【mysql知识点整理】--- order by 、group by 出现Using filesort原因详解
CREATE TABLE tbl(
id int primary key not null auto_increment,
age INT,
birth TIMESTAMP NOT NULL,
name varchar(20),
salary decimal(10,2)
);
INSERT INTO tbl(age,birth,name,salary) VALUES(22,NOW(),'abc',10000.11);
INSERT INTO tbl(age,birth,name,salary) VALUES(23,NOW(),'bcd',5000.55);
INSERT INTO tbl(age,birth,name,salary) VALUES(24,NOW(),'def',60000.66);
CREATE INDEX idx_age_birth_name ON tbl(age,birth,name);
1 sql执行顺序
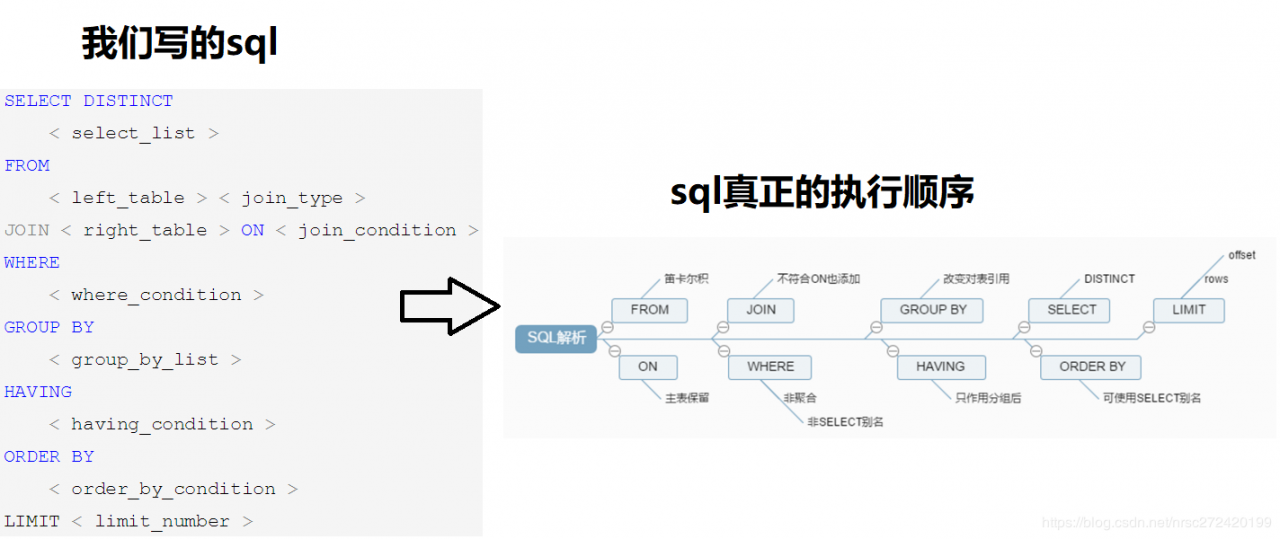
首先要知道,如上图所示,order by 和 group by是将where 条件查出来的数据进行排序和分组(其实分组实质上是先排序,然后将排好序的数据进行分开)。
同时还应知道,通过索引查询出来的数据是按照索引排好顺序的。
2 order by 和 group by什么时候会出现Using filesort — 理论在实际生产中order by和group by语句特别容易出现Using filesort ,比如下面的语句:
explain select * from tbl where age > 10 order by birth;
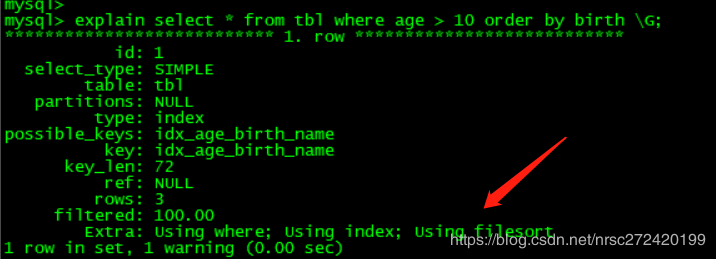
在这种时候该怎样进行优化呢???
我觉得在谈优化之前,首先应该明确什么时候会出现Using filesort,而什么时候不会。
不会出现Using filesort的情况 : 通过where条件查询出的数据,如果按照order by进行排序的话,本来就是有序的;
会出现Using filesort的情况 : 通过where条件查询出的数据,如果按照order by进行排序的话,不是有序的就会出现。
看完上面的两句话,可能你会懵逼,不知道我在说什么。。。但是你要是真正明白了我在1中说写的那两句话,你肯定就知道我想表达什么了,这里再强调一遍:
通过索引查询出来的数据是按照索引排好顺序的。
如若真的明白了2中所诉道理之后我们就可以做出如下总结。
假如你有一张表,里面有个联合索引 KEY idx_a_b_c(a,b,c)
举例如下:
— order by a
— order by a, b
— order by a,b,c
— order by a desc,b desc ,c desc
验证如下:
explain select age, birth,name from tbl where age >10 order by age;
explain select age, birth,name from tbl where age >10 order by age,birth;
explain select age, birth,name from tbl where age >10 order by age,birth,name;
explain select age, birth,name from tbl where age >10 order by age desc,birth desc,name desc;
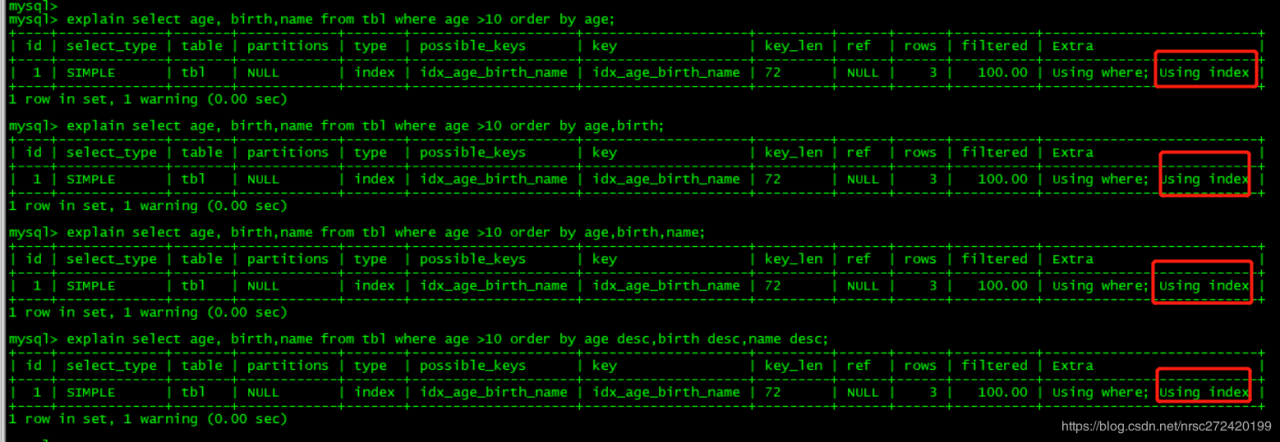
这时候order by 后面的内容其实仍然要符合最佳左前缀原则
— where a = const XXX order by a, b,c
--注意,a本来就是常量,所以where查询出的内容完全可以说是按照a,b,c进行排序的,当然也可以说出按照b,c进行排序的
— where a = const order by b,c
— where a = const and b = const order by c
— where a =const and b > const order by b,c
验证如下:
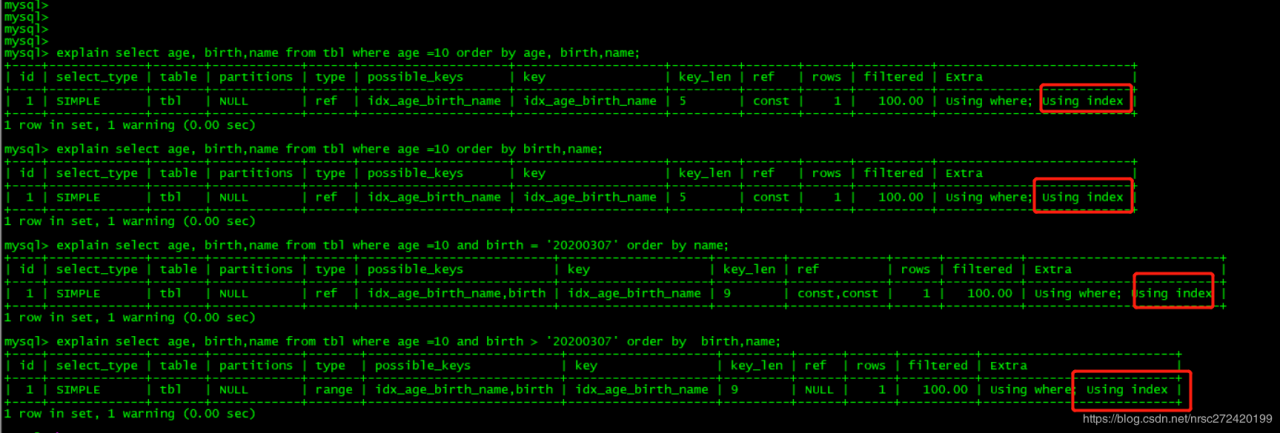
explain select age, birth,name from tbl where age =10 order by age, birth,name;
explain select age, birth,name from tbl where age =10 order by birth,name;
explain select age, birth,name from tbl where age =10 and birth = '20200307' order by name;
explain select age, birth,name from tbl where age =10 and birth > '20200307' order by birth,name;
在3.1.1和3.1.2中我写的sql都用到了覆盖索引,但是在非覆盖索引的情况下,稍微会有点区别,以3.1.1中的sql为例,假如我将查询的内容改为 * ,我们再来看一下其执行计划:
explain select* from tbl where age >10 order by age;
explain select* from tbl where age >10 order by age,birth;
explain select* from tbl where age >10 order by age,birth,name;
explain select* from tbl where age >10 order by age desc,birth desc,name desc;
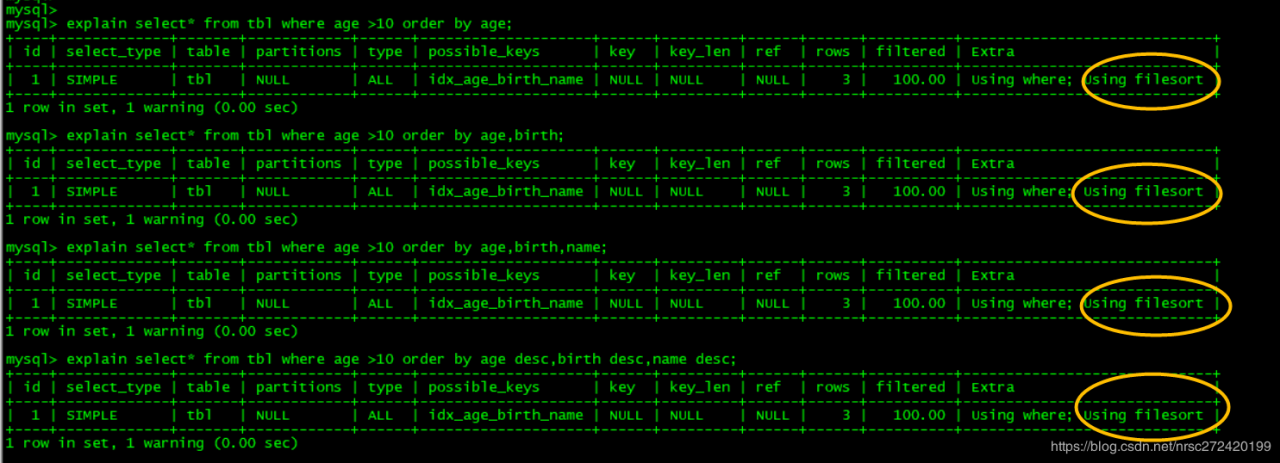
从上图可以看到,竟然使用了内部排序,而且你更应该感到惊讶的是: 通过key列为Null,可以知道,它不光使用了内部排序,竟然连索引都没有使用。。。。
这是什么情况呢???难道2中理论部分理解的有问题???
其实并不是,而是mysql在这里做了一定的优化:
在进行 大于 查询时,mysql会找到你的目标条件在索引树上的最小值,假如你指定的值,比索引树上的最小值还小,那肯定就是要查询所有的数据了,那mysql就懒得再去遍历你目标条件所在的索引树了,而是直接通过聚簇索引搜索出所有数据。
知道了这个之后,我们就可以知道为什么下面的第2、3条语句会使用索引了:
explain select* from tbl where age > 10 order by age desc,birth desc,name desc;
explain select* from tbl where age > 22 order by age desc,birth desc,name desc;
explain select* from tbl where age > 25 order by age desc,birth desc,name desc;

当然从图中我们可以看出mysql也并没有那么智能,即我数据库里age最大的为24,但我查询条件为age>25 时,它仍然会进行查询。。。
同时从这里还可以看出来出现Extra 列 出现Using index condition 的情况, 即:
虽然我们写的SQL 操作命中了索引,但不是所有的列数据都在索引树上,还需要访问实际的行记录。
在这里放个链接,作为《【mysql知识点整理】— mysql执行计划详解》那篇文章的补充。
3.2 会出现 Using filesort的情况会将where查询出的数据进行再次内部排序, 然后才返回结果,即会出现 Using filesort的情况,举例如下:
— order by a asc, b desc, c desc -- 排序不一致的情况
— order by b, c -- 丢失a索引
— where a = const order by c -- 丢失b索引
— order by a,d -- d不是索引的一部分
— where a in (...) order by b,c
--这种情况也属于丢失a索引,并且in里面如果只有一个值时mysql会优化为常量,如果为多个值时,哪怕这些值全一样,也会出现 Using filesort
证明如下:
explain select age, birth,name from tbl where age >10 order by age asc, birth desc, name desc;
explain select age, birth,name from tbl where age >10 order by birth, name ;
explain select age, birth,name from tbl where age =10 order by name;
explain select age, birth,name from tbl where age =10 order by age, salary;
explain select age, birth,name from tbl where age in (10,20,30) order by birth, name;
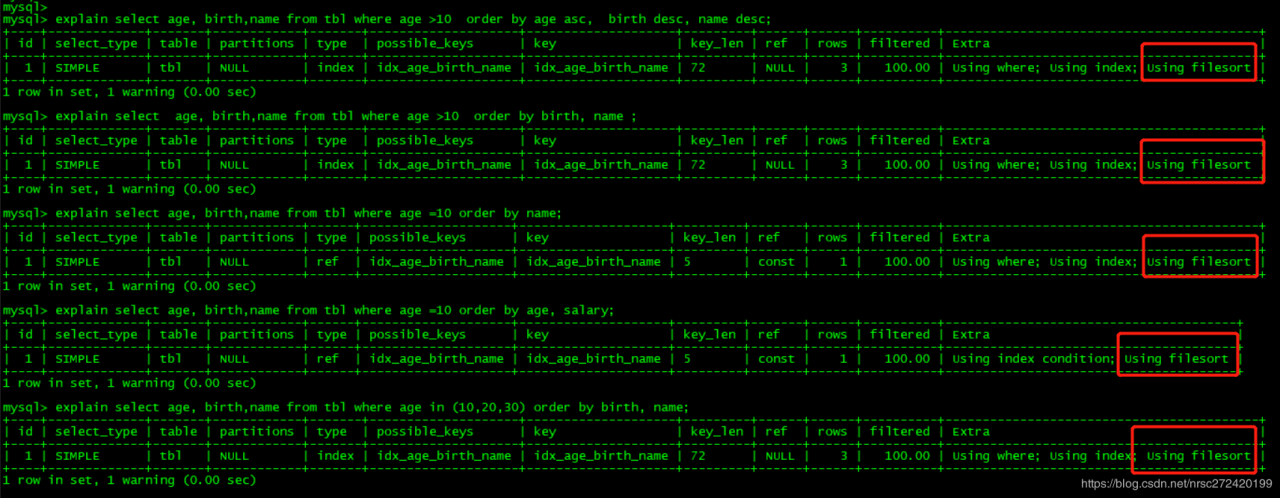
注意1: 由于in中的内容很可能是无序的,甚至是重复的,因此where 中有in 作为条件的话,查出的数据有可能是无序的,因此where 条件中有in时,还是会出现 Using filesort;
比如说下面这条语句,我实际业务中排序规则就是按照name排,该怎么办???
explain select age, birth,name from tbl where age > 22 order by name;
可能你会想在name上单独再建立一个索引 ,但是然并卵!!!
create index idx_name on tbl (name);
show index from tbl;
explain select age, birth,name from tbl where age > 22 order by name;

这是为什么呢? 其实还是要理解我在2中所讲的:
(1) order by 进行排序是将where 条件查询之后的数据进行排序
(2)之所以符合最佳左前缀法则时,它不会再排序,是因为通过索引查询出来的数据本来就是根据索引的最佳左前缀法则排好序序的。
而上面的语句通过where查询数据时并不会走name所在列的单独索引,所以查出来的数据也肯定不是根据name进行排好序的 —》 因此,这个时候在name列单独建立索引是没有任何作用的!!!
3.2 希望能得到您的解决方案说实话遇到这种情况,我在工作中还真没找到更优的解决方案。
但是由于工作中往往很少有查询全部数据的 —> 大都会进行分页。
经过我的测试,只要where使用了覆盖索引,即使上百万条数据,也可以在很短的时间内查出来。
测试数据如下:DROP PROCEDURE IF EXISTS my_insert;
CREATE PROCEDURE my_insert()
-- 定义存储过程
BEGIN
DECLARE n int DEFAULT 0;
loopname1:LOOP
INSERT INTO `test1`.`tbl` (`age`, `birth`, `name`, `salary`)
VALUES (
-- 随机年龄
(FLOOR(0+RAND()*100)),
-- 随机日期 1990 - 2020
CONCAT(FLOOR(1990 + (RAND() * 30)),'-',LPAD(FLOOR(1 + (RAND() * 12)),2,0),'-',LPAD(FLOOR(3 + (RAND() * 8)),2,0)),
-- 姓名,随机字符串
substring(MD5(RAND()),1,8),
-- 随机工资
(FLOOR(10000+RAND()*1000))
);
SET n=n+1;
IF n=1000000 THEN
LEAVE loopname1;
END IF;
END LOOP loopname1;
END;
-- 执行存储过程
CALL my_insert();
测试结果如下:
select age, birth,name from tbl where age > 22 order by name limit 20000,1000;
select age, birth,name from tbl where age > 22 order by name limit 5000,100
select age, birth,name from tbl where age > 22 order by name limit 50,10

可以看到从一百万条数据里查询1000条只需0.08142575秒,查询100条只需0.01615575,而查询10条只需0.00065200秒,其实我感觉已经够用了。
当然,欢迎您能提供更优的解决方案。
group by 与order by一致。
作者:nrsc