百度paddle课程学习小记(上)
百度paddle课程学习小记(上)百度paddle课程学习小记(上)Day-1:python基础练习Day-2:《青春有你2》选手信息爬取遇到的问题Day-3《青春有你2》选手数据分析遇到的问题未完待续
百度paddle课程学习小记(上)
第一次听说AI Studio上的课程是在去年冬天班主任老师为我们推荐的。然而当时考(lan)试(ai)太(fa)多(zuo) ,自己又是小白担心没有基础无法完成,所有无心去搞。这学期学院王老师又大力推鉴,也是想充实一下在家的生活吧,就报名参加了百度深度学习7日打卡第六期:Python小白逆袭大神的活动。
事实证明,我来对了。
Day-1:python基础练习第一天的作业主要是关于python的基础操作,比较容易。
作业一:输出 9*9 乘法口诀表(注意格式)
def table():
#在这里写下您的乘法口诀表代码吧!
for i in range(1, 10):
for j in range(1, i+1):
k = i*j
print(j, '*', i, '=', k, end = '\t')
#print('%d * %d = %d '%(j,i, i*j),end='\t')
print()
if __name__ == '__main__':
table()
作业二:查找特定名称文件,遍历”Day1-homework”目录下文件,找到文件名包含“2020”的文件,将文件名保存到数组result中;
#导入OS模块
import os
#待搜索的目录路径
path = "Day1-homework"
#待搜索的名称
filename = "2020"
#定义保存结果的数组
result = []
def findfiles():
#在这里写下您的查找文件代码吧!
i = 0
for root, dirs, files in os.walk(path):
# root 表示当前正在访问的文件夹路径
# dirs 表示该文件夹下的子目录名list
# files 表示该文件夹下的文件list
# 遍历文件
for f in files:
if filename in f:
i += 1
#连接路径
f=os.path.join(root, f)
print(i,",'" ,f,"'", end = '\n')
result.append(f)
if __name__ == '__main__':
findfiles()
ps:思路都比较清晰,但是好久没有用python真的感觉生疏了…在学校写大作业用C++比较多,遇到for/if总想着加括号…还是短练啊。
Day-2:《青春有你2》选手信息爬取感觉第二天作业难度陡然上升,利用爬虫爬取小姐姐的图片。虽然班主任在视频中具体讲解了爬取办法,总结一下分为以下几步:
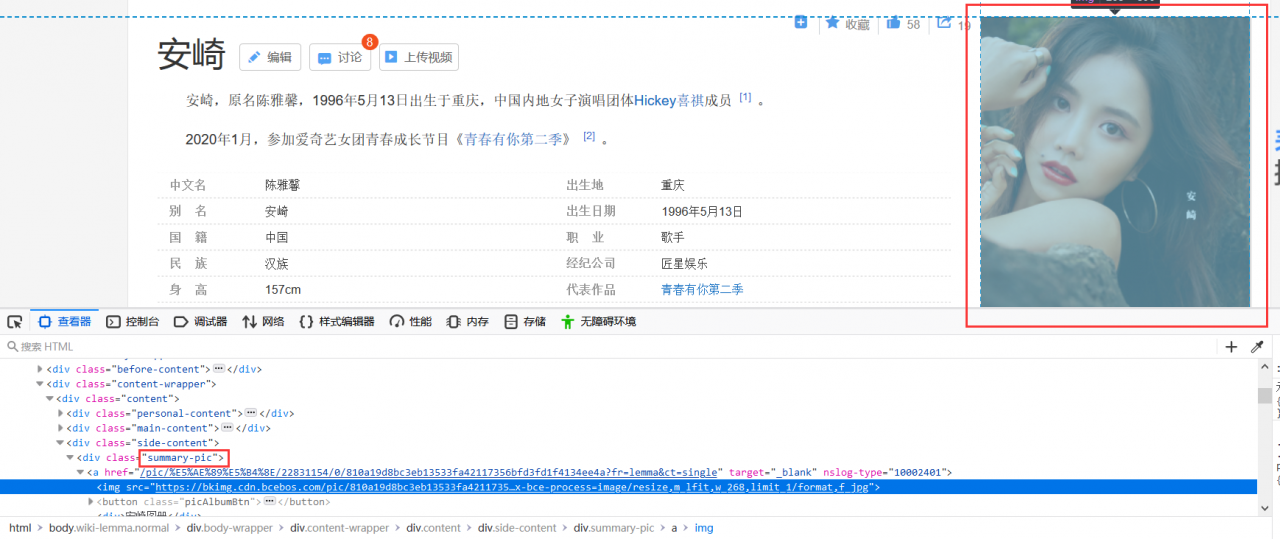
了解网页:利用开发者工具查看需要的标签类别和名字。 利用requests库爬取网页信息 利用BeautifulSoup解析网页 组织数据在对每位选手爬取图片的部分,老师给的参考代码如下:
#获取解析界面,拼接第一层链接:选手百度百科词条中的summary—pic
response=requests.get(link,headers=headers)
bs=BeautifulSoup(response.text,'lxml')
pic_list_url=bs.select('.summary-pic a')[0].get('href')
pic_list_url='https://baike.baidu.com'+pic_list_url
 原创文章 1获赞 2访问量 22
关注
私信
展开阅读全文
原创文章 1获赞 2访问量 22
关注
私信
展开阅读全文
作者:无限之阿尔法
相关文章
Iris
2021-08-03
Canace
2020-10-17
Kande
2023-05-13
Ula
2023-05-13
Jacinda
2023-05-13
Winona
2023-05-13
Fawn
2023-05-13
Echo
2023-05-13
Maha
2023-05-13
Kande
2023-05-15
Viridis
2023-05-17
Pandora
2023-07-07
Tallulah
2023-07-17
Janna
2023-07-20
Ophelia
2023-07-20
Natalia
2023-07-20
Irma
2023-07-20
Kirima
2023-07-20