b站直接用BV号爬虫抓取评论
b站的评论由js加载,所以我们有两种方法获取,
第一种用selenium,拖拽导航条,刷新出评论再抓取(效率低且代码量大)
第二种直接找到js接口去获取数据
先说下我一开始的思路
我刚开始不确定是xhr还是js,所以现在xhr中找,发现并没有,于是搜索了js,发现在这个接口里
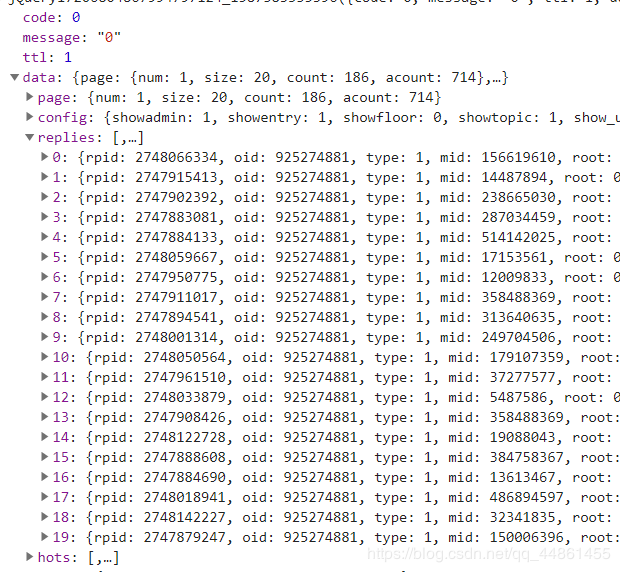
page代表页数和评论数量,replies是所有评论的内容
于是我们开始分析这个接口的参数
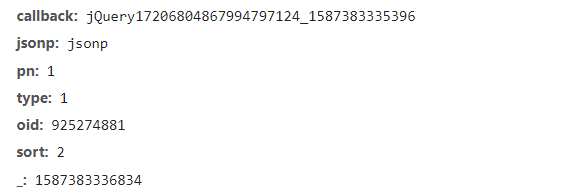
刚开始我以为callback是js加密,后来发现这个参数加不加效果是一样的,
多次试验后发现只有pn,type,oid,sort是必须的
pn是当前页数
type默认为1,作用未知
oid是视频的id
sort是排序
我这边直接上代码
import requests
from bs4 import BeautifulSoup
import json
headers={
'User-Agent': 'XXXX'
}
#视频id
oid = 36613746
#评论页数
pn = 1
#排序种类 0是按时间排序 2是按热度排序
sort = 2
while True:
url =f'https://api.bilibili.com/x/v2/reply?pn={pn}&type=1&oid={oid}&sort={sort}'
reponse = requests.get(url,headers=headers)
a = json.loads(reponse.text)
if pn==1:
count = a['data']['page']['count']
size = a['data']['page']['size']
page = count//size+1
print(page)
for b in a['data']['replies']:
print(b['content']['message'])
print('-'*10)
if pn!=page:
pn += 1
else:
break
这里会直接打印出oid为36613746视频里的所有评论(不包括子评论),如果要保存数据,自己选择打印出文件或者存入数据库。
现在唯一的问题是不能用视频网址直接弄出评论,还要f12去看oid,如果有谁有好的想法,请评论告诉我一下。谢谢
--------------------------4.21更新如下-------------------------
我在评论的提示下发现,oid和视频av号是一样的,只是b站在3月已经将av参数变成了BV参数,所以我们需要将视频url的BV转成av。
知乎大佬已经给出了转换的算法
[https://www.zhihu.com/question/381784377?rf=381829319]
table='fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF'
tr={}
for i in range(58):
tr[table[i]]=i
s=[11,10,3,8,4,6]
xor=177451812
add=8728348608
def dec(x):
r=0
for i in range(6):
r+=tr[x[s[i]]]*58**i
return (r-add)^xor
def enc(x):
x=(x^xor)+add
r=list('BV1 4 1 7 ')
for i in range(6):
r[s[i]]=table[x//58**i%58]
return ''.join(r)
print(dec('BV17x411w7KC'))
print(dec('BV1Q541167Qg'))
print(dec('BV1mK4y1C7Bz'))
print(enc(170001))
print(enc(455017605))
print(enc(882584971))
作者:mcfx
链接:https://www.zhihu.com/question/381784377/answer/1099438784
这个原理我并没有搞懂,就直接用大佬的成果吧
然后我重新写了一下我的代码
import requests
from bs4 import BeautifulSoup
import json
headers={
'User-Agent': 'XXX'
}
#视频bv
bv = 'BV18t411y7a6'
#评论页数
pn = 1
#排序种类 0是按时间排序 2是按热度排序
sort = 2
i=1
panduan=0
#bv,av互换算法
table='fZodR9XQDSUm21yCkr6zBqiveYah8bt4xsWpHnJE7jL5VG3guMTKNPAwcF'
tr={}
for i in range(58):
tr[table[i]]=i
s=[11,10,3,8,4,6]
xor=177451812
add=8728348608
def dec(x):
r=0
for i in range(6):
r+=tr[x[s[i]]]*58**i
return (r-add)^xor
def enc(x):
x=(x^xor)+add
r=list('BV1 4 1 7 ')
for i in range(6):
r[s[i]]=table[x//58**i%58]
return ''.join(r)
#bv转换成oid
oid = dec(bv)
fp = open('comment.txt',"w",encoding="UTF-8")
while True:
url =f'https://api.bilibili.com/x/v2/reply?pn={pn}&type=1&oid={oid}&sort={sort}'
reponse = requests.get(url,headers=headers)
a = json.loads(reponse.text)
if pn==1:
count = a['data']['page']['count']
size = a['data']['page']['size']
page = count//size+1
print(page)
for b in a['data']['replies']:
panduan = 0
str1=''
str_list = list(b['content']['message'])
for x in range(len(str_list)):
if str_list[x]=='[':
panduan=1
if panduan!=1:
str1 = str1+str_list[x]
if str_list[x] == ']':
panduan=0
fp.write(str(i)+'、'+str1+'\n'+'-'*10+'\n')
print(str1)
print('-'*10)
i = i + 1
if pn!=page:
pn += 1
else:
fp.close()
break
这个新代码可以直接用BV号来下载评论了,而不用去F12找oid的,这里要感谢评论区的大佬提醒
这里我屏蔽了类似[小电视]这种表情文字,如果不需要可以直接用最上面的代码
作者:aka 药过
相关文章
Flower
2020-11-13
Manda
2020-07-07
Bliss
2022-10-14
Vidonia
2022-10-17
Faye
2022-10-23
Roselani
2022-10-23
Beth
2022-10-23
Tricia
2022-10-23
Fiorenza
2022-10-23
Hazel
2022-10-23
Nancy
2022-10-23
Bonita
2022-10-23
Liana
2022-10-23
Jenna
2022-10-23
Bambi
2022-11-07
Rhea
2023-02-26
Tricia
2023-04-30