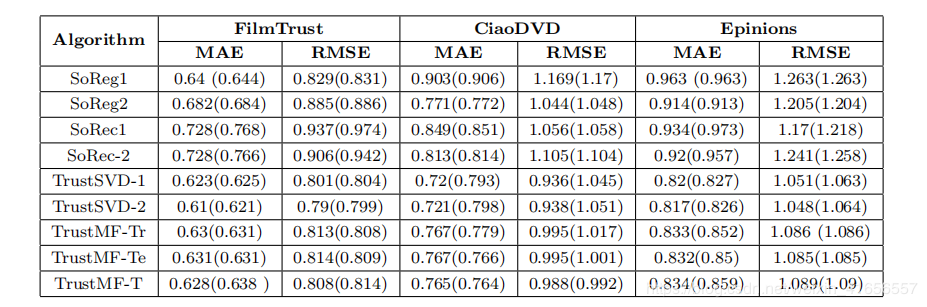
然后作者在movielens上做实验,结果如下
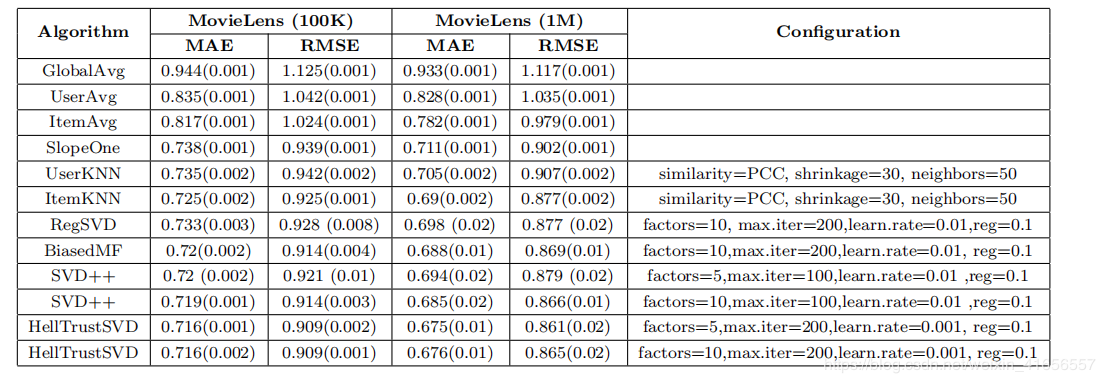
虽然只有1%的提幅(因为这篇文章重点不在于刷分),但是还是可以证明,在trust based模型中,从评分矩阵中提取出来的距离矩阵即implicit数据是可以有效的替代信任矩阵即explicit数据的。这也是本文的核心观点。
总结一下,作者的工作主要是,证明了implicit数据的有效性。作者利用从评分矩阵中提取出来的距离矩阵来替代了显式的trust score,从而达到了有explicit数据一样好的效果。有了这个结论,我们今后在只有评分数据,没有社交关系的情况下,也能跑一些社交推荐的算法,从而从implicit数据的角度提高模型的效果。
在未来,作者觉得可以从评分矩阵或者其它形式的显式数据中提取更多的隐式数据来做推荐。
博主:这篇文章是发表在WWW会议上的一篇论文,说实话WWW会议并不是推荐类型文章的首选,这篇文章还是挺有意义。
1.首先,我感觉这些年,越来越看重底层的特征构建了,数据的特征构建的好,跑模型效果自然就差不了。这篇文章就有那么个意思,从显式数据中推出隐式数据,再用合适的模型去同时跑显式和隐式数据,得到了不亚于显式数据的结果。这其实就是在告诉我们,能否从我们当前的数据中,挖掘出其它的重要信息,这样一起喂到模型里,可能会有更好的效果。
2.其实,我个人觉得作者选择的baseline差了点,感觉说服力不够,而且作者的观点只是想证明implicit数据的有效性而已,何必去刷分呢,刷个1%的提幅,估计完全是依靠玄学调参得到。所以我个人是希望在baseline里面看到更多用到信任矩阵做推荐的算法的。
作者:肖伟崎