Python爬虫框架Scrapy入门(三)爬虫实战:爬取链家二手房多页数据使用Item Pipeline处理数据
Item对象是一个简单的容器,用于收集抓取到的数据,其提供了类似于字典(dictionary-like)的API,并具有用于声明可用字段的简单语法。
Scrapy的Item Pipeline(项目管道)是用于处理数据的组件。
当Spider将收集到的数据封装为Item后,将会被传递到Item Pipeline(项目管道)组件中等待进一步处理。Scrapy犹如一个爬虫流水线,Item Pipeline是流水线的最后一道工序,但它是可选的,默认关闭,使用时需要将它激活。如果需要,可以定义多个Item Pipeline组件,数据会依次访问每个组件,执行相应的数据处理功能。
Item Pipeline的典型应用:
·清理数据。
·验证数据的有效性。
·查重并丢弃。
·将数据按照自定义的格式存储到文件中。
·将数据保存到数据库中。
编写自己的Item Pipeline组件其实很简单,它只是一个实现了几个简单方法的Python类。当建立一个项目后,这个类就已经自动创建了。打开项目qidian_hot下的pipelines.py,发现自动生成了如下代码:
class LianjiaPipeline(object):
def process_item(self, item, spider):
return item
LianjiaPipeline是自动生成的Item Pipeline类,它无须继承特定的基类,只需要实现某些特定的方法,如process_item()、open_spider()和close_spider()。注意,方法名不可改变。process_item()方法是Item Pipeline类的核心方法,必须要实现,用于处理Spider爬取到的每一条数据(Item)。它有两个参数:item:待处理的Item对象。spider:爬取此数据的Spider对象。方法的返回值是处理后的Item对象,返回的数据会传递给下一级的Item Pipeline(如果有)继续处理。
爬取长沙链家二手房https://cs.lianjia.com/ershoufang/
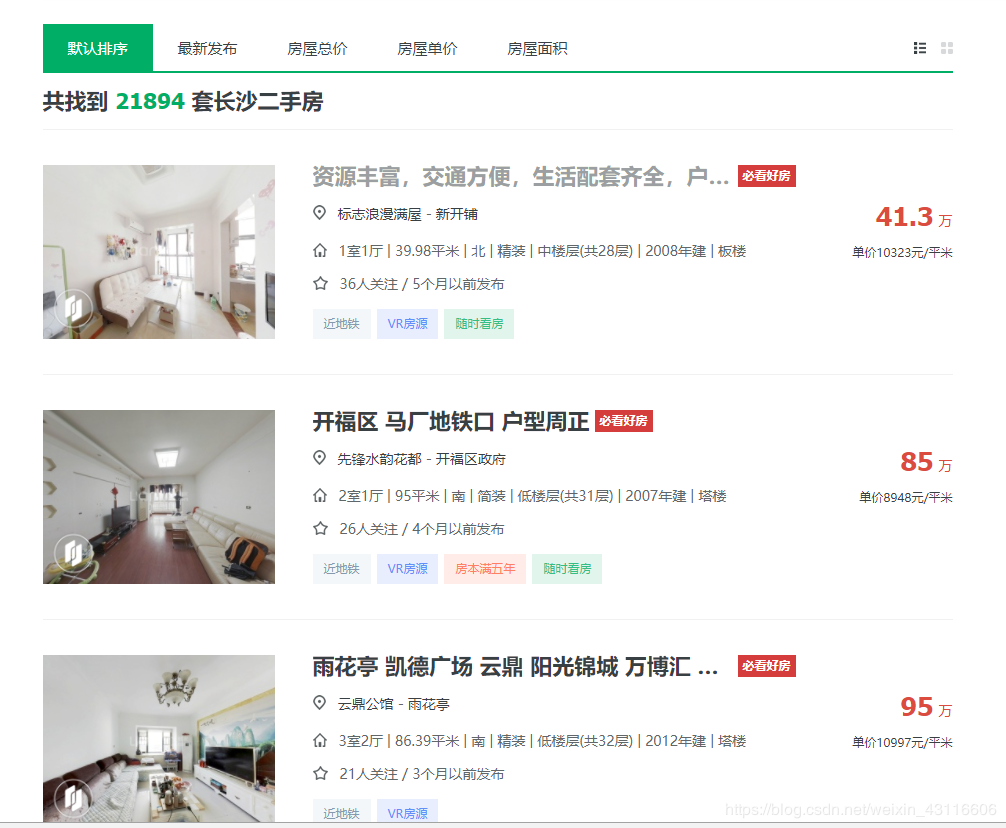
我们爬取二手房的标题、地点、价格以及其他一些房屋基本信息。点击房屋标题进入详情页面,可以查看详细信息。
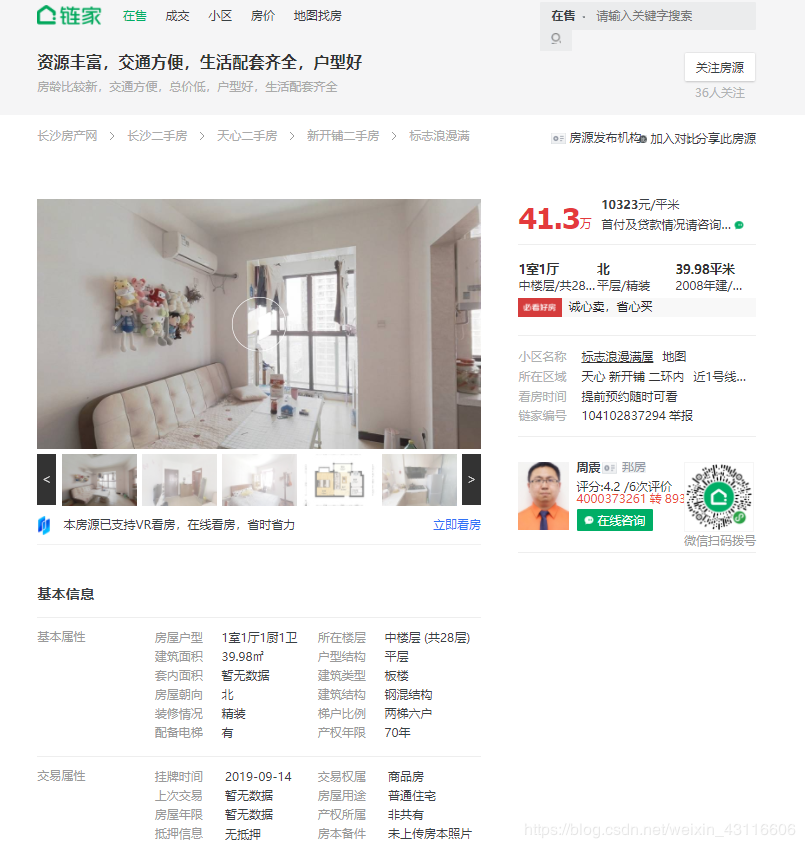
我们还要爬取详情页面房屋配备电梯情况以及产权年限。
爬虫文件是我们用Scrapy爬虫主要要编写的文件,其作用主要有两个:
向网页发起请求 向其他组件发送响应/数据我们可以利用命令行scrapy genspider 爬虫名称 网页域名自动生成爬虫文件,也可以手动创建爬虫文件。
这里在spiders子目录文件夹下手动创建一个名为lianjia_spider.py的爬虫文件
导入需要用到的库文件,命名爬虫名称import scrapy
from scrapy import Request
from lianjia.items import LianjiaItem
class HomespiderSpider(scrapy.Spider):
name = 'home'
重写start_requests()方法
def start_requests(self):
url = 'https://cs.lianjia.com/ershoufang/'
yield Request(url,callback=self.parse)
Request方法的callback参数用于指定爬虫响应的解析方法,默认为parse方法。
解析页面,使用XPath提取数据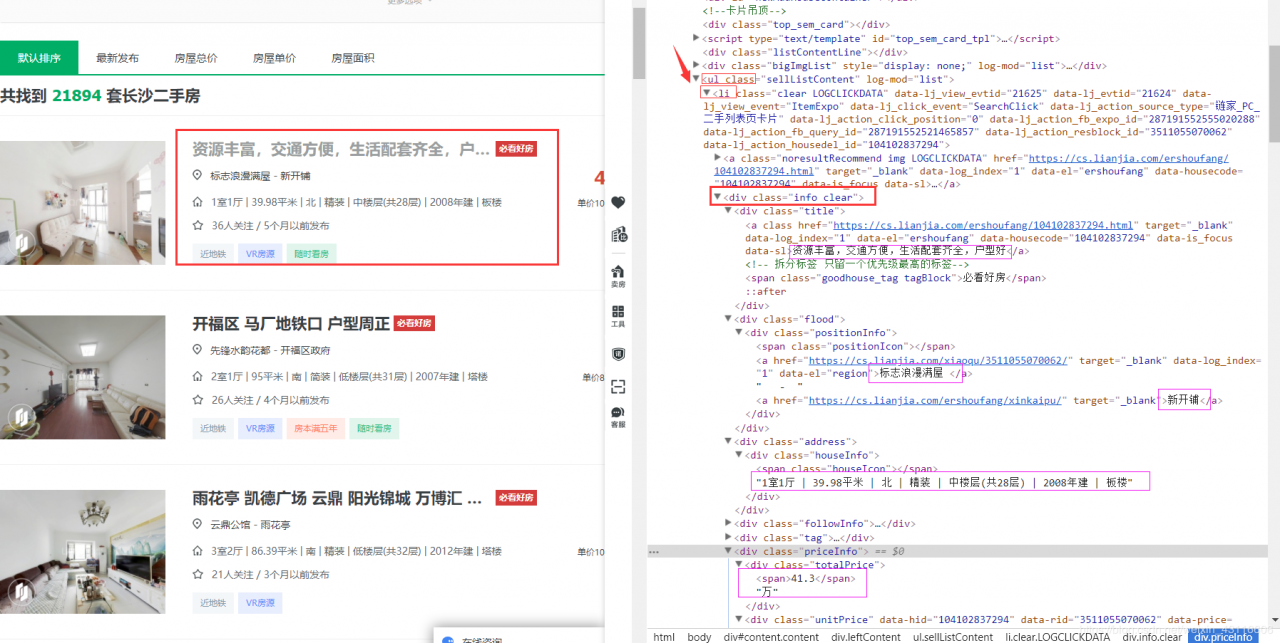
打开开发者工具,可以看到与房屋有关的信息都在 首先提取标题和地点,使用xpath helper这个插件可以很方便编写xpath表达式。 输入xpath表达式,右边会显示提取到的信息,同时网页中对应的信息会高亮,可以验证xpath是否正确。所以我们提取到标题的完整xpath就是: 由于房屋的基本信息包含多项以“ | ”分隔的信息: 提取单价和总价: 至此,基本信息都提取完了,接下来需要保存数据,提取详情页面的数据。 打开items.py 建立item成员变量,也就是我们需要提取的信息 回到爬虫文件,初始化item类,并且将提取的信息保存到item中: 获取详情页面连接后,像爬虫发起爬取请求,注意这里的meta参数和callback参数。 meta用于传递用户参数,我们之前提取的信息保存在item中,这里将item一并传递出去 获取下一页有两种方法, 方法一: 方法二: 至此,爬虫文件已经编写完成了,设置一下代理和robots协议就可以直接运行爬虫导出数据了 打开pipelines.py,默认生成了一个LianjiaPipeline类,其中有一个process方法,我们就是在这个方法中处理数据的。 用到正则表达式导入re库,去掉单价信息中的“单价”二字。 再定义一个csvPipeline类,其中除了process方法,还有open_spider方法和close_spider方法用于打开和关闭爬虫,再次highlight函数名不能随意更改 使用命令行运行爬虫比较麻烦,可以编写一个start.py文件运行爬虫 def parse(self, response):
roomList = response.xpath('//ul/li/div[@class="info clear"]')
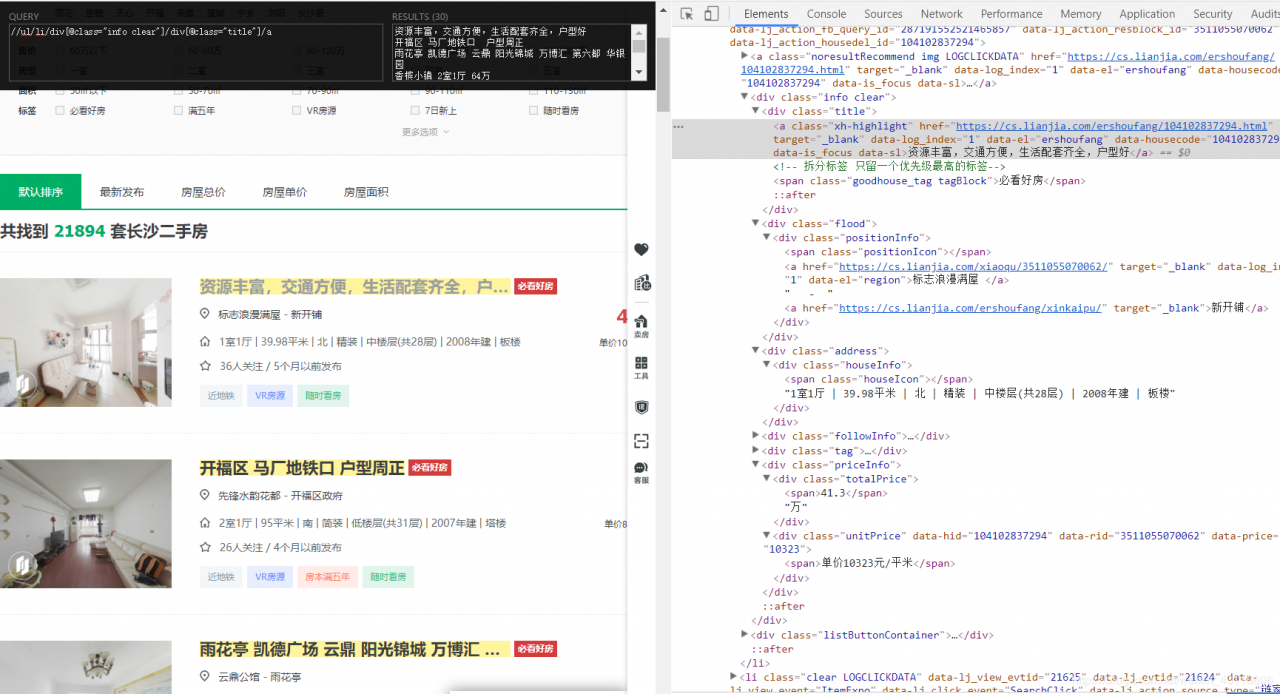
//ul/li/div[@class="info clear"]/div[@class="title"]/a,但是我们之前已经定位到for oneList in roomList:
title = oneList.xpath('./div[@class="title"]/a/text()').extract_first()
place = oneList.xpath('./div[@class="flood"]//a[1]/text()').extract_first()+'- '+oneList.xpath('./div[@class="flood"]//a[2]/text()').extract_first()
houseInfo = oneList.xpath('./div[@class="address"]/div/text()').extract_first()
1室1厅 | 39.98平米 | 北 | 精装 | 中楼层(共28层) | 2008年建 | 板楼。我们需要提取其中的户型、面积、楼层、朝向并分别保存:houseInfoList = houseInfo.split("|")
type = houseInfoList[0]
area = houseInfoList[1]
direction = houseInfoList[2]
floor = houseInfoList[4]
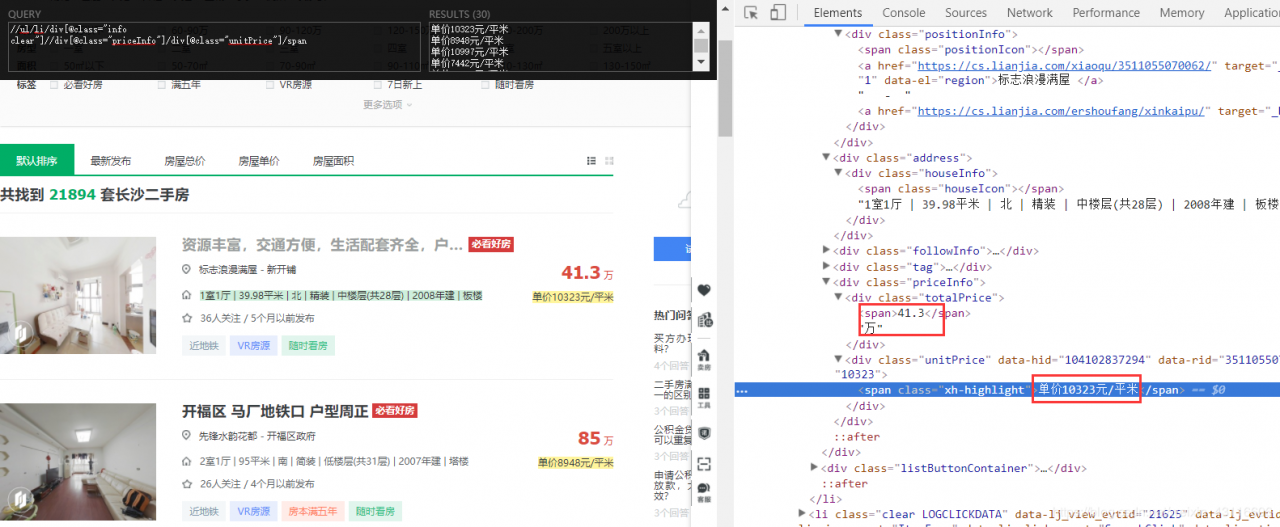
unitPrice = oneList.xpath('./div[@class="priceInfo"]/div[@class="unitPrice"]/span/text()').extract_first()
totalPrice = oneList.xpath('./div[@class="priceInfo"]/div[@class="totalPrice"]/span/text()').extract_first()+oneList.xpath('./div[@class="priceInfo"]/div[@class="totalPrice"]/text()').extract_first()
import scrapy
class LianjiaItem(scrapy.Item):
# -*- coding: utf-8 -*-
title = scrapy.Field()
place = scrapy.Field()
type = scrapy.Field()
area = scrapy.Field()
direction = scrapy.Field()
floor = scrapy.Field()
unitPrice = scrapy.Field()
totalPrice = scrapy.Field()
elevator = scrapy.Field()
propertyYears = scrapy.Field()
item = LianjiaItem()
item["title"] = title
item["place"] = place
item["type"] = type
item["area"] = area
item["direction"] = direction
item["floor"] = floor
item["unitPrice"] = unitPrice
item["totalPrice"] = totalPrice
获取详情页面链接并解析
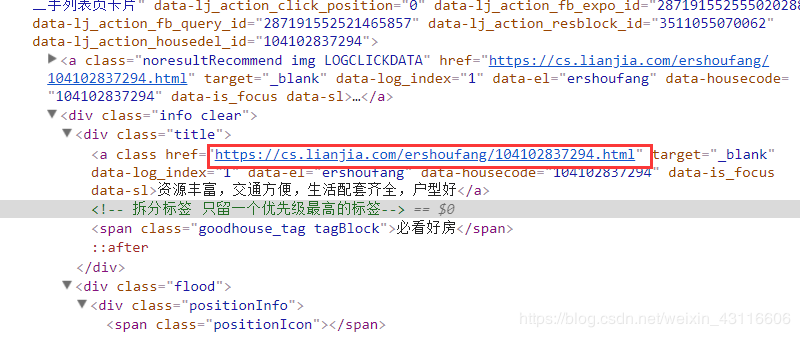
可以看到详情面的链接是我们之前提取的标题所在的a标签的href属性

# 获取详情链接
clearUrl = oneList.xpath('./div[@class="title"]/a/@href').extract_first()
# print(clearUrl)
yield Request(clearUrl,meta={"item":item},callback=self.clearUrlParse)
callback用于指定解析函数,这里不能采用默认的parse,需要编写新的解析函数。# 详情链接解析函数
def clearUrlParse(self,response):
elevator = response.xpath('//div[@class="base"]//ul/li[last()-1]/text()').extract_first()
propertyYears = response.xpath('//div[@class="base"]//ul/li[last()]/text()').extract_first()
item = response.meta["item"]
item["elevator"] = elevator
item["propertyYears"] = propertyYears
yield item
获取下一页链接
https://cs.lianjia.com/ershoufang/pg2/ pg后面的数字代表当前页,修改该数字即可。
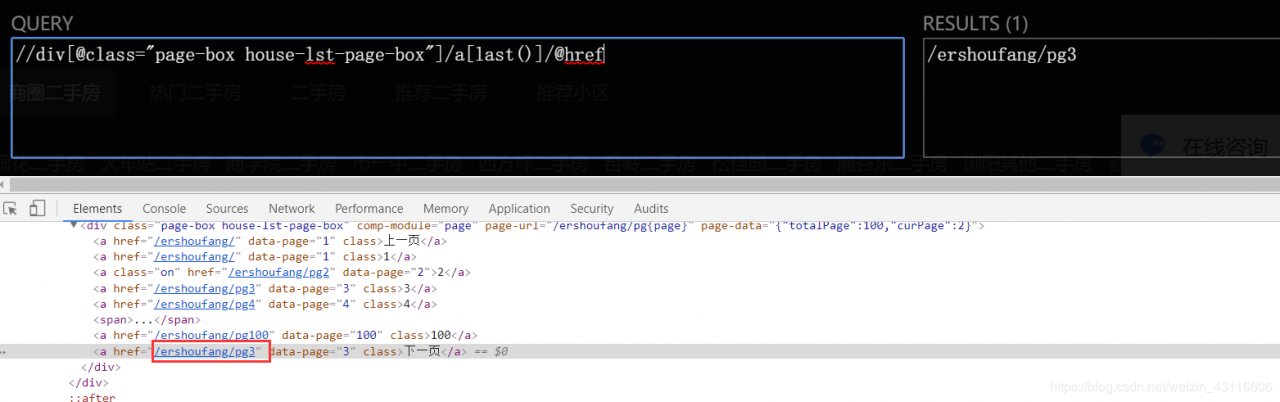
next = response.xpath('//div[@class="page-box house-lst-page-box"]/a[last()]/@href').extract_first()
nextUrl = 'https://cs.lianjia.com'+next
if nextUrl:
yield Request(nextUrl, callback=self.parse)
def __init__(self):
self.currentPage = 1
self.totalPage = 1
self.currentPage += 1
nextUrl = 'https://cs.lianjia.com/ershoufang/pg%d'%self.currentPage
self.totalPage = response.xpath('//div[@class="leftContent"]//div[@class="page-box house-lst-page-box"]/a[last()-1]/text()').extract_first()
print(self.totalPage)
if self.currentPage < self.totalPage:
yield Request(nextUrl,callback=self.parse)
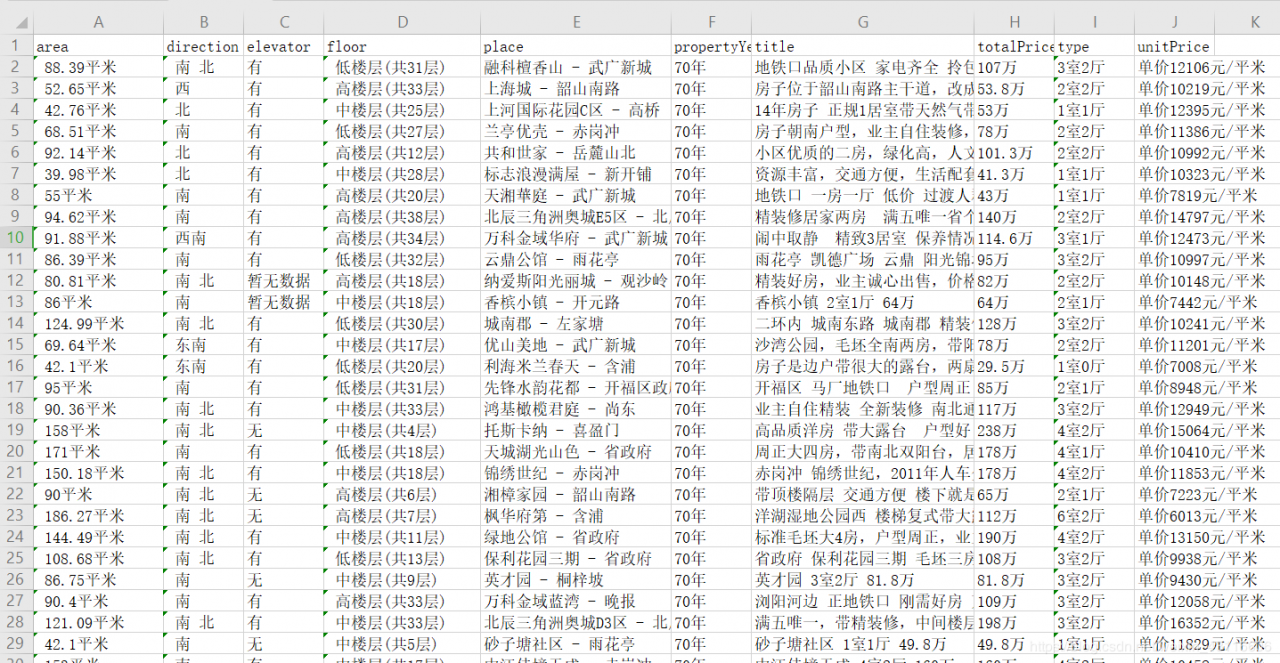
但是我们希望爬取的信息按照指定的顺序排列保存,当前的顺序是随机的。此外单价一栏下的信息是“单价12106元/平米”,正常来讲应该去掉单价二字。所以接下来使用Item Pipeline进行数据二次处理。import re
class LianjiaPipeline(object):
def process_item(self, item, spider):
item["unitPrice"]=re.sub("单价",'',item["unitPrice"])
return item
class csvPipeline(object):
def __init__(self):
self.index = 0
self.file = None
def open_spider(self,spider):
self.file = open("home.csv", "a", encoding="utf-8")
def process_item(self,item,spider):
if self.index == 0:
columnName = "title,place,type,area,direction,floor,unitPrice,totalPrice,elevator,propertyYears\n"
self.file.write(columnName)
self.index = 1
homeStr = item["title"]+","+item["place"]+","+item["type"]+","+item["area"]+","+item["direction"]+","+ \
item["floor"]+","+item["unitPrice"]+","+item["totalPrice"]+","+item["elevator"]+","+item["propertyYears"]+"\n"
self.file.write(homeStr)
return item
def close_spider(self,spider):
self.file.close()
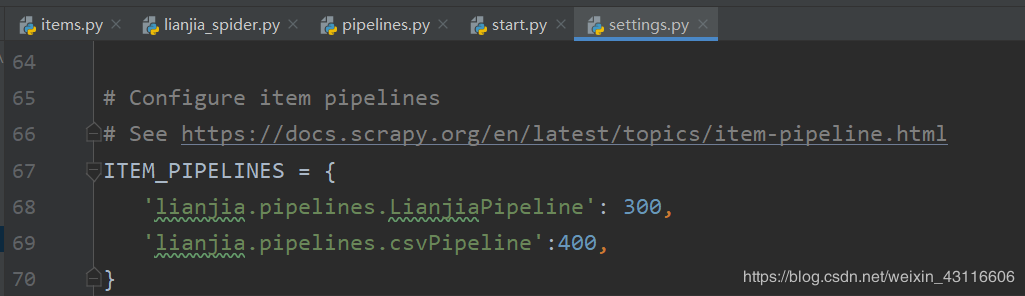
默认是'lianjia.pipelines.LianjiaPipeline': 300,这里再将csvPipeline加入,后面的数字400代表优先级,数字越小优先级越低,代表Pipeline处理item中数据的顺序。from scrapy import cmdline
cmdline.execute("scrapy crawl home".split())
 可以看到提取的信息按照我们设定的顺序排列,并且将单价信息进行了处理。
可以看到提取的信息按照我们设定的顺序排列,并且将单价信息进行了处理。#!/usr/bin/env python
# -*- coding:utf-8 -*-
#@Time : 2020/2/21 18:07
#@Author: bz
#@File : lianjia_spider.py
import scrapy
from scrapy import Request
from lianjia.items import LianjiaItem
class HomespiderSpider(scrapy.Spider):
name = 'home'
def __init__(self):
self.currentPage = 1
self.totalPage = 1
def start_requests(self):
url = 'https://cs.lianjia.com/ershoufang/'
yield Request(url,callback=self.parse)
def parse(self, response):
roomList = response.xpath('//ul/li/div[@class="info clear"]')
for oneList in roomList:
title = oneList.xpath('./div[@class="title"]/a/text()').extract_first()
place = oneList.xpath('./div[@class="flood"]//a[1]/text()').extract_first()+'- '+oneList.xpath('./div[@class="flood"]//a[2]/text()').extract_first()
houseInfo = oneList.xpath('./div[@class="address"]/div/text()').extract_first()
houseInfoList = houseInfo.split("|")
type = houseInfoList[0]
area = houseInfoList[1]
direction = houseInfoList[2]
floor = houseInfoList[4]
unitPrice = oneList.xpath('./div[@class="priceInfo"]/div[@class="unitPrice"]/span/text()').extract_first()
totalPrice = oneList.xpath('./div[@class="priceInfo"]/div[@class="totalPrice"]/span/text()').extract_first()+oneList.xpath('./div[@class="priceInfo"]/div[@class="totalPrice"]/text()').extract_first()
item = LianjiaItem()
item["title"] = title
item["place"] = place
item["type"] = type
item["area"] = area
item["direction"] = direction
item["floor"] = floor
item["unitPrice"] = unitPrice
item["totalPrice"] = totalPrice
# 获取详情链接
clearUrl = oneList.xpath('./div[@class="title"]/a/@href').extract_first()
# print(clearUrl)
yield Request(clearUrl,meta={"item":item},callback=self.clearUrlParse)
# 获取下一页链接
self.currentPage += 1
nextUrl = 'https://cs.lianjia.com/ershoufang/pg%d'%self.currentPage
self.totalPage = response.xpath('//div[@class="leftContent"]//div[@class="page-box house-lst-page-box"]/a[last()-1]/text()').extract_first()
if self.currentPage < self.totalPage:
yield Request(nextUrl,callback=self.parse)
# 详情链接解析函数
def clearUrlParse(self,response):
elevator = response.xpath('//div[@class="base"]//ul/li[last()-1]/text()').extract_first()
propertyYears = response.xpath('//div[@class="base"]//ul/li[last()]/text()').extract_first()
item = response.meta["item"]
item["elevator"] = elevator
item["propertyYears"] = propertyYears
yield item
作者:带火星的小木头