Python网络爬虫实战_豆瓣电影Top250(1)简单的图片爬取
文章目录前言一、前提准备1、对页面进行分析2、准备框架二、代码实现三、总结
前言
作者:不温卜火
这是本人第一次写博客,如有失误请见谅。
这段时间,由于疫情原因,在家无聊,再加上这学期要学习爬虫这们课程。所以我开始了自学爬虫的“艰苦岁月”。
爬虫,看似简单,实则并不简单。刚开始听别人说只要学会爬虫,什么都能爬取,我是不信的。但是,通过这段时间的学习和了解,我相信别人说的都是真的。当然了,对于目前我这个小菜鸡来说,还很遥远。还需要学习很多东西。话不多说,开始爬取豆瓣电影Top250(这次仅仅爬取电影图片并保存到本地)。
一、前提准备
在爬取所要爬取的东西时,我们要先有所要爬取信息的网址,其次我们要心中有数,要先做好规划,然后才能补全代码,进行爬取。
1、对页面进行分析

①对网页进行解析
鼠标对准我们需要解析的地方,右键点击检查:
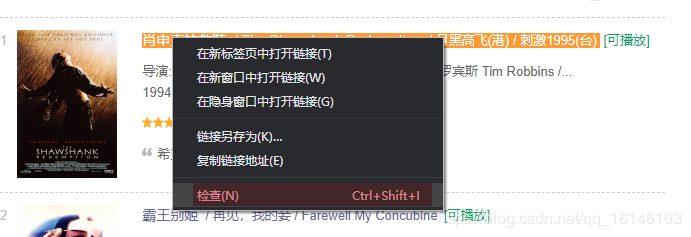
这时我们可以看到网页的基本结构:
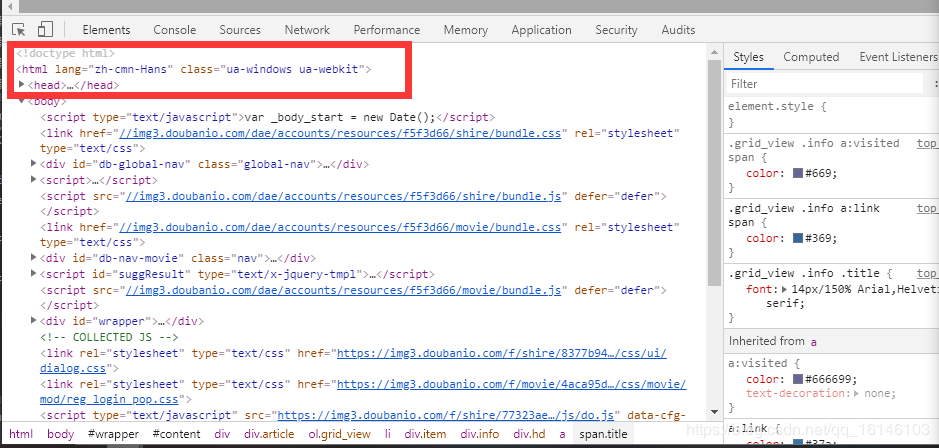
打开以后,我们需要找到此次爬取重点:图片以及电影名称
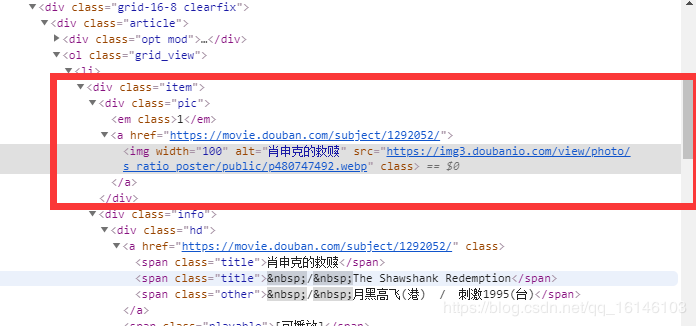
我们可以先把小的标签头缩小,看下所有的电影的标签:
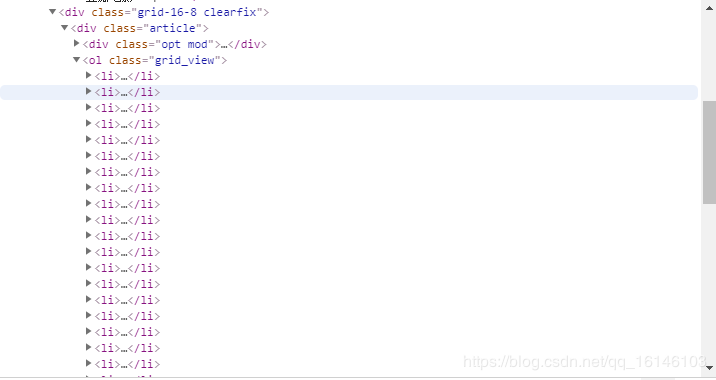
由此,我们可以知道所有的电影信息都在上图所示的标签里
②分步骤进行分析
1)首先我们先读取页面信息
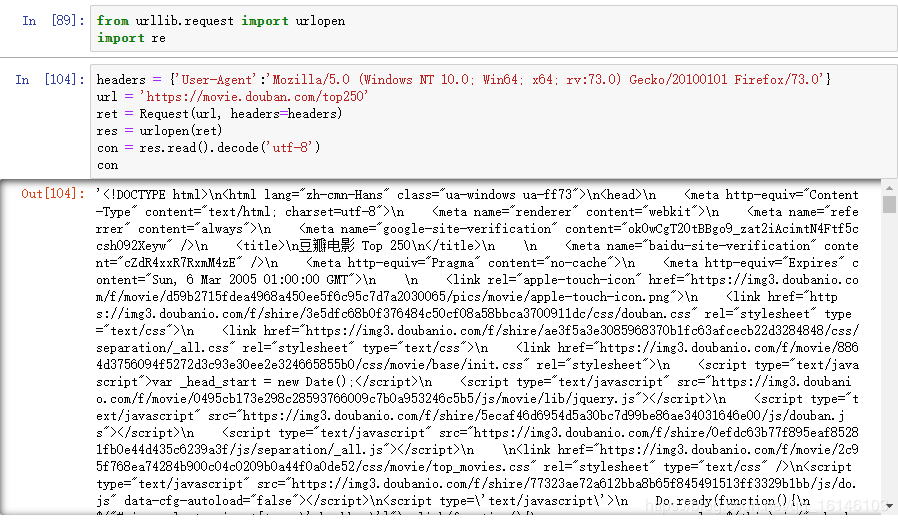
通过添加模块,请求头进行网页解析
2)找到所有的li(即所有电影的存放位置)
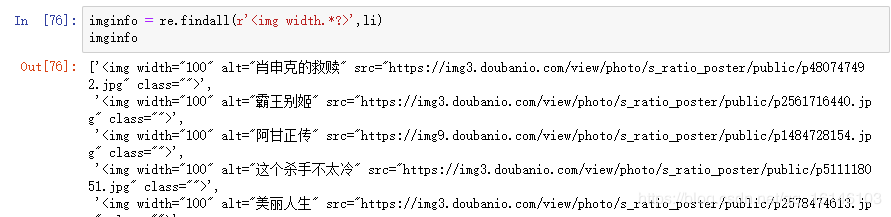
通过findall 查找所有的电影信息,查找用到正则表达式,如果对正则表达式不懂,可以百度了解下。
3)进行字符串解析,对上面的进行切分
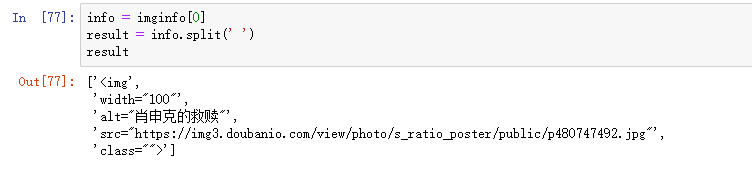
4)切分之后,选取所需要的

5)保存到本地

好了,以上的为保存图片所需要的步骤。
③分析网页一页有多少电影,以及每一页之间的联系
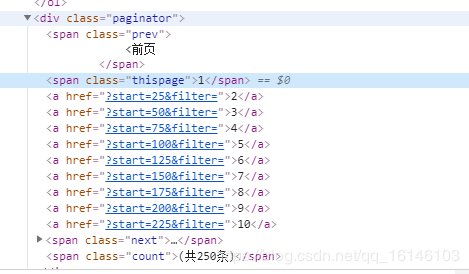
由上面我们可以知道每一页可以自己构造页数。
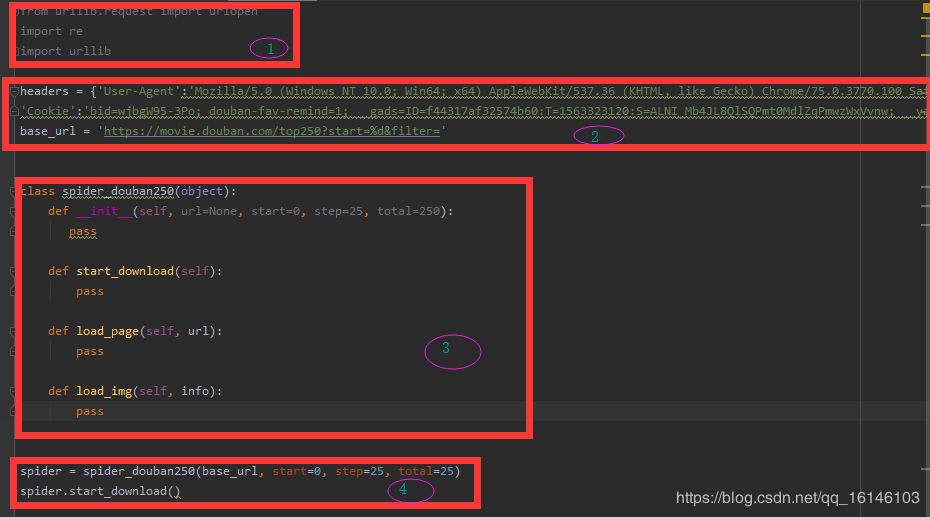
①导入模块
②添加网址与请求头
③定义类,并在类内定义函数
④实现
from urllib.request import urlopen
import re
import urllib
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36',
'Cookie':'bid=wjbgW95-3Po; douban-fav-remind=1; __gads=ID=f44317af32574b60:T=1563323120:S=ALNI_Mb4JL8QlSQPmt0MdlZqPmwzWxVvnw; __yadk_uid=hwbnNUvhSSk1g7uvfCrKmCPDbPTclx9b; ll="108288"; _vwo_uuid_v2=D5473510F988F78E248AD90E6B29E476A|f4279380144650467e3ec3c0f649921e; trc_cookie_storage=taboola%2520global%253Auser-id%3Dff1b4d9b-cc03-4cbd-bd8e-1f56bb076864-tuct427f071; viewed="26437066"; gr_user_id=7281cfee-c4d0-4c28-b233-5fc175fee92a; dbcl2="158217797:78albFFVRw4"; ck=4CNe; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1583798461%2C%22https%3A%2F%2Faccounts.douban.com%2Fpassport%2Flogin%3Fredir%3Dhttps%253A%252F%252Fmovie.douban.com%252Ftop250%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.1583974348.1563323123.1572242065.1583798461.8; __utmb=30149280.0.10.1583798461; __utmc=30149280; __utmz=30149280.1583798461.8.7.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; __utma=223695111.424744929.1563344208.1572242065.1583798461.4; __utmb=223695111.0.10.1583798461; __utmc=223695111; __utmz=223695111.1583798461.4.4.utmcsr=accounts.douban.com|utmccn=(referral)|utmcmd=referral|utmcct=/passport/login; push_noty_num=0; push_doumail_num=0; _pk_id.100001.4cf6=06303e97d36c6c15.1563344208.4.1583798687.1572242284.'}
base_url = 'https://movie.douban.com/top250?start=%d&filter='
# req=urllib.request.Request(url=base_url,headers=headers)
# res = urlopen(req)
# con = res.read().decode('utf-8')
# print(con)
class spider_douban250(object):
def __init__(self,url = None, start = 0, step = 25 , total = 250):
self.durl = url
self.dstart = start
self.dstep =step
self.dtotal = total
def start_download(self):
while self.dstart < self.dtotal:
durl = self.durl%self.dstart
print(durl)
self.load_page(durl)
self.dstart += self.dstep
def load_page(self,url):
req=urllib.request.Request(url=base_url,headers=headers)
req = urlopen(req)
if req.code != 200:
return
con = req.read().decode('utf-8')
listli = re.findall(r'(.*?) ', con,re.S)
if listli:
listli = listli[1:]
else:
return
for li in listli:
imginfo = re.findall(r'![]() ', li)
if imginfo:
imginfo = imginfo[0]
info = [item.split('=')[1].strip()[1:-1] for item in imginfo.split(' ')[2:4]]
self.load_img(info)
def load_img(self,info):
print("callhere load img:", info)
req = urllib.request.Request(url=info[1], headers=headers)
imgreq = urlopen(req)
img_c = imgreq.read()
path = r'D:\\test\\' + info[0] + '.jpg'
print('path:', path)
imgf = open(path, 'wb')
imgf.write(img_c)
imgf.close()
spider = spider_douban250(base_url,start=0,step=25,total=25)
spider.start_download()
', li)
if imginfo:
imginfo = imginfo[0]
info = [item.split('=')[1].strip()[1:-1] for item in imginfo.split(' ')[2:4]]
self.load_img(info)
def load_img(self,info):
print("callhere load img:", info)
req = urllib.request.Request(url=info[1], headers=headers)
imgreq = urlopen(req)
img_c = imgreq.read()
path = r'D:\\test\\' + info[0] + '.jpg'
print('path:', path)
imgf = open(path, 'wb')
imgf.write(img_c)
imgf.close()
spider = spider_douban250(base_url,start=0,step=25,total=25)
spider.start_download()
三、总结
总的来说这个挺简单的,但是如果仔细看的话,还有很多改进的地方,比如说可以使用Requests库、time库、FakeUserAgent库等等。并且此代码仅仅只是爬取电影图片。可拓展性还很强。
第一次写博客,有些没有说明白地方可以留言或者私信我,我会改正并争取早日称为一个合格的博主的。
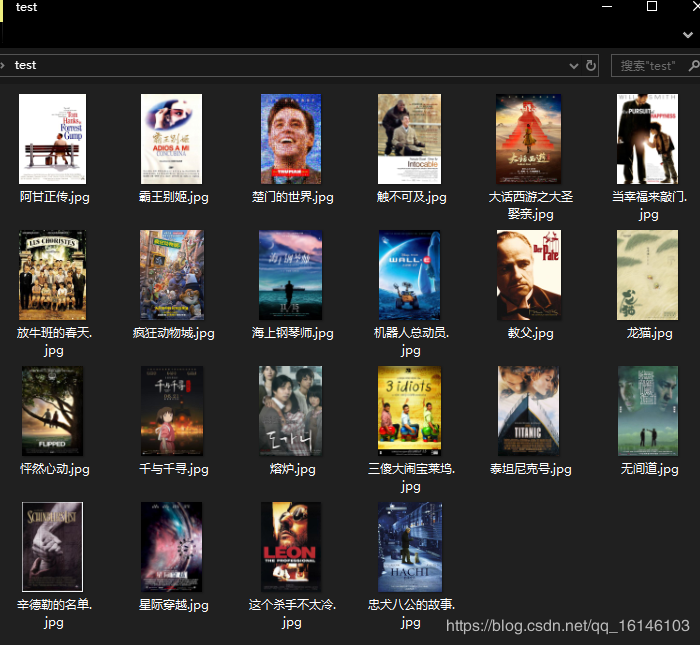
最后放出程序运行成功的截图:
作者:不温卜火