OpenStack nova 虚拟机 NUMA 架构(理论)
先简单介绍一下计算机平台体系架构
SMP(多对称处理器,sysmmeric multi-process),SMP由多个具有对称关系的处理器组成。对称即处理器之前属于水平的镜像关系,无从属之分。SMP架构的出现使计算机不再由单个cpu组成。
SMP的典型特征为多个处理器共享一个集中式存储器,且每个处理器访问存储器的时间片相同,使得工作负载能够均匀分配到所有可用处理器上,极大地提高了整个系统的数据处理能力。
大概就这样的:

虽然SMP有多个处理器,但由于只有一个共享的集中式存储器,所以只能运行一个操作系统和数据库系统的副本,依然保持了单极性。同时,SMP也会要求共享存储器保证数据一致性。如果多个处理器同时访问内存,就需要由软件或硬件实现的加锁机制来解决资源竞态问题,所以SMP又称为UMA(Uniform memory access,一致性存储器访问),一致性指:
1.在任意时刻,每个处理器只能为存储器保存或共享一个唯一的值;
2.每个处理器访问存储器所需要的时间都是一致的;
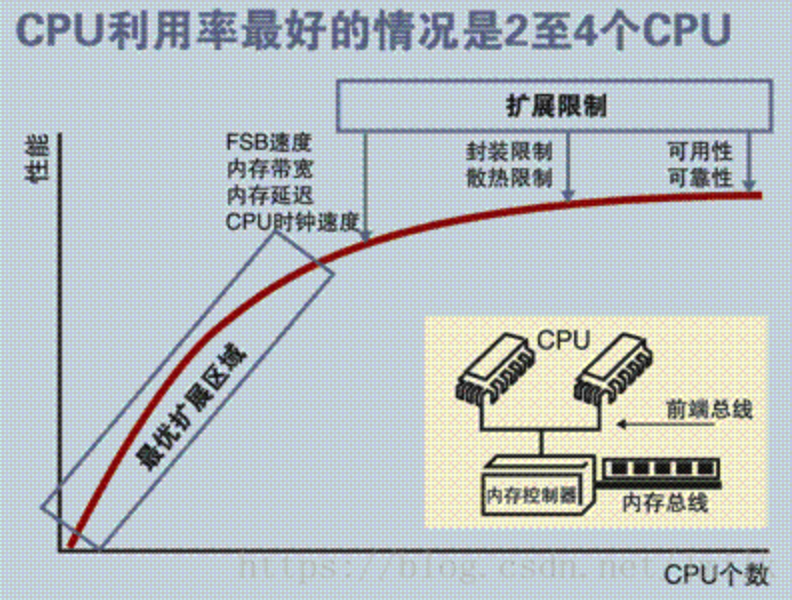
很显然,这样的设计没办法拥有良好的处理器数量扩展性,因为共享资源的资源竞态总是存在的,处理器的利用率最好的情况一般是在2-4颗。综合来看,SMP架构广泛用于PC和移动设备领域,能显著提升并行计算性能。但SMP并不适合超大规模的服务器端场景,例如:云计算。
NUMA非同一内存访问结构:
现在计算机系统,处理器的访问速度,已经超过了主存的读写速度,限制计算机计算性能的瓶颈转移到存储带宽之上。SMP由于集中式的共享存储的设计,限制了处理器访问存储器的频次,导致处理器对存储器的访问处于饥饿状态。
NUMA的设计理念是将处理器和存储器分别划分到不同的节点,他们都拥有几乎相等的资源,在NUMA节点的内部会通过自己的存储总线访问内部的本地内存,而所有NUMA节点都可以通过主板上的共享总线来访问其他节点的远程内存。
大概这个样子:

很显然,处理器访问本地内存和远程内存的耗时并不一致,所以叫NUMA非一致内存访问,因为节点划分没有实际意义上的存储隔离,所以NUMA只会保存一份操作系统和数据库系统的副本。
NUMA多节点的结构设计,在一定程度上可以SMP低存储带宽的问题,假如有一个4NUMA节点的系统,每一个NUMA节点内部1GB/s的存储带宽,外部共享总线也具有1GB/s的带宽。理想状态下,所有处理器总是访问本地内存的话,那么系统就拥有4GB/s的存储带宽能力,此时,每个节点都可以近似的看作一个SMP;最不理想情况下,所有处理器都访问远程内存的话,系统就只有1GB的存储带宽能力。
此外,使用外部共享总线时,还可能会触发NUMA节点间的Cache同步异常,这会影响内存密集型工作负载的性能。当I/O性能重要时,共享总线上的cache资源浪费,会让连接到远程PCI总线上的设备(不同numa节点之间通信)性能急剧下降。
所以,基于NUMA开发的应用程序应该尽可能避免跨节点的内存访问。因为跨节点的内存访问,不仅速度慢,还可能需要处理不同节点间内存和缓存的数据一致性。多线程在不同NUMA节点间的切换,是需要花费大量成本的。
虽然NUMA相比SMP具有更好的处理器扩展性,但是NUMA没有彻底的主存隔离。所以NUMA远没有达到无限扩展的水平,最多可支持几百个CPU。这是为了追求更高的性能做出的妥协,一个节点未必能满足多并发需求,多节点之间线程切换实属一个折中的方案。这种做法使NUMA具有一定的伸缩性,更加适合应用在服务器端。
下篇写Linux上NUMA
作者:li136237