[Machine Learning] 交叉熵损失函数 v.s. 平方损失函数(CrossEntropy Loss v.s. Square Loss)
我们会发现,在机器学习实战中,做分类问题的时候经常会使用一种损失函数(Loss Function)——交叉熵损失函数(CrossEntropy Loss)。但是,为什么在做分类问题时要用交叉熵损失函数而不用我们经常使用的平方损失函数呢?
这时候就应该想一下,损失函数需要做什么?怎样的损失函数才是最合适的?
一般而言,我们都希望损失函数能够做到,当我们预测的值跟目标值越远时,在更新参数的时候,应该减去一个更大的值,做到更快速的下降,并且不容易遇到陷入局部最优、鞍点以及平坦区域等问题。具体可看《[Machine Learning] 欠拟合 & 过拟合(Underfitting & Overfitting)》
那么,现在我们就来比较在分类问题中的两种代价函数。
CrossEntropy Loss v.s. Square Loss针对二分类来说,其中:
yi=σ(zi)=sigmoid(zi)=11+e−ziy_i = \sigma(z_i) = sigmoid(z_i) = \frac{1}{1+e^{-z_i}}yi=σ(zi)=sigmoid(zi)=1+e−zi1
其中,zi=ωxi+bz_i = \omega x_i+bzi=ωxi+b。
Sigmoid函数求导:
 Square Loss:
Square Loss:
J=12m∑i=1n(yi−y^i)2J = \frac{1}{2m}\sum_{i=1}^{n}(y_i - \hat{y}_i)^2J=2m1i=1∑n(yi−y^i)2
其中,y^i\hat{y}_iy^i代表实际值,yiy_iyi代表预测值。
为了方便我们只取一个样本,那么损失为:
J=(yi−y^i)22J = \frac{(y_i-\hat{y}_i)^2}{2}J=2(yi−y^i)2
那么ω\omegaω,bbb的梯度为:
∂J∂ω=(yi−y^i)⋅yi′=(yi−y^i)⋅σ′(ωxi+b)=(yi−y^i)⋅σ′(z)⋅x\frac{\partial J}{\partial \omega} = (y_i - \hat{y}_i)\cdot y_i' = (y_i - \hat{y}_i)\cdot \sigma'(\omega x_i+b) = (y_i - \hat{y}_i)\cdot \sigma'(z)\cdot x∂ω∂J=(yi−y^i)⋅yi′=(yi−y^i)⋅σ′(ωxi+b)=(yi−y^i)⋅σ′(z)⋅x
∂J∂b=(yi−y^i)⋅yi′=(yi−y^i)⋅σ′(ωxi+b)=(yi−y^i)⋅σ′(z)\frac{\partial J}{\partial b} = (y_i - \hat{y}_i)\cdot y_i' = (y_i - \hat{y}_i)\cdot \sigma'(\omega x_i+b) = (y_i - \hat{y}_i)\cdot \sigma'(z)∂b∂J=(yi−y^i)⋅yi′=(yi−y^i)⋅σ′(ωxi+b)=(yi−y^i)⋅σ′(z)
CrossEntropy Loss:J=1m∑i=1n−[yiln(y^i)+(1−yi)ln(1−y^i)]J = \frac{1}{m}\sum_{i=1}^{n}-[y_iln(\hat{y}_i) + (1-y_i)ln(1-\hat{y}_i)]J=m1i=1∑n−[yiln(y^i)+(1−yi)ln(1−y^i)]
其中,y^i\hat{y}_iy^i代表实际值,yiy_iyi代表预测值。
为了方便我们只取一个样本,那么损失为:
J=−yln(y^)−(1−y)ln(1−y^)J = -yln(\hat{y}) - (1-y)ln(1-\hat{y})J=−yln(y^)−(1−y)ln(1−y^)
计算ω\omegaω,bbb的梯度:
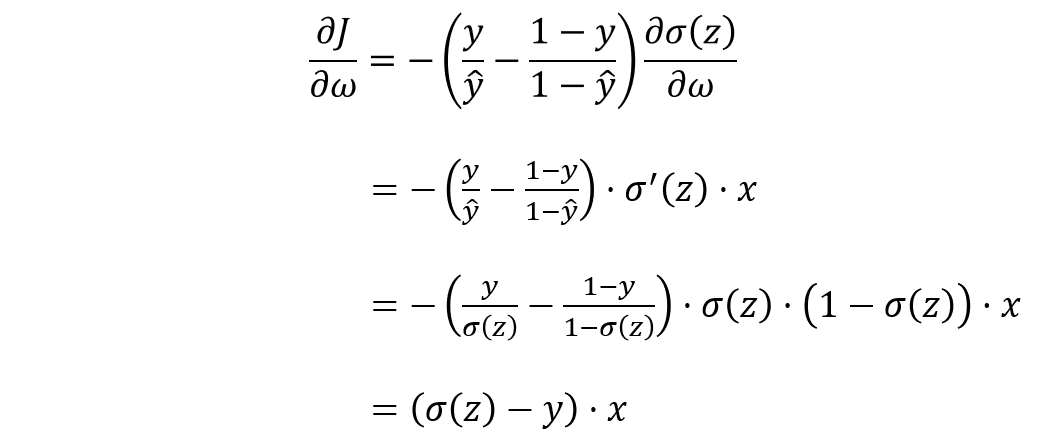
∂J∂b=(σ(z)−y))\frac{\partial J}{\partial b} = (\sigma(z) - y))∂b∂J=(σ(z)−y))
分析和结论
如图为sigmoid函数以及sigmoid函数的导数的图像。
由此可看出,
Square Loss在更新ω\omegaω、bbb的时候,ω\omegaω、bbb的梯度与激活函数的导数是成正比的,激活函数导数越大,ω\omegaω、bbb调整就越快,训练收敛就越快,但是Sigmoid函数在值非常高的时候,梯度是很小的,比较平缓。
CrossEntropy Loss在更新ω\omegaω、bbb的时候,ω\omegaω、bbb的梯度与激活函数没有关系,而是与(σ(z)−y^)(\sigma(z)-\hat{y})(σ(z)−y^)成正比,其中(σ(z)−y^)(\sigma(z)-\hat{y})(σ(z)−y^)表示预测值与实际值的差距,如果差距越大,那么ω\omegaω、bbb调整就越快,收敛就越快。
因此,在作分类问题(例如Logistics Regression)的时候,我们会比较常使用交叉熵损失函数作为损失函数。
作者:Oh_MyBug