一个简单的新冠肺炎数据爬虫
爬的这个页面 http://m.sinovision.net/newpneumonia.php
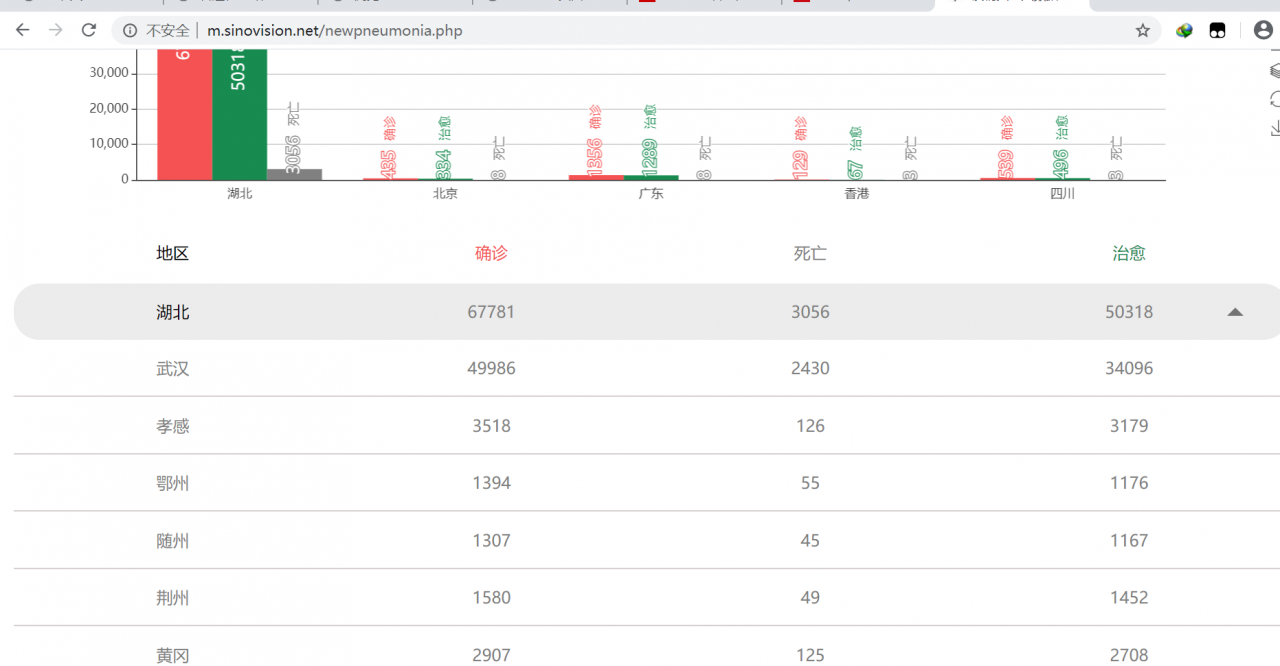
爬虫三步走:下载数据、解析数据、持久化数据
使用requests库下载,BeautifulSoup库解析,csv库存储
代码:
import requests
from bs4 import BeautifulSoup
import csv
import time
class DataScrapyer:
def __init__(self):
self.headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.89 Safari/537.36'}
self.scrapy_url = "http://m.sinovision.net/newpneumonia.php"
self.data = None
def run(self, from_cache=False):
print("[!]开始运行……")
HTML = self.getHTMLContent(from_local=from_cache) # 不知为何现爬极慢,可以把之前爬下来的HTML文件当作缓存
print("[+]爬取数据完成")
data = self.parseData(HTML)
print("[+]解析数据完成")
self.data = data
def getHTMLContent(self, from_local=False):
if from_local:
try:
with open("cache.html", "r") as f:
return f.read()
except OSError:
print("[!]缓存文件不存在!请先将from_cache参数置为False运行一次")
exit(1)
response = requests.get(url=self.scrapy_url, headers=self.headers)
response.encoding = response.apparent_encoding
if response.status_code == 200:
with open("cache.html", "w") as f:
f.write(response.text)
return response.text
else:
raise Exception
def parseData(self, HTML_content):
soup = BeautifulSoup(HTML_content, "html.parser")
HTML_china = soup.find_all("div", class_="todaydata")[7]
HTML_province_list = HTML_china.find_all("div", class_="main-block")
data_provinces_list = []
for HTML_province in HTML_province_list:
# 获取这个省的数据
HTML_this_province_data = HTML_province.find("div", class_="prod")
this_province_data = {
"area": HTML_this_province_data.find("span", class_="area").text,
"confirm": HTML_this_province_data.find("span", class_="confirm").text,
"dead": HTML_this_province_data.find("span", class_="dead").text,
"cured": HTML_this_province_data.find("span", class_="cured").text,
}
# 获取这个省每个城市的数据
data_citys_list = []
HTML_city_list = HTML_province.find_all("div", class_="prod-city-block")
for HTML_city in HTML_city_list:
this_city_data = {
"city-area": HTML_city.find("span", class_="city-area").text,
"confirm": HTML_city.find("span", class_="confirm").text,
"dead": HTML_city.find("span", class_="dead").text,
"cured": HTML_city.find("span", class_="cured").text,
}
data_citys_list.append(this_city_data)
# 合并保存
data_provinces_list.append({
"province_summary_data": this_province_data,
"citys": data_citys_list,
})
return data_provinces_list
def output_to_csv(self, data):
# 由于csv是二维表,无法直接存储高维数据,所以只输出了省级数据
file_name = f"data_{time.time()}.csv"
with open(file_name, "w", newline="") as f:
csv_writer = csv.writer(f)
table_head = ["省份", "确诊数", "死亡数", "治愈数"]
csv_writer.writerow(table_head)
for d in data:
pro_d = d["province_summary_data"]
csv_writer.writerow([pro_d["area"], pro_d["confirm"], pro_d["dead"], pro_d["cured"]])
print(f"[+]输出至文件 {file_name}")
if __name__ == '__main__':
ds = DataScrapyer() # 建立对象
ds.run(from_cache=False) # 运行
ds.output_to_csv(ds.data) # 写入省级数据至csv
爬取过一次数据后可以将from_cache参数置为False,这样就可以利用上一次的缓存文件演示了,对于重新爬取这个页面来说会快很多。
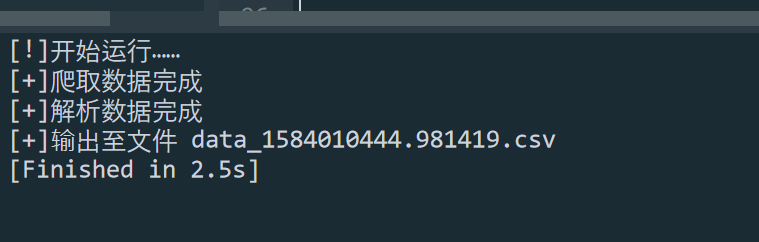
运行截图
希望看到疫情数据早日清零。
作者:Rabbit_Gray
相关文章
Hope
2021-07-09
Flower
2020-11-13
Rachel
2023-07-20
Psyche
2023-07-20
Winola
2023-07-20
Gella
2023-07-20
Grizelda
2023-07-20
Janna
2023-07-20
Ophelia
2023-07-21
Crystal
2023-07-21
Laila
2023-07-21
Aine
2023-07-21
Bliss
2023-07-21
Lillian
2023-07-21
Tertia
2023-07-21
Olive
2023-07-21
Angie
2023-07-21
Nora
2023-07-24