爬虫实战(8)-爬取豆瓣网最近要上映的电影
下饭文章,客官里面请,看菜单,先点菜吧
废话不多说了,直接上代码吧:
特别注意本文直接看代码,文中的重要知识点,有注释,本文用到的知识点在我之前的文章中全部都有详细的讲解. 文中部分代码注释,是我在爬虫中写代码的步骤,代码永远不是一次写成,要逐步调试,步步简单输出,这样代码发生错误后,很好修改.很快的能确定错误的地方.#encoding: utf-8
import requests
from lxml import etree
import csv
headers ={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.92 Safari/537.36',
'Referer': 'https://movie.douban.com/'
}
url = 'https://movie.douban.com/cinema/later/xian/'
response = requests.get(url,headers=headers)
text = response.text
#数据解析
html = etree.HTML(text)
#div class="intro"
movies = []
intros = html.xpath("//div[@class = 'intro']")
for intro in intros:
#注意xpath语法返回的永远是一个列表,我们要得到原本的数据,就列表索引取零
names = intro.xpath(".//h3/a/text()")[0]
uls = intro.xpath(".//ul")
for ul in uls:
data = ul.xpath(".//li[1]/text()")[0]
leixing =ul.xpath(".//li[2]/text()")[0]
address = ul.xpath(".//li[3]/text()")[0]
redu = ul.xpath(".//li[4]/span/text()")[0]
# print(names)
# print(data)
# print(leixing)
# print(address)
# print(redu)
movie={
'热度': redu,
'电影名': names,
'电影类型': leixing,
'发行地': address,
'上映日期': data,
}
movies.append(movie)
text1 = movies
header = {
'电影名',
'上映日期',
'电影类型',
'热度',
'发行地',
}
with open('xian_douban.csv','w',encoding='utf-8',newline='')as fp:
writer = csv.DictWriter(fp,header)
# csv.writeheader()
# writer.writerow(['1','2'',3','4'])
writer.writerows(text1)
#小总结:首先你得确定自己要爬取的数据在那个主便签下(即父标签)
#然后先通过xpath语法,选择到父标签,然后,在通过.//的方式一步步选择
#自己要爬取的数据,先选择到主标签是为了循环爬取同样类型标签的数据
最终爬出来的表格,放张图给各位客官看一下.
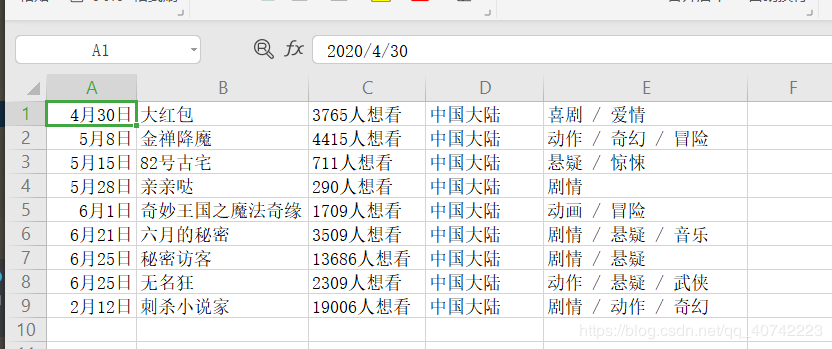
这里遇到一个问题,在这记录一下:表格的输出的顺序暂时不知道怎么去规定,要学习后面的内容才能搞懂,我在这做个记录
最近一段时间都在搞这个爬虫和数据分析,各位客官,有兴趣的点个赞哦!
然后把往期的爬虫文章,这里放个传送门,方便各位客官查看:
爬虫(1)爬虫概述,爬虫抓包工具
爬虫(2)urllib和parse库的介绍和常用函数介绍和使用
爬虫(3)request.Request类的介绍和简单爬虫实战
爬虫(4)ProxyHandler处理器(代理设置)
爬虫(5)一文搞懂cookie原理和使用(客官里面请,下饭文章吃饱再走)
爬虫(6)cookie信息保存到本地和加载
爬虫(7)一文搞懂爬虫的网络请求,requests库的使用
Xpath详解
作者:小白程序员你值得拥有