Pandas缺失值填充df.fillna()的实现
df.fillna主要用来对缺失值进行填充,可以选择填充具体的数字,或者选择临近填充。
官方文档
DataFrame.fillna(self, value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
df.fillna(x)可以将缺失值填充为指定的值
import pandas as pd
# 原数据
df = pd.DataFrame({'A':['a1','a1','a2','a2'],
'B':['b1','b2',None,'b2'],
'C':[1,2,3,4],
'D':[5,6,None,8],
'E':[5,None,7,8]
})
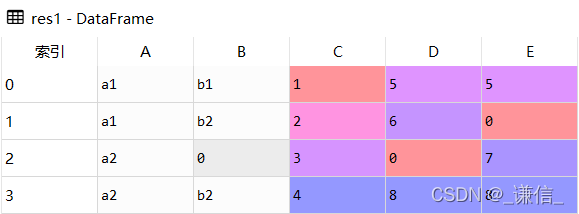
# 将缺失值填充为0
res1 = df.fillna(0)
结果展示
df

res1
# 常用的方法还有以下几个:
# 填充为0
df.fillna(0)
# 填充为指定字符
df.fillna('missing')
df.fillna('暂无')
df.fillna('待补充')
# 指定字段填充
df.E.fillna('暂无')
# 指定字段填充
df.E.fillna(0, inplace = True)
# 只替换第一个
df.fillna(0, limit = 1)
# 将不同列的缺失值替换为不同的值
values = {'A':0,'B':1,'C':2,'D':3}
df.fillna(value = values)
需要注意的是,如果想让填充马上生效,需要重新为df赋值或者传入参数inplace = True
有时候我们不能填入固定值,而是按照一定的方法填充,df.fillna()提供了一个method参数,可以指定以下几个方法:
pad/ffill:向前填充,使用前一个有效值填充,df.fillna(method=’ffill’)可以简写为df.ffill()
bfill/backfill:向后填充,使用后一个有效值填充,df.fillna(method=’bfill’)可以简写为df.bfill()
import pandas as pd
# 原数据
df = pd.DataFrame({'A':['a1','a1','a2','a2'],
'B':['b1','b2',None,'b2'],
'C':[1,2,3,4],
'D':[5,6,None,8],
'E':[5,None,7,8]
})
# 取后一个有效值填充
res1 = df.fillna(method = 'bfill')
# 取前一个有效值填充
res2 = df.fillna(method = 'ffill')
结果展示
df

res1

res2

除了取前后值,还可以取经过计算得到的值,比如常用的平均值填充法:
# 填充列的平均值
df.fillna(df.mean())
# 对指定列填充平均值
df.fillna(df.mean()['B':'D'])
# 另一种填充列的平均值的方法
df.where(pd.notna(df),df.mean(),axis = 'columns')
缺失值的填充的另一思路是使用替换方法df.replace():
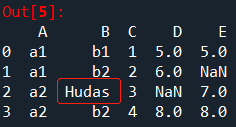
# 将指定列的空值替换成指定值
import pandas as pd
import numpy as np
# 原数据
df = pd.DataFrame({'A':['a1','a1','a2','a2'],
'B':['b1','b2',None,'b2'],
'C':[1,2,3,4],
'D':[5,6,None,8],
'E':[5,None,7,8]
})
df.replace({'B':{np.nan:'Hudas'}})
结果展示

到此这篇关于Pandas缺失值填充 df.fillna()的实现的文章就介绍到这了,更多相关Pandas缺失值填充 df.fillna() 内容请搜索软件开发网以前的文章或继续浏览下面的相关文章希望大家以后多多支持软件开发网!
相关文章
Wilma
2020-04-12
Madge
2020-11-02
Maha
2023-02-26
Fredrica
2023-02-26
Isoke
2023-04-02
Pandora
2023-04-10
Pandora
2023-04-12
Olivia
2023-04-30
Dulcea
2023-04-30
Thadea
2023-05-12
Ula
2023-05-12
Jacuqeline
2023-05-12
Karli
2023-05-12
Bertha
2023-07-20
Heather
2023-07-20
Aggie
2023-07-20
Bliss
2023-07-21
Lillian
2023-07-21