Python-爬虫爬取豆瓣top250图片
Python-爬虫爬取豆瓣top250图片Python-爬虫爬取豆瓣top250图片效果整体代码具体步骤
Python-爬虫爬取豆瓣top250图片
先来看看网站前三页的网址
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
可以看出不同的页面的区别就在于start=后的数字,可以发现它的规律是后一页会比前一页大25,利用这个规律就可以遍历top榜的每一页。引用requests库获得每张页面的源代码。
获取了每张图片的地址以后就可以将图片存入本地了。这里将图片存入douban文件夹。
作者:彭于晏辽宁分晏
最近几天一直在学习爬虫,今天终于成功的写出了一个爬虫程序——爬取豆瓣排名前250的图片。豆瓣网top250首页链接
效果先来看看最终的效果:
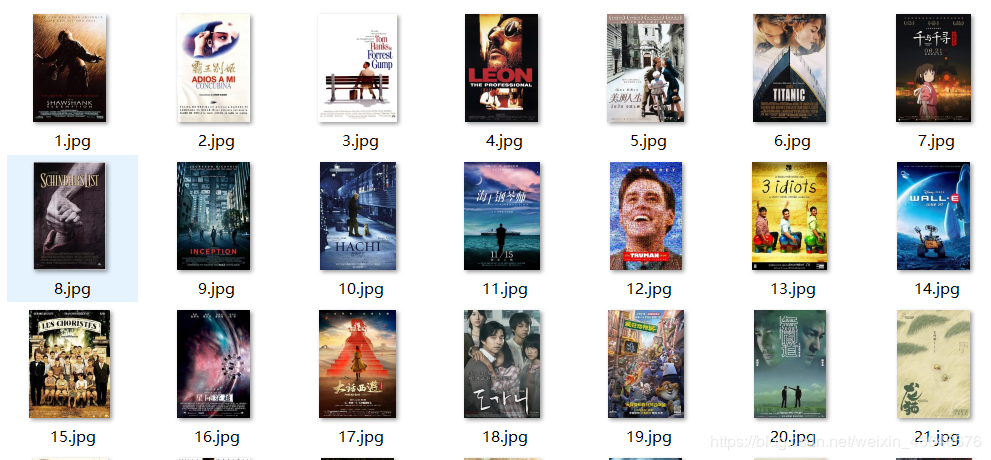
整体的代码还是比较简单的,先来看看代码。
import requests
import re
import os
CAPTCHA_IMAGE_FOLDER = "D:\douban"
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36'}
if not os.path.exists(CAPTCHA_IMAGE_FOLDER): #如果不存在目标文件夹,则重新建立该文件夹
os.makedirs(CAPTCHA_IMAGE_FOLDER)
page=0
while page <=225:
res = requests.get('https://movie.douban.com/top250?start='+str(page)+'&filter=',headers=headers)
html=res.text
chapter_photo_list=re.findall(r'https:.*jpg',html)
m=1
for chapter_photo in chapter_photo_list:
img = requests.get(chapter_photo)
f = open(CAPTCHA_IMAGE_FOLDER+'/'+str(page+m)+'.jpg', 'ab')
f.write(img.content)
f.close()
m=m+1
page=page+25
print('end')
具体步骤
网页网址分析,获取网页源代码先来看看网站前三页的网址
https://movie.douban.com/top250?start=0&filter=
https://movie.douban.com/top250?start=25&filter=
https://movie.douban.com/top250?start=50&filter=
可以看出不同的页面的区别就在于start=后的数字,可以发现它的规律是后一页会比前一页大25,利用这个规律就可以遍历top榜的每一页。引用requests库获得每张页面的源代码。
import requests
page=0
while page <=225:
res = requests.get('https://movie.douban.com/top250?start='+str(page)+'&filter=',headers=headers)
html=res.text
page=page+25
print(html)
图片网址分析
可以通过上面输出的源代码查找,也可以在网页直接查看源代码。但是这里有一点不同,网页查看的源代码和python中输出的源代码会有一点不同。
python中:
https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg
网页源代码中:
https://img3.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp
可以看出只是后缀有一点不同,所以最好还是在python中查看,以免后续用正则表达式截取图片网址时截取不到。
从网页源代码中截取所有图片的地址
通过对多张图片的地址进行分析,可以看出用https:开头.jpg结尾这个限制就可以截取出该张页面的所有图片的地址。这部分利用正则表达式,引用re库。
chapter_photo_list=re.findall(r'https:.*jpg',html)
print(chapter_photo_list)
将图片存入本地获取了每张图片的地址以后就可以将图片存入本地了。这里将图片存入douban文件夹。
for chapter_photo in chapter_photo_list:
img = requests.get(chapter_photo)
f = open(CAPTCHA_IMAGE_FOLDER+'/'+str(page+m)+'.jpg', 'ab')
f.write(img.content)
f.close()
作者:彭于晏辽宁分晏