半次元cos图片爬虫
这是我第一次写博客,有不足的地方请见谅
先放码
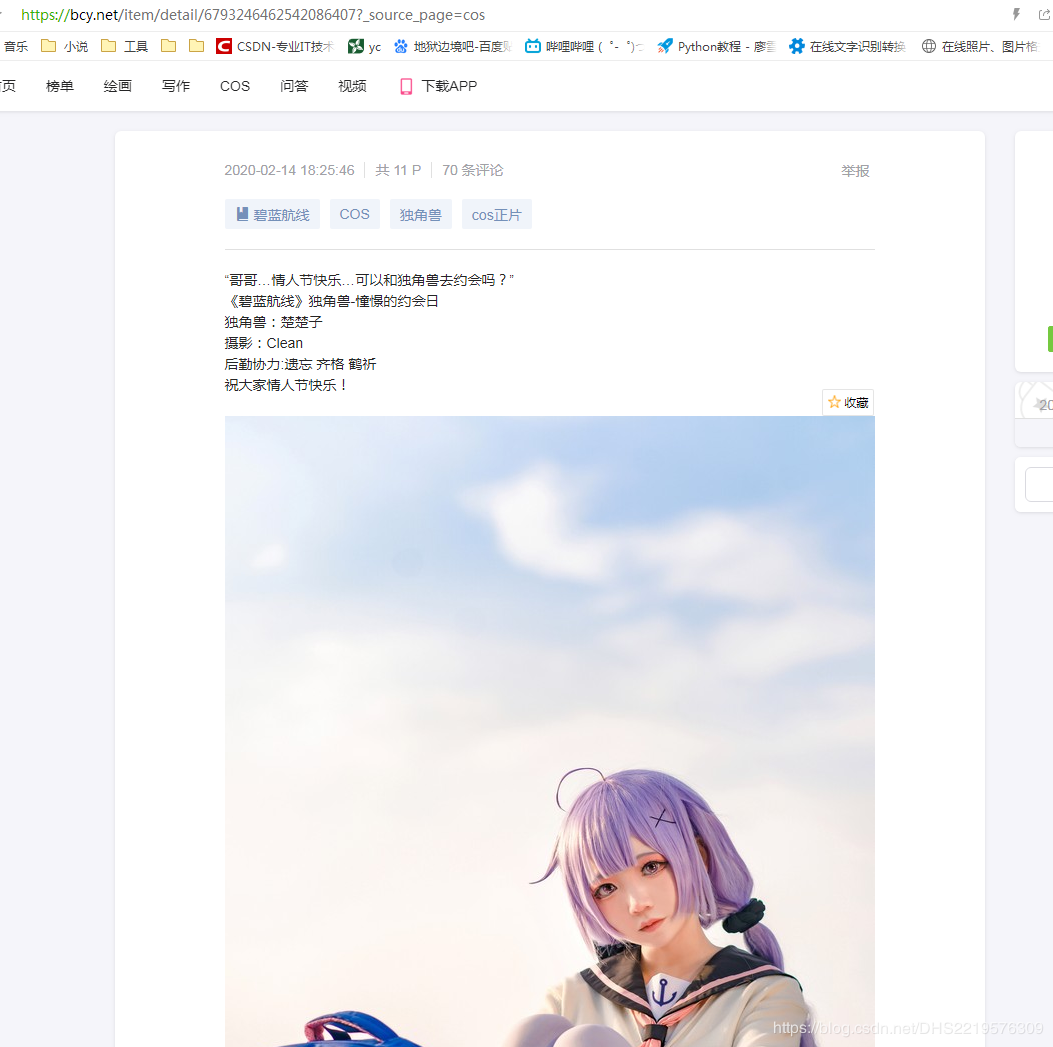 获取网址 https://bcy.net/item/detail/6793246462542086407?_source_page=cos
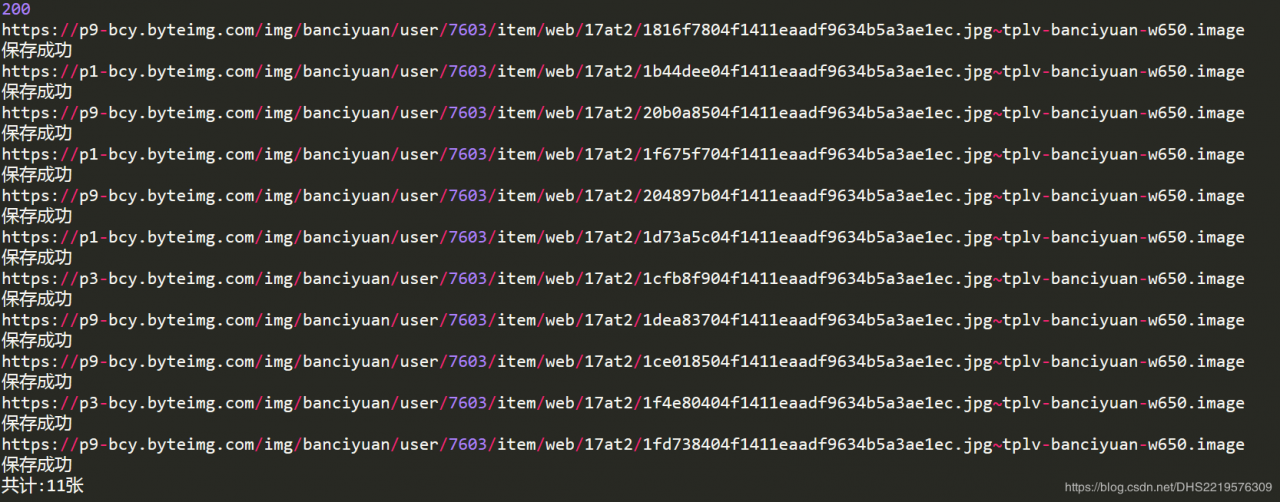
代码运行结果
获取网址 https://bcy.net/item/detail/6793246462542086407?_source_page=cos
代码运行结果
 文章到这里就结束了,虽然我就是个萌新,但是我还是要说说我看到的现象。
我就纳闷了,为什么搜到关于半次元爬虫的博客都是千篇一律,还都是标上原创(难道是量子力学)。看了一堆一模一样的博客,发现没什么用处后(网站的结构改变,唯一可以学习到的知识就是数据的分析了),我决定自力更生,打破技术垄断(滑稽)
如果觉得我代码有问题的可以在评论中指出,我会加以改正,希望我的这篇博客有帮到你们,谢谢。
时间:2020/2/22
作者:竟然有高手
文章到这里就结束了,虽然我就是个萌新,但是我还是要说说我看到的现象。
我就纳闷了,为什么搜到关于半次元爬虫的博客都是千篇一律,还都是标上原创(难道是量子力学)。看了一堆一模一样的博客,发现没什么用处后(网站的结构改变,唯一可以学习到的知识就是数据的分析了),我决定自力更生,打破技术垄断(滑稽)
如果觉得我代码有问题的可以在评论中指出,我会加以改正,希望我的这篇博客有帮到你们,谢谢。
时间:2020/2/22
作者:竟然有高手
import requests
import re
import os
url = '' #填入目标网址
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'}
while True: #如果出错就会进入循环
try:
response = requests.get(url,headers = head)
except:
print('erro:'+str(response.status_code))
else:
print(response.status_code)
break
num = 0 #用于后面的计算图片数目
for Format in ('.jpg','.png'):
url = re.findall('https:(.{140,155}?)'+Format+'~tplv-banciyuan-w650.image',response.text)
#正则表达式匹配目标图片地址
for i in url:
num += 1
a = i.replace('u002F','').replace('\\\\','/') #使用replace()对字符串进行替换
#由于获取的图片地址含有u002F等无用字块在这里进行处理(可能是我技术问题,我获取的源码有点诡异)
url = 'https:'+a+Format+'~tplv-banciyuan-w650.image' #对图片链接进心重构
try: #如果出错就跳过并抛出问题网址
r = requests.get(url,headers = head)
except:
print('出错啦:'+url)
else:
print(url)
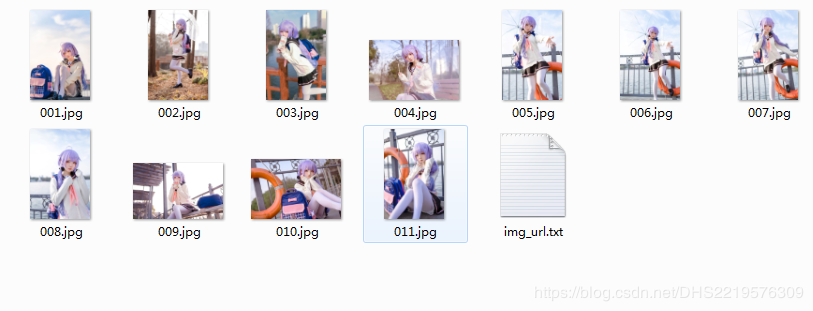
number = len(os.listdir(os.getcwd()+'/cos')) #获取存储目录文件数目,用于给图片起名
if number <= 9:
number = '00'+str(number)
elif 10 <= number < 100:
number = '0'+str(number)
else:
number = str(number)
open('./cos/'+number+Format,'wb').write(r.content)
open('./cos/img_url.txt','a+').write(url+'\n')#将图片链接保存于文本中,使用附加方法打开
print('保存成功')
print('共计:'+str(num)+'张')
受限于我的技术,图片链接应该是从网站的JavaScript代码中获取的所以会出现“u002F”这样的字块
从网页的源代码中分析出,半次元的图片链接通常储存在以.jpg~tplv-banciyuan-w650.image和.png~tplv-banciyuan-w650.image这两种后缀为结尾的链接中。
虽然图片地址是以.image为结尾但是在储存的时候还是要以开头时的.jpg或.png这两种文件格式进行存储
建议在 https://bcy.net/coser 这个网页目录下进行图集网址的获取,因为我只是根据这个网页目录下的图集进行分析
效果图
获取网址 https://bcy.net/item/detail/6793246462542086407?_source_page=cos
代码运行结果
文章到这里就结束了,虽然我就是个萌新,但是我还是要说说我看到的现象。
我就纳闷了,为什么搜到关于半次元爬虫的博客都是千篇一律,还都是标上原创(难道是量子力学)。看了一堆一模一样的博客,发现没什么用处后(网站的结构改变,唯一可以学习到的知识就是数据的分析了),我决定自力更生,打破技术垄断(滑稽)
如果觉得我代码有问题的可以在评论中指出,我会加以改正,希望我的这篇博客有帮到你们,谢谢。
时间:2020/2/22
作者:竟然有高手
相关文章
Flower
2020-11-13
Madeleine
2020-10-11
Bliss
2022-10-14
Vidonia
2022-10-17
Faye
2022-10-23
Roselani
2022-10-23
Beth
2022-10-23
Tricia
2022-10-23
Fiorenza
2022-10-23
Hazel
2022-10-23
Nancy
2022-10-23
Bonita
2022-10-23
Liana
2022-10-23
Jenna
2022-10-23
Bambi
2022-11-07
Rhea
2023-02-26
Tricia
2023-04-30