Maven插件开发(三)——Java中Processor使用与maven-compiler-plugin的结合使用
在前面几篇博客中我们讲解了简单的自定义插件开发工作,今天我们讲解一下扩展maven-compiler-plugin的processor功能。
一、maven-compiler-plugin我们知道Maven只是个项目管理工具,如果要编译Java代码是不行的,而maven-compiler-plugin这个是Apache官方提供的Maven编译Java源码的功能插件,我们在项目中经常使用到,也就是我们平时使用的mvn compile指令就是通过该插件实现的。maven-compiler-plugin插件的参数很多,我们一般可以通过配置不同参数实现不同的功能,比如设置编译源和目标中Java编译器的目标,通过设置Java源代码兼容的JVM版本,标明Java源代码开发过程中使用的Java版本,通过设置编译后的类库拟运行的JVM版本,给出编译后的类库将要运行的Java环境。
org.apache.maven.plugins
maven-compiler-plugin
${maven.compiler.plugin.version}
1.8
1.8
UTF-8
true
true
true
true
<!-- 使用指定的javac命令,例如:${JAVA_HOME}/bin/javac -->
1.3
128m
512m
-verbose -bootclasspath ${java.home}\lib\rt.jar
以上的参数就是我们平时常常使用到的,更多参数可以查看文档。
我们可以知道maven-compiler-plugin插件中提供了一个annotationProcessors的参数,这个参数提供的就是processor的功能。因此我们可以通过maven-compiler-plugin预留的processor功能做一些扩展功能,再讲解processor功能前,我们先讲解一下注解与注解器,为啥先讲这个,这个与processor有啥关系?待你读完便会理解。
二、注解与注解处理器 1、注解我们知道注解,也被称为元数据(所谓的元数据,就是描述数据的数据)。
所以注解的主要作用就是给指定代码一些描述信息。这些指定代码可以是一个类、一个方法或者是一个属性。
Java注解是在Java SE5中被引入进来的,在Java中内置了三种注解以及四种元注解。
内置注解| 内置注解 | 说明 |
|---|---|
| @Override | 表示当前的方法定义将覆盖超类中的方法,如果方法名或者参数有误,那么编译器就会报错提示 |
| @Deprecated | 用于注解已经过时的代码(方法或者某属性),使用了该注解的方法或者属性编译器会发出警告 |
| @SuppressWarnings | 关闭不当的编译器警告信息。如果一个方法调用的方法已过时,或使一个不安全的类型转换,编译器可能会产生一个警告。您可以通过包含使用@SuppressWarnings注解代码的方法标注抑制这些警告 |
在Java中提供了四种元注解,这四个注解的主要作用就是用于注解其他注解。
| 元注解 | 说明 |
|---|---|
| @Target | 指定注解的作用域 |
| @Retention | 指定在那个级别保存该注解信息 |
| @Documented | 指定这个注解的元素可以被javadoc此类的工具文档化 |
| @Inherite | 指定该注解类型被自动继承。如果用户在当前类中查询这个元注解类型并且当前类的声明中不包含这个元注解类型,那么也将自动查询当前类的父类是否存在Inherited元注解,这个动作将被重复执行知道这个标注类型被找到,或者是查询到顶层的父类 |
这里只是大致介绍了一下Java中的注解,关于更多细节和用法可以参考Annotation。
2、注解处理器注解处理器显而易见就是处理我们定义的注解用处的。Java中常见的两种注解处理器:
通过反射实现的运行时注解处理器 通过apt工具实现的编译时注解处理器第一种通过反射实现运行时注解,这个比较常见。也就是AnnotatedElement接口,而AnnotatedElement可以通过反射获取,比如Annotation[] getAnnotations()返回元素上所有的注解。另一种就是apt(Annotation Processing Tool)工具实现,它是javac的一个工具,中文意思为编译时注解处理器。APT可以用来在编译时扫描和处理注解。通过APT可以获取到注解和被注解对象的相关信息,在拿到这些信息后我们可以根据需求来自动的生成一些代码,省去了手动编写。
注意:获取注解及生成代码都是在代码编译时候完成的,相比反射在运行时处理注解大大提高了程序性能。APT的核心是AbstractProcessor类。
注意:在Java8中已经移除APT相关工具,而Jjava7中还保留着。具体说明
也就是说Java8版本后现在apt工具是通过另一种方式插入式注解API来实现的。而插入式注解处理API(JSR269)是用于处理注解(元数据,JSR175)的一套API。其API位于javax.annotation.processing和javax.lang.model包下。插入式注解处理API可以让你在编译期访问注解元数据,处理和自定义你的编译输出,像反射一样访问类、字段、方法和注解等元素,创建新的源文件等等。
写过Android的同学应该了解ButterKnife这个插件,通过它我们不用写重复findView这些逻辑,这里实现的原理就是通过processor来实现的,在编译期间将我们定义的注解替换为具体的代码。
三、实战说了那么多,我们还是直接实战吧。比如这里我们模仿querydsl这种来生成带Q的实体类对象等,只要entity带有@CustomEntity注解的类,我们就重新生成一个带有Q命名前缀的entity类。
我们新建一个工程annotation-maven-plugin,然后新建一个注解类CustomEntity,如下:
package net.anumbrella;
import java.lang.annotation.ElementType;
import java.lang.annotation.Retention;
import java.lang.annotation.RetentionPolicy;
import java.lang.annotation.Target;
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.SOURCE)
public @interface CustomEntity {
}
然后我们创建一个CustomProcessor类,该类继承AbstractProcessor,这里的AbstractProcessor是一个抽象类,该类实现了接口Processor。
抽象类AbstractProcessor以及接口Processor都是位于包javax.annotation.processing中。该接口中定义的所有类、接口都是与实现注解处理器相关的。
package net.anumbrella;
import javax.annotation.processing.*;
import javax.lang.model.SourceVersion;
import javax.lang.model.element.Element;
import javax.lang.model.element.TypeElement;
import java.io.File;
import java.io.IOException;
import java.util.HashSet;
import java.util.Set;
@SupportedAnnotationTypes("net.anumbrella.CustomEntity")
@SupportedSourceVersion(SourceVersion.RELEASE_8)
public class CustomProcessor extends AbstractProcessor {
// Processor初始化回调
@Override
public synchronized void init(ProcessingEnvironment processingEnv) {
super.init(processingEnv);
System.out.println("CustomProcessor init");
}
// processor处理过程的回调
@Override
public boolean process(Set annotations, RoundEnvironment roundEnv) {
System.out.println("process");
for (Element element : roundEnv.getElementsAnnotatedWith(CustomEntity.class)) {
if (!(element instanceof TypeElement)) {
continue;
}
File file = new File("/Users/anumbrella/Desktop/Test2.java");
try {
file.createNewFile();
} catch (IOException e) {
e.printStackTrace();
}
}
return false;
}
@Override
public Set getSupportedAnnotationTypes() {
// 在此处声明该processor支持的注解类型
// 和注解@SupportedAnnotationTypes功能相同
Set set = new HashSet();
set.add(CustomEntity.class.getCanonicalName());
return set;
}
@Override
public SourceVersion getSupportedSourceVersion() {
// 和注解@SupportedSourceVersion功能相同
return SourceVersion.latestSupported();
}
}
上面的方法都有具体注释,一般情况我们覆写process就可以实现需要的需求了。init方法中的主要是Processor初始化回调,在初始化方法中提供了ProcessingEnvironment接口,该接口表示一个处理环境。它提供了许多接口用于与编译器、源文件和类文件的交互。有了它,你就可以发送编译信息(提示、警告甚至是错误等等),创建新的源文件或类文件。它的接口声明如下:
public interface ProcessingEnvironment {
Map getOptions();
/**
* 返回消息发送器,用于发送消息
*/
Messager getMessager();
/**
* 返回文件访问器,用于创建源文件、类文件或者其他文件
*/
Filer getFiler();
Elements getElementUtils();
Types getTypeUtils();
/**
* 返回当前的源代码版本
*/
SourceVersion getSourceVersion();
/**
* 返回当前的语言环境
*/
Locale getLocale();
}
上面代码主要实现如果当前类包含@CustomEntity注解,然后就会通过在指定路径生成一个带前缀Q的对接名称文件。如果我们使用Maven编译会报错如果没指定具体processor。所以需要添加如下参数:
org.apache.maven.plugins
maven-compiler-plugin
8
8
-proc:none
让Java编译器添加一个不进行注解处理的参数。
同时,我们要在我们的源文件路径下的META-INF.services文件夹下,创建一个名为javax.annotation.processing.Processor的文本文件,其中写入我们的注解处理器的全称:
net.anumbrella.CustomProcessor
如果觉得这样很麻烦,可以使用Google开源的库auto-service。在CustomProcessor上面添加@AutoService(CustomEntity.class)即可。
然后我们新建一个Test.java类,通过引用注解来实现功能,如下:
import net.anumbrella.CustomEntity;
@CustomEntity
public class Test {
public static void main(String[] args) {
System.out.println("Test");
}
}
然后我们通过命令:
sudo javac -cp annotation-maven-plugin-1.0-SNAPSHOT.jar -processor net.anumbrella.CustomProcessor Test.java

最终我们生成了一个带Q的Test类。
这种方式我们根本没使用到maven-compiler-plugin插件中提供了一个annotationProcessors的参数。如果我们在具体项目中要使用,那么也很简单引入我们的项目,如下:
net.anumbrella
annotation-maven-plugin
1.0-SNAPSHOT
然后配置maven-compiler-plugin插件中的annotationProcessors参数,如下:
org.apache.maven.plugins
maven-compiler-plugin
8
8
net.anumbrella.CustomProcessor
然后我们在项目里新建一个Person类和上面Test类相同,接着执行mvn clean compile即可。
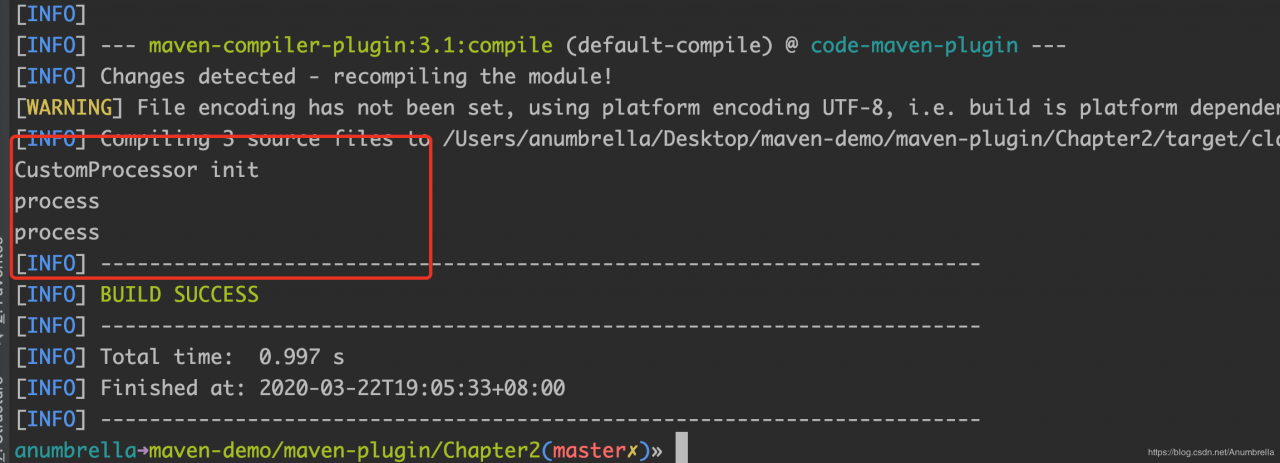
通过日志打印我们可以知道执行了我们自定义的Processor,然后在具体目录下可以发现我们的文件生成成功。

在实际应用中输出地址更改为项目具体输出即可。关于代码生成,可以使用javaopet,非常强大,ButterKnife就是使用的这个库。
代码实例:Chapter3
参考 https://www.baeldung.com/java-annotation-processing-builder 插入式注解处理API(JSR269)介绍作者:Anumbrella