PostgreSQL数据聚类——kmeans
数据聚类在实际生活中应用场景还是挺多的,例如一个公司可以将客户进行分类,指定不同的销售策略等。
K-Means算法主要就是解决这类问题。在数据挖掘中, k-Means 算法是一种 cluster analysis 的算法,其主要是来计算数据聚集的算法,主要通过不断地取离种子点最近均值的算法。
介绍K-Means算法前,我们需要先弄清楚分类和聚类这两个概念:
分类:类别是已知的,通过对已知分类的数据进行训练和学习,找到这些不同类的特征,再对未分类的数据进行分类。属于监督学习。
聚类:事先不知道数据会分为几类,通过聚类分析将数据聚合成几个群体。聚类不需要对数据进行训练和学习。属于无监督学习。
这个算法实现过程如下图:
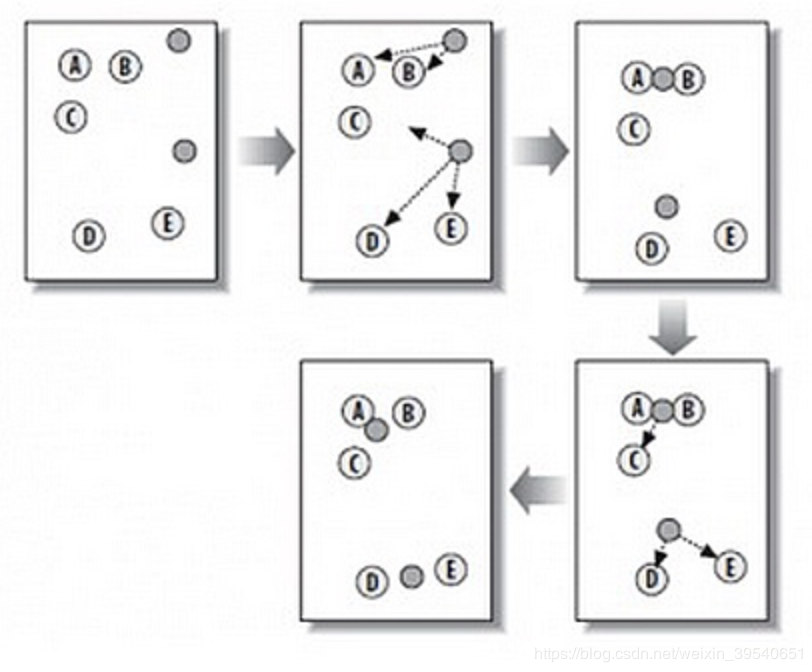
从上图中,我们可以看到,A, B, C, D, E 是五个在图中点。而灰色的点是我们的种子点,也就是我们用来找点群的点。有两个种子点,所以K=2。
然后,K-Means的算法如下:
1、随机在图中取K(这里K=2)个种子点。
2、然后对图中的所有点求到这K个种子点的距离,假如点Pi离种子点Si最近,那么Pi属于Si点群。(上图中,我们可以看到A,B属于上面的种子点,C,D,E属于下面中部的种子点)
3、接下来,我们要移动种子点到属于他的“点群”的中心。(见图上的第三步)
4、然后重复第2)和第3)步,直到,种子点没有移动(我们可以看到图中的第四步上面的种子点聚合了A,B,C,下面的种子点聚合了D,E)。
如果看了上面的介绍你还是不太清楚,可以参考下这篇文章,讲解的十分通俗易懂:
https://blog.csdn.net/huangfei711/article/details/78480078
那么在pg中该怎么使用kmeans算法呢?
PostgreSQL有一个k-means插件,可以用来实现kmean数据聚集统计,用在窗口函数中。
https://github.com/umitanuki/kmeans-postgresql/blob/master/doc/kmeans.md
用法举例:
SELECT kmeans(ARRAY[x, y, z], 10) OVER (), * FROM samples;
SELECT kmeans(ARRAY[x, y], 2, ARRAY[0.5, 0.5, 1.0, 1.0]) OVER (), * FROM samples;
SELECT kmeans(ARRAY[x, y, z], 2, ARRAY[ARRAY[0.5, 0.5], ARRAY[1.0, 1.0]]) OVER (PARTITION BY group_key), * FROM samples;
第一个参数是需要参与聚类分析的数组,第二个参数是最终分成几类(输出结果时类是从0开始的,如分2类的话,输出是0和1)。
第三个参数是种子参数,可以是1维或2维数组,如果是1维数组,必须是第一个参数的元素个数乘以第二个元素的值。(可以认为是给每一个类分配一个种子)。
例子:
bill=# create extension kmeans ;
CREATE EXTENSION
bill=# \dx+ kmeans
Objects in extension "kmeans"
Object description
----------------------------------------------------------------
function kmeans(double precision[],integer)
function kmeans(double precision[],integer,double precision[])
(2 rows)
bill=# create table t1(c1 int,c2 int,c3 int,c4 int);
CREATE TABLE
bill=# insert into t1 select 100*random(),1000*random(),100*random(),10000*random() from generate_series(1,100000);
INSERT 0 100000
如果是一维数组,必须是第一个参数数组的长度乘以类别个数2:
bill=# select kmeans(array[c1,c2,c3],2,array[1,2,3,4,5,6]) over() , * from t1 limit 10;
kmeans | c1 | c2 | c3 | c4
--------+----+-----+----+------
1 | 91 | 772 | 8 | 8621
1 | 27 | 635 | 60 | 2038
1 | 80 | 892 | 71 | 1388
0 | 24 | 215 | 55 | 197
1 | 81 | 715 | 72 | 7863
0 | 7 | 432 | 55 | 8947
1 | 25 | 645 | 84 | 1226
0 | 70 | 19 | 53 | 1122
0 | 41 | 141 | 87 | 9622
1 | 15 | 513 | 58 | 8081
(10 rows)
否则会报错:
bill=# select kmeans(array[c1,c2,c3],2,array[1,2,3,4]) over() ,* from t1;
psql: ERROR: initial mean vector must be 2d without NULL element
也可以写成这样:
bill=# select kmeans(array[c1,c2,c3],3,array[[1,1,1],[2,2,2],[3,3,3]]) over() ,* from t1 limit 10;
kmeans | c1 | c2 | c3 | c4
--------+----+-----+----+------
2 | 91 | 772 | 8 | 8621
0 | 27 | 635 | 60 | 2038
2 | 80 | 892 | 71 | 1388
1 | 24 | 215 | 55 | 197
2 | 81 | 715 | 72 | 7863
0 | 7 | 432 | 55 | 8947
0 | 25 | 645 | 84 | 1226
1 | 70 | 19 | 53 | 1122
1 | 41 | 141 | 87 | 9622
0 | 15 | 513 | 58 | 8081
(10 rows)
作者:foucus、