OpenCL——AMD平台搭建
介绍在Windows系统下基于AMD GPU的OpenCL环境的搭建,并且基于矢量加法实例程序。
构建示例在传统的AMD APP SDK设计中,已经不存在了,不知道为什么。但是AMD给了一种其他的方式,
https://github.com/GPUOpen-LibrariesAndSDKs/OCL-SDK/releases
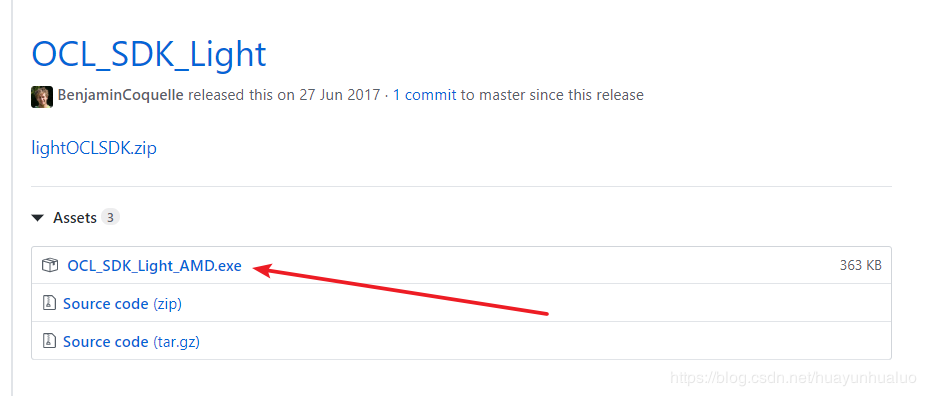
下载OCL_SDK_Light_AMD.exe,进行安装。
安装完成之后
在VS中创建一个项目,博主使用的是VS 2019。创建完的项目以后,具体操作如下
在新建的解决方案中,右键点击解决方案名称,选择属性选项。
依次选择 C++ —> 常规 ——> 附加包含目录 ——> 编辑
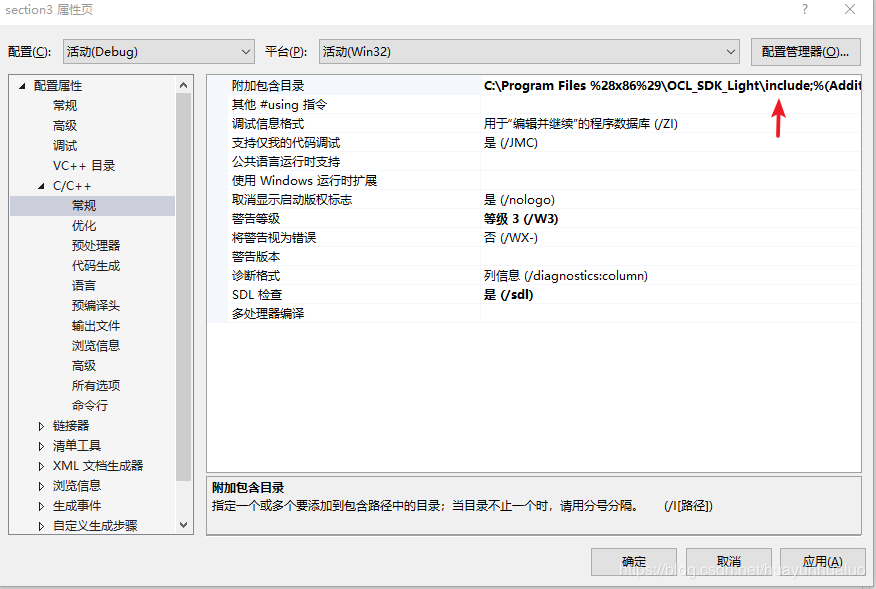
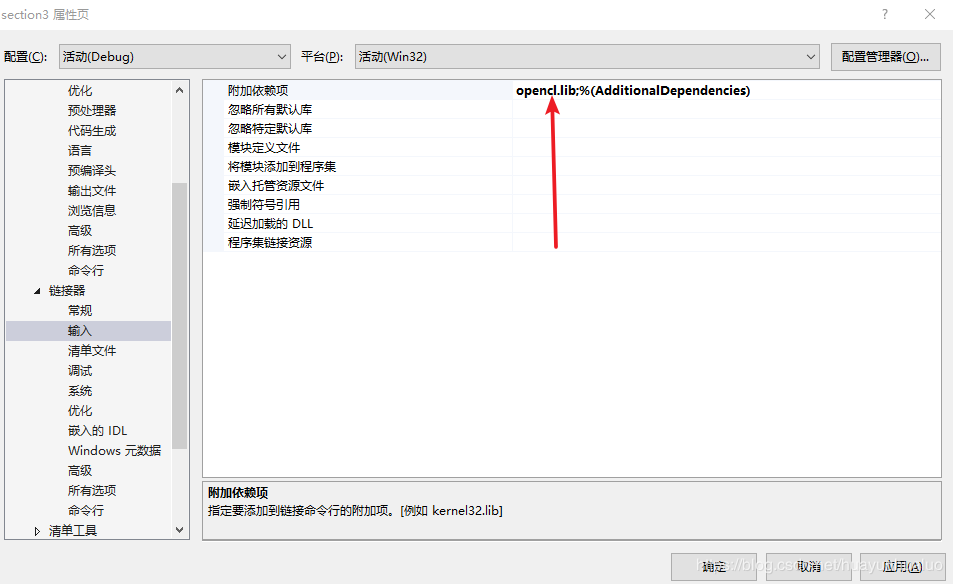
依次选择 链接器 ——> 常规 ——> 附加库目录

main.cpp
#include
#include
#include
const int ARRAY_SIZE = 1000;
/*
1. 创建平台
2. 创建设备
3. 根据设备创建上下文
*/
cl_context CreateContext(cl_device_id* device) {
cl_int errNum;
cl_uint numPlateforms;
cl_platform_id firstPlatformId;
cl_context context = NULL;
errNum = clGetPlatformIDs(1, &firstPlatformId, &numPlateforms);
if (errNum != CL_SUCCESS || numPlateforms <= 0) {
printf("Failed to find any OpenCL platforms.\n");
return NULL;
}
errNum = clGetDeviceIDs(firstPlatformId, CL_DEVICE_TYPE_GPU, 1, device, NULL);
if (errNum != CL_SUCCESS) {
printf("There is no GPU , trying CPU...\n");
errNum = clGetDeviceIDs(firstPlatformId, CL_DEVICE_TYPE_CPU, 1, device, NULL);
}
if (errNum != CL_SUCCESS) {
printf("There is NO CPU or GPU\n");
return NULL;
}
context = clCreateContext(NULL, 1, device, NULL, NULL, &errNum);
if (errNum != CL_SUCCESS) {
printf("Create context error\n");
return NULL;
}
return context;
}
/*
@ 在上下文可用的第一个设备中创建命令队列
*/
cl_command_queue CreateCommandQueue(cl_context context, cl_device_id device) {
cl_int errNum;
cl_command_queue commandQueue = NULL;
//commandQueue = clCreateCommandQueue(context, device, 0, NULL);
// OpenCL 2.0 的用法
commandQueue = clCreateCommandQueueWithProperties(context, device, 0, NULL);
if (commandQueue == NULL) {
printf("Failed to create commandQueue for device 0\n");
return NULL;
}
return commandQueue;
}
char* ReadKernelSourceFile(const char* filename, size_t* length) {
FILE* file = NULL;
size_t sourceLenth;
char* sourceString;
int ret;
file = fopen(filename, "rb");
if (file == NULL) {
printf("%s at %d : Can't open %s \n", __FILE__, __LINE__ - 2, filename);
return NULL;
}
//重定位到文件末尾
fseek(file, 0, SEEK_END);
sourceLenth = ftell(file);
//重定位到文件开头
fseek(file, 0, SEEK_SET);
sourceString = (char*)malloc(sourceLenth + 1);
sourceString[0] = '\0';
ret = fread(sourceString, sourceLenth, 1, file);
if (ret == 0) {
printf("%s at %d : Cant't read source %s\n", __FILE__, __LINE__ - 2, filename);
return NULL;
}
fclose(file);
if (length != 0) {
*length = sourceLenth;
}
sourceString[sourceLenth] = '\0';
return sourceString;
}
cl_program CreateProgram(cl_context context, cl_device_id device, const char* filename) {
cl_int errNum;
cl_program program;
//记录大小的数据类型
size_t program_length;
char* const source = ReadKernelSourceFile(filename, &program_length);
program = clCreateProgramWithSource(context, 1, (const char**)& source, NULL, NULL);
if (program == NULL) {
printf("Failed to creae CL program from source.\n");
return NULL;
}
errNum = clBuildProgram(program, 0, NULL, NULL, NULL, NULL);
if (errNum != CL_SUCCESS) {
char buildLog[16384];
clGetProgramBuildInfo(program, device, CL_PROGRAM_BUILD_LOG, sizeof(buildLog), buildLog, NULL);
printf("Error in kernel : %s \n", buildLog);
clReleaseProgram(program);
return NULL;
}
return program;
}
/*
@ 创建内存对象
*/
bool CreateMemObjects(cl_context context, cl_mem memObjects[3], float* a, float* b) {
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * ARRAY_SIZE, a, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, sizeof(float) * ARRAY_SIZE, b, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE, sizeof(float) * ARRAY_SIZE, NULL, NULL);
if (memObjects[0] == NULL || memObjects[1] == NULL || memObjects[2] == NULL) {
printf("Error creating memeory objects.\n");
return false;
}
return true;
}
/*
@ 清楚OpenCL资源
*/
void CleanUp(cl_context context, cl_command_queue commandQueue, cl_program program, cl_kernel kernel, cl_mem memObjects[3]) {
for (int i = 0; i < 3; i++) {
if (memObjects[i] != 0) {
clReleaseMemObject(memObjects[i]);
}
}
if (commandQueue != 0) {
clReleaseCommandQueue(commandQueue);
}
if (kernel != 0) {
clReleaseKernel(kernel);
}
if (program != 0) {
clReleaseProgram(program);
}
if (context != 0) {
clReleaseContext(context);
}
}
/*main函数*/
int main(int argc, char** agrv) {
cl_context context = 0;
cl_command_queue commandQueue = 0;
cl_program program = 0;
cl_device_id device = 0;
cl_kernel kernel = 0;
cl_mem memObjects[3] = { 0,0,0 };
cl_int errNum;
//创建OpenCL上下文
context = CreateContext(&device);
if (context == NULL) {
printf("Failed to create OpenCL context\n");
return 1;
}
//获得OpenCL设备,并创建命令队列
commandQueue = CreateCommandQueue(context, device);
if (commandQueue == NULL) {
CleanUp(context, commandQueue, program, kernel, memObjects);
return 1;
}
//创建OpenCL程序
program = CreateProgram(context, device, "vecAdd.cl");
if (program == NULL) {
CleanUp(context, commandQueue, program, kernel, memObjects);
return 1;
}
kernel = clCreateKernel(program, "vector_add", NULL);
if (kernel == NULL) {
printf("Failed to create kernel\n");
CleanUp(context, commandQueue, program, kernel, memObjects);
return 1;
}
//创建OpenCL内存对象
float result[ARRAY_SIZE];
float a[ARRAY_SIZE];
float b[ARRAY_SIZE];
for (int i = 0; i < ARRAY_SIZE; i++) {
a[i] = (float)i;
b[i] = (float)(i * 2);
}
if (!CreateMemObjects(context, memObjects, a, b)) {
CleanUp(context, commandQueue, program, kernel, memObjects);
return 1;
}
//设置内核参数
errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &memObjects[0]);
errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObjects[1]);
errNum |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObjects[2]);
if (errNum != CL_SUCCESS) {
printf("Error setting kernel arguments.\n");
CleanUp(context, commandQueue, program, kernel, memObjects);
return 1;
}
size_t globalWorkSize[1] = { ARRAY_SIZE };
size_t localWorkSize[1] = { 1 };
//执行内核
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL, globalWorkSize, localWorkSize, 0, NULL, NULL);
if (errNum != CL_SUCCESS) {
printf("Error queueing kernel for execution\n");
CleanUp(context, commandQueue, program, kernel, memObjects);
return 1;
}
//将计算的结果拷贝到主机上
errNum = clEnqueueReadBuffer(commandQueue, memObjects[2], CL_TRUE, 0, ARRAY_SIZE * sizeof(float), result, 0, NULL, NULL);
if (errNum != CL_SUCCESS) {
printf("Error reading result buffer.\n");
CleanUp(context, commandQueue, program, kernel, memObjects);
return 1;
}
for (int i = 0; i < ARRAY_SIZE; i++) {
printf("i=%d:%f\n", i, result[i]);
}
printf("Executed program succesfully\n");
CleanUp(context, commandQueue, program, kernel, memObjects);
return 0;
}
vecAdd.cl
__kernel void vector_add(global const float *a, global const float *b, global float * result) {
int gid = get_global_id(0);
result[gid] = a[gid] + b[gid];
}
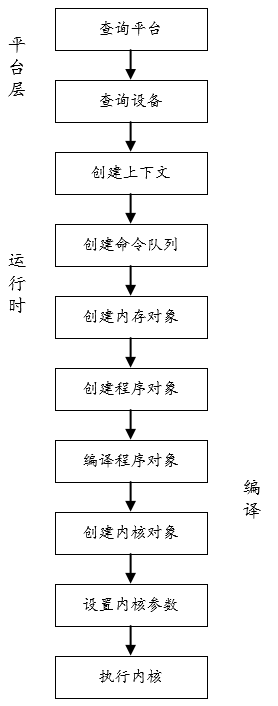
支持OpenCL的平台和设备很多,为了兼顾不同的设备,OpenCL程序的第一步就是确定OpenCL执行的平台,在确定平台之后,再确定执行OpenCL计算的设备。
确定设备后创建上下文、上下文包含了上一步查询的OpenCL计算的设备,以及接下来创建的内核、程序对象和内存对象。
创建上下文之后,需要创建命令队列,但一个OpenCL设备可以对应一个命令队列和一个OpenCL设备。例如,如果需要使用上下文中包含了两个计算设备时,为每个设备创建各自的命令队列。主机与OpenCL设备间的数据传输,执行内核等交互操作都是通过入队到命令队列中。命令队列中的每个命令交给OpenCL驱动或相应的硬件单元去执行。
由于在运行时才知道OpenCL设备信息,所在以OpenCL主机算程序中读取内核源码并创建程序对象。根据OpenCL设备编译构建程序对象,最后创建内核对象。通过这三部操作,把OpenCL 设备上执行的内核代码编译完成。
对于OpenCL设备上执行的内核函数需要完成输入参数,在主机端调用设备内核参数函数,除此之外,还需要设备在设备上用于执行的工作组和工作项的参数。
OpenCL程序的第一步就是选择OpenCL平台。OpenCL平台指的是OpenCL设备和OpenCL框架的组合。一个异构计算机可以同时存在多个OpenCL平台。
#include
#include
#include
#include
int main() {
cl_platform_id* platform;
cl_uint num_platform;
cl_int err;
err = clGetPlatformIDs(0, NULL, &num_platform);
platform = (cl_platform_id*)malloc(sizeof(cl_platform_id) * num_platform);
err = clGetPlatformIDs(num_platform, platform, NULL);
for (int i = 0; i < num_platform; i++) {
printf("\nPlatform %d information\n", i);
size_t size;
err = clGetPlatformInfo(platform[i], CL_PLATFORM_NAME, 0, NULL, &size);
char* PName = (char*)malloc(size);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_NAME, size, PName, NULL);
printf("CL_PLATFORM_NAME: %s\n", PName);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_VENDOR, 0, NULL, &size);
char* PVendor = (char*)malloc(size);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_VENDOR, size, PVendor, NULL);
printf("CL_PLATFORM_VENDOR: %s\n", PVendor);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_VERSION, 0, NULL, &size);
char* PVersion = (char*)malloc(size);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_VERSION, size, PVersion, NULL);
printf("CL_PLATFORM_VERSION: %s\n", PVersion);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_PROFILE, 0, NULL, &size);
char* PProfile = (char*)malloc(size);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_PROFILE, size, PProfile, NULL);
printf("CL_PLATFORM_PROFILE: %s\n", PProfile);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_EXTENSIONS, 0, NULL, &size);
char* PExten = (char*)malloc(size);
err = clGetPlatformInfo(platform[i], CL_PLATFORM_EXTENSIONS, size, PExten, NULL);
printf("CL_PLATFORM_EXTENSIONS: %s\n", PExten);
free(PName);
free(PVendor);
free(PVersion);
free(PProfile);
free(PExten);
}
}
可以查询本机上的设备。
Platform 0 information
CL_PLATFORM_NAME: Intel(R) OpenCL
CL_PLATFORM_VENDOR: Intel(R) Corporation
CL_PLATFORM_VERSION: OpenCL 2.0
CL_PLATFORM_PROFILE: FULL_PROFILE
CL_PLATFORM_EXTENSIONS: cl_intel_dx9_media_sharing cl_khr_3d_image_writes cl_khr_byte_addressable_store cl_khr_d3d11_sharing cl_khr_depth_images cl_khr_dx9_media_sharing cl_khr_gl_sharing cl_khr_global_int32_base_atomics cl_khr_global_int32_extended_atomics cl_khr_icd cl_khr_image2d_from_buffer cl_khr_local_int32_base_atomics cl_khr_local_int32_extended_atomics cl_khr_spir
Platform 1 information
CL_PLATFORM_NAME: AMD Accelerated Parallel Processing
CL_PLATFORM_VENDOR: Advanced Micro Devices, Inc.
CL_PLATFORM_VERSION: OpenCL 2.0 AMD-APP (2117.8)
CL_PLATFORM_PROFILE: FULL_PROFILE
CL_PLATFORM_EXTENSIONS: cl_khr_icd cl_khr_d3d10_sharing cl_khr_d3d11_sharing cl_khr_dx9_media_sharing cl_amd_event_callback cl_amd_offline_devices
OpenCL平台信息参数
| cl_platform_info | 返回类型 | 描述 |
|---|---|---|
| CL_PLATFORM_PROFILE | char[] | 识别平台支持FULL_PROFILE还是EMBEDDED_PROFILE |
| CL_PLATFORM_VERSION | char[] | 返回平台支持的最大OpenCL版本 |
| CL_PLATFORM_NAME | char[] | 返回OpenCL平台名称 |
| CL_PLATFORM_VENDOR | char[] | 返回OpenCL平台开发商名称 |
| CL_PLATFORM_EXTENSIONS | char[] | 返回OpenCL平台支持的扩展列表 |
作者:绝尘花遗落