NLP词向量介绍
全文均为笔者的理解,不权威也不一定准确,如有错误欢迎指正。
NLP的核心问题,就是学习不同语境下的语义表示,所谓的语义表示呢,就是以量化的方式来表示一个单词,即我们今天要说的——词向量。词向量作为一种预训练模型在NLP领域应用非常广泛,词向量可以看作是用来表达词的语义。在这个领域,一个重要的挑战为一个单词在不同的上下文里有可能表示不一样的语义,该如何解决这个问题呢?那就是加入了上下文信息来区分同一词的多个的意义。而词向量又是如何发展为能进行一词多义的语义消歧的呢,那就一起看看词向量的发展之路吧!
首先就是one-hot独热编码,它在单词对应位置为1,其他位置为0.如“我/今天/写/博客。”,其中,我对应的就是[1,0,0,0],博客对应[0,0,0,1]。这种方式理解起来很容易,但显然,这种方式并不能表示单词之间的语义相似度。
因此,就想到了改进这种词向量,把稀疏向量改为稠密向量,即把0的地方改为不是0的数字,如我的表示可能变为[0.97,0.01,0.01,0.01],这就是分布式表示。
说到分布式表示,就要先祭上这张经典图了。
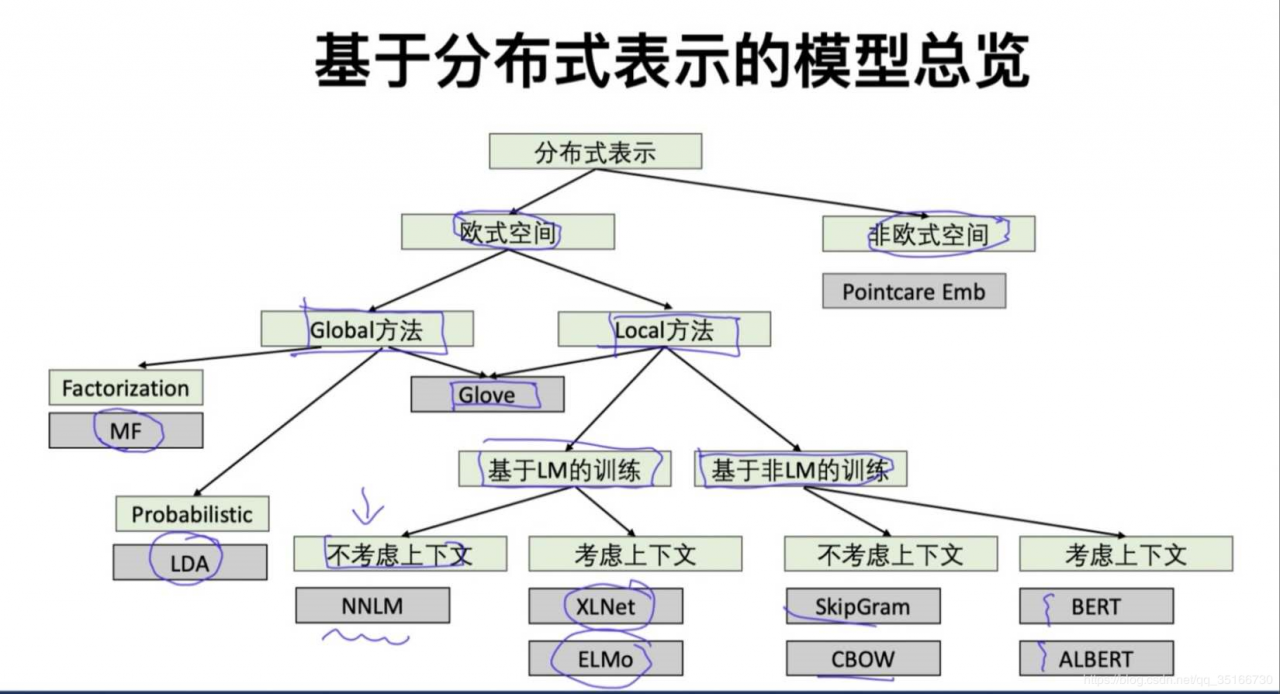
下面按照时间线分别介绍几个模型,顺带解释几个常见问题。
2013.1—word2vec
word2vec中包含上图中的skip-gram和CBOW两个模型。两个模型区别在于CBOW是使用上下文推目标词,而skipgram则是使用目标词预测上下文。也正因为这个区别,基于Skip-gram的word2vec在低频词汇相比基于CBOW的更有效。(在反向传播的时候,skip-gram梯度更新时,context中k个词每一个都会对目标词的梯度更新,一共更新k次,但是CBOW中,目标词的更新反向传播更新context时是只进行一次梯度更新,平均分配到每一个context的词上。也就是说,在skip-gram当中,每个词都要收到周围的词的影响,每个词在作为中心词的时候,都要进行K次的预测、调整。因此,当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。尽管CBOW从另外一个角度来说,某个词也是会受到多次周围词的影响(多次将其包含在内的窗口移动)来进行词向量的调整,但是他的调整是跟周围的词一起调整的,grad的值会平均分到这些词上,相当于该生僻词没有受到专门的训练,它只是沾了周围词的光而已。一句话说白了,就是调整的次数的问题。)
同时,word2vec中有两个训练策略,分别是Hierarchical Softmax和Negative Sampling。
层次softmax,它的输出层是一棵哈夫曼树,其中叶子结点是词表中的所有词,权重是词频。约定左子树的权重要大于等于右子树的权重,且左1右0。使用哈夫曼树的好处在于高频词靠近树的根,查找时间短,且二叉树可以减少计算量,使时间复杂度变为logV,而不是V。
负采样,就是用在字典中随机选择一个词作为正样本中context的目标词。
2014.1—GloVe
GloVe是基于词与词之间的共现矩阵构造的词向量模型,其实就是加入了全局信息,可以看做是更换来了目标函数和权重函数的W2V。因为是global,所以它训练时收敛更快,且更容易并行化。然而GloVe存在一个缺陷:它训练出的词向量加上一个常数向量后仍旧是该损失函数的解,也就是说在所有词向量上都加上一个很大的常数向量对它来说并没有影响,然而加了之后的词向量会变得非常接近,从而失去了词向量区分词的功能。
2016.7—Fasttext
Fasttext与CBOW类似,不同的是它预测目标是类标签,而CBOW预测目标词,同样都采用层次softmax来对输出的分类标签建立哈夫曼树。它考虑词序特征,引入了N-gram(Uni-gram指无条件概率,不论什么词序概率结果都一样,即不考虑顺序;Bi-gram在一阶马尔科夫假设基础上计算概率,考虑了前后一个上下文词;N-gram则是在N-1阶马尔科夫假设上计算概率,考虑了前后N-1个上下文词)。另一个特点在于引入了subword来处理长词,处理未登录词问题(比如对于‘信息工程学院来说’subword就是‘信息’‘工程’这样的。未登录词指的是没有被收录在词表中,但必须切分出来的词,如一些专有名词,缩写词等)。
2017.6—Transformer
Transformer是一个seq2seq模型,它使用Attention机制代替RNN来获取信息。这是因为RNN本身存在会梯度消失的弊端,虽然后来的LSTM和GRU一定程度上缓解了梯度消失,但并没有解决这个问题。Transformer本身的结构和算法,还是建议大家自己阅读论文《Attention is all you need》去仔细了解,对于一些弄不懂的问题,可以阅读https://jalammar.github.io/illustrated-transformer/来寻找答案。由于上述博客讲的很好,把所有的细节都讲清楚了,所以这里就不再搬运累述了。
2018.2—ELMo
上述的word2vec,glove和fasttext都是静态词向量,也就是说一经训练,每个词对应的词向量就不再变化,就是固定的了。而ELMo则是动态的,它会在(利用语言模型)预训练时给多义词一个基础向量,然后在具体句子语境中来调整这个向量使得同一单词不同语义具有不同向量。也就是说,动态词向量可以区分一词多义。ELMo的输入是字母而非单词,因此,它可以利用字词单元的组合来表示词,所以也一定程度上解决了OOV的问题。
ELMo的结构是一层CNN后接biLSTM,CNN用来初始化char-level向量。值得注意的是,这里的双向LSTM所说的双向其实是伪双向的(ELMo中的双向只是简单的两个方向相反的LSTM的拼接,如1234和4321,而非真正的双向。像XLnet才是真正的双向,它考虑了所有可能的排列组合方式,不只有1234和4321,也有2143,2341等)。因为ELMo是基于LM训练的,先简单说一下语言模型LM。LM本质就是用来判断一句话从语法上是否通顺,其实就是看怎么排列下计算出的概率最高就是怎么排最合适。评价使用Perplexity(就是我们常说的困惑度),涉及到链式法则,马尔科夫假设,N-gram等基础知识,还涉及到一些平滑方法(像拉普拉斯平滑,interpolation等)。
ELMo词向量的表示是2L+1个向量的加权平均,具体如下:

2018.10—BERT
Bert模型的诞生可谓是NLP的里程碑,bert已经在一些任务上超越人类表现,也造成了大家看到的刚过去的2019年是bert的一年。其实bert的理论基础很简单,就是双向的Transformer,且只有encoder没有decoder(也可能是因为没有decoder,所以bert在生成任务上表现不佳)。要学习bert的话只要搞懂了Transformer和bert的两个训练策略MLM和NSP即可。
MLM呢,就是将一个词80%概率替换为mask,10%不变,10%随机替换。(为什么是80,10,10呢?实验出来的超参数而已),这里涉及到两个参数,max_prediction_per_eq为每个句子mask掉的最大数量,do_whole_word_mask为是否mask整词(相对subword来说),方式类似于CBOW中使用上下文来预测目标词,也正因为mask所以bert可以不用于下游任务只用训练好的词向量。
NSP相对来说比较简单,就是预测两个句子是否为相连的两个句子。
在bert中,这两个任务是同时进行的。
这里插入一点题外话,在类似于bert-large模型这样的多层模型中,每一层的贡献是不同的,低层比高层具有更大的不变性,可以在不同任务进行迁移。因此bert使用pre-training + fine-turning的方法可以在绝大多数任务上表现良好。原因就是低层编码更多的本地语法,而较高的层捕获更复杂的语义(low layers of BERT encode more local syntax, while high layers capture more complex semantics)。
Bert之后一系列基于bert改进的模型在不断刷新各任务的最佳表现,像roberta,xlnet,albert等。有时间了再继续。
作者:夏离